- Published on
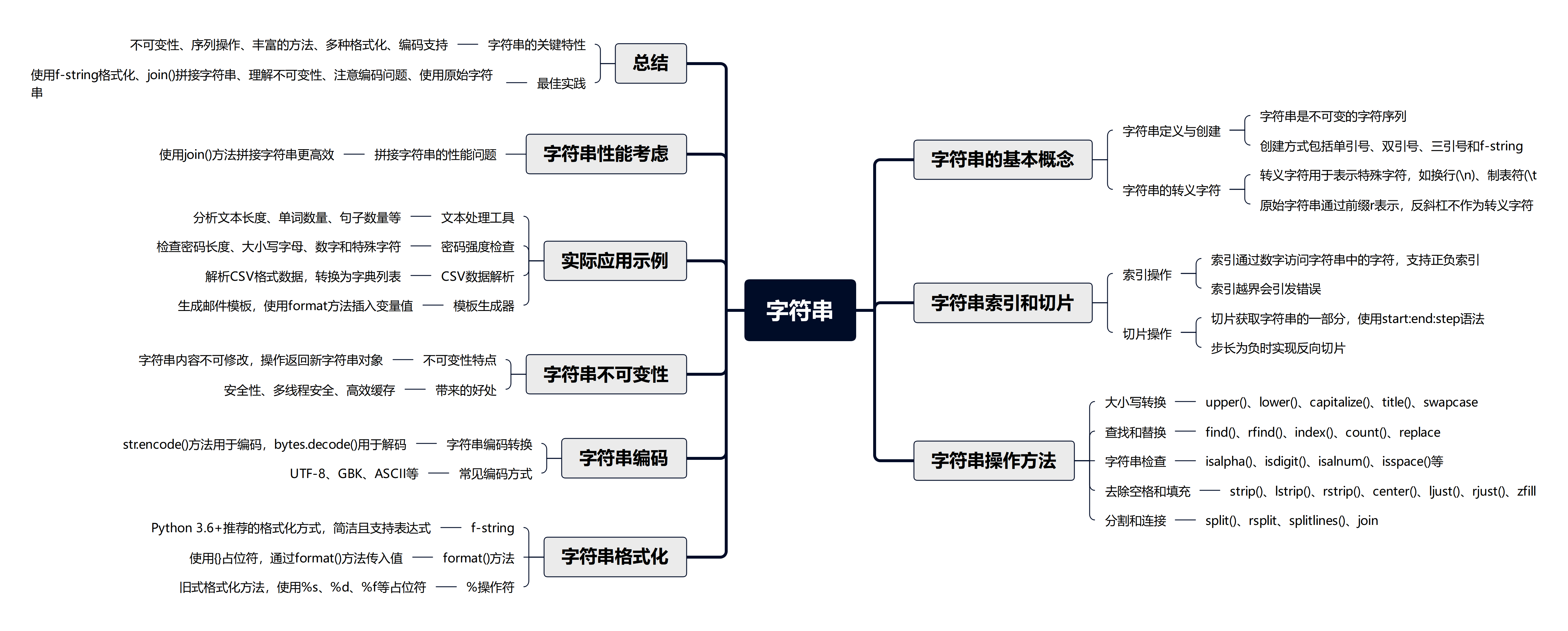
2.6.字符串类型
- Authors

- Name
- xiaobai
1.字符串的基本概念
字符串是由字符组成的不可变序列,用于表示文本数据。
# 字符串的创建方式
str1 = '单引号字符串'
str2 = "双引号字符串"
str3 = '''三引号可以
创建多行
字符串'''
str4 = """同样支持
多行文本"""
print(str1)
print(str2)
print(str3)
print(str4)
print(f"类型: {type(str1)}") # <class 'str'>
2.字符串的转义字符
转义字符用于在字符串中表示一些特殊的字符,比如换行、制表符、引号等。常见的转义字符有:
\n:表示换行符\t:表示制表符(Tab)\\:表示反斜杠自身\':表示单引号\":表示双引号\uXXXX:表示Unicode字符
在字符串中,如果需要让反斜杠不作为转义符使用,可以在字符串前加 r,表示原始字符串(raw string),这样所有的反斜杠都不会被转义。
示例:
# 常见转义字符
print("转义字符演示:")
print("换行: Hello\\nWorld") # Hello\nWorld
print("实际换行: Hello\nWorld") # 实际换行效果
print("制表符: Name:\\tAlice") # Name: Alice
print("实际制表符: Name:\tAlice") # Name: Alice
print("反斜杠: 路径: C:\\\\Users") # 路径: C:\\Users
print('单引号: I\'m Python') # I'm Python
print("双引号: He said: \"Hello\"") # He said: "Hello"
# 原始字符串 (取消转义)
raw_str = r"原始字符串: \n\t不会转义"
print(raw_str) # 原始字符串: \n\t不会转义
# Unicode转义
unicode_str = "\u4e2d\u6587" # 中文
print(f"Unicode转义: {unicode_str}")
## 字符串索引和切片
### 索引操作
字符串中的每个字符都可以通过索引(下标)来访问。索引从0开始,也支持负数索引(-1表示最后一个字符,-2表示倒数第二个,以此类推)。
切片(slice)可以用来获取字符串中的一部分,语法为 `str[start:end:step]`,其中:
- `start`:起始索引(包含该位置,默认为0)
- `end`:结束索引(不包含该位置,默认为字符串长度)
- `step`:步长(默认为1,可以为负数实现反向切片)
索引不会改变原字符串,而是返回新的字符串片段。
```python
text = "Hello Python"
print("索引操作:")
print(f"字符串: '{text}'")
print(f"长度: {len(text)}")
print(f"正索引 - text[0]: '{text[0]}'") # H
print(f"正索引 - text[6]: '{text[6]}'") # P
print(f"负索引 - text[-1]: '{text[-1]}'") # n
print(f"负索引 - text[-6]: '{text[-6]}'") # P
# 索引越界会报错
try:
print(text[20])
except IndexError as e:
print(f"索引错误: {e}")
```
### 2.1.切片操作
切片(slice)可以用来获取字符串中的一部分,语法为 `str[start:end:step]`,其中:
- `start`:起始索引(包含该位置,默认为0)
- `end`:结束索引(不包含该位置,默认为字符串长度)
- `step`:步长(默认为1,可以为负数实现反向切片)
切片不会改变原字符串,而是返回新的字符串片段。
```python
text = "Hello Python Programming"
print("切片操作:")
print(f"原始字符串: '{text}'")
print(f"text[0:5]: '{text[0:5]}'") # Hello
print(f"text[6:12]: '{text[6:12]}'") # Python
print(f"text[:5]: '{text[:5]}'") # Hello (从开始到索引5)
print(f"text[13:]: '{text[13:]}'") # Programming (从索引13到结束)
print(f"text[-11:]: '{text[-11:]}'") # Programming (从倒数第11个到结束)
# 步长切片
print(f"text[::2]: '{text[::2]}'") # HloPto rgamn (步长为2)
print(f"text[1::2]: '{text[1::2]}'") # el yhnPormig (从索引1开始,步长为2)
print(f"text[::-1]: '{text[::-1]}'") # gnimmargorP nohtyP olleH (反转)
# 复杂的切片
print(f"text[0:10:2]: '{text[0:10:2]}'") # HloPt (0到10,步长2)
```
## 3.字符串操作方法
字符串常用操作方法包括大小写转换、查找、替换、分割、连接、去除空白、内容判断等。
这些方法不会改变原字符串,而是返回新字符串或结果。
1. 查找和替换
2. 分割与连接
- split(sep):按分隔符切割为列表
- rsplit(sep):从右侧切割
- join(iterable):用指定分隔符连接序列
1. 去除空白
- strip():去除两端空白
- lstrip():去除左侧空白
- rstrip():去除右侧空白
1. 内容判断
- isdigit():是否全为数字
- isalpha():是否全为字母
- isalnum():是否全为字母或数字
- isupper()/islower():是否全为大写/小写
- startswith()/endswith():是否以指定子串开头/结尾
### 3.1.大小写转换
- upper():全部转为大写
- lower():全部转为小写
- capitalize():首字母大写,其余小写
- title():每个单词首字母大写
- swapcase():大小写互换
```python
text = "hello World of Python"
print("大小写转换:")
print(f"原始: '{text}'") # hello World of Python
print(f"大写: '{text.upper()}'") # HELLO WORLD OF PYTHON
print(f"小写: '{text.lower()}'") # hello world of python
print(f"首字母大写: '{text.capitalize()}'") # Hello world of python
print(f"每个单词首字母大写: '{text.title()}'") # Hello World Of Python
print(f"大小写交换: '{text.swapcase()}'") # HELLO wORLD OF pYTHON
# 检查大小写
print(f"是否全大写: {text.isupper()}") # False
print(f"是否全小写: {text.islower()}") # False
print(f"HELLO是否全大写: {'HELLO'.isupper()}") # True
```
### 3.2.查找和替换
- find(sub):查找子串,返回索引,找不到返回-1
- rfind(sub):从右侧查找
- index(sub):查找子串,找不到抛异常
- count(sub):统计子串出现次数
- replace(old, new, count):替换子串
```python
text = "Hello World, Welcome to Python World"
print("查找和替换:")
print(f"原始: '{text}'") # Hello World, Welcome to Python World
print(f"查找'World'位置: {text.find('World')}") # 6
print(f"查找'Python'位置: {text.find('Python')}") # 24
print(f"查找不存在的: {text.find('Java')}") # -1
print(f"从右边查找: {text.rfind('World')}") # 31
print(f"索引查找: {text.index('World')}") # 6
# print(text.index('Java')) # 会抛出ValueError
print(f"出现次数: {text.count('World')}") # 2
print(f"出现次数: {text.count('o')}") # 6
# 替换操作
print(f"替换: '{text.replace('World', 'Earth')}'") # Hello Earth, Welcome to Python Earth
print(f"替换一次: '{text.replace('World', 'Earth', 1)}'") # Hello Earth, Welcome to Python World
```
### 3.3.字符串检查
- isalpha():是否全为字母
- isdigit():是否全为数字
- isalnum():是否全为字母或数字
- isspace():是否全为空白字符(如空格、制表符等)
- istitle():是否为标题格式(每个单词首字母大写)
- isupper():是否全为大写字母
- islower():是否全为小写字母
- startswith(): 是否以指定子串开头
- endswith(): 是否以指定子串结尾
```python
def string_checks():
"""字符串内容检查"""
test_cases = [
"Hello123", # 字母数字
"12345", # 纯数字
"Hello", # 纯字母
" ", # 纯空格
"HELLO", # 全大写
"hello", # 全小写
"Hello World", # 包含空格
"", # 空字符串
]
print("字符串检查:")
for s in test_cases:
print(f"'{s:12}': 字母={s.isalpha():5} 数字={s.isdigit():5} "
f"字母数字={s.isalnum():5} 空格={s.isspace():5} "
f"标题={s.istitle():5}")
string_checks()
# 开头和结尾检查
filename = "document.pdf"
url = "https://www.example.com"
print(f"\n文件'{filename}' 是PDF吗? {filename.endswith('.pdf')}")
print(f"URL'{url}' 以https开头吗? {url.startswith('https')}")
```
### 3.4.去除空格和填充
去除空白字符和字符串填充方法用于格式化字符串内容。
- strip():去除字符串两端的空白字符(包括空格、制表符、换行等)
- lstrip():去除左侧空白
- rstrip():去除右侧空白-
- strip([chars]) 也可以去除指定字符(如'*'、'0'等)-
- center(width, fillchar):内容居中,两侧用fillchar填充
- ljust(width, fillchar):内容左对齐,右侧用fillchar填充
- rjust(width, fillchar):内容右对齐,左侧用fillchar填充
- zfill(width):左侧用0填充,常用于数字字符串
```python
# 定义一个包含前后空格的字符串
text = " Hello World "
# 输出提示信息“去除空格:”
print("去除空格:")
# 输出原始字符串,使用竖线标记边界
print(f"原始: |{text}|")
# 去除字符串两端的空格并输出
print(f"去两端空格: |{text.strip()}|")
# 去除字符串左端的空格并输出
print(f"去左端空格: |{text.lstrip()}|")
# 去除字符串右端的空格并输出
print(f"去右端空格: |{text.rstrip()}|")
# 定义一个包含特定字符(*)的字符串
text2 = "***Hello World***"
# 去除字符串两端的*字符并输出
print(f"去特定字符: |{text2.strip('*')}|")
# 定义一个字符串用于演示填充
text3 = "Hello"
# 输出提示信息“字符串填充:”
print(f"\n字符串填充:")
# 将字符串居中填充到20个字符宽度并输出
print(f"居中: |{text3.center(20)}|")
# 将字符串左对齐填充到20个字符宽度并输出
print(f"左对齐: |{text3.ljust(20)}|")
# 将字符串右对齐填充到20个字符宽度并输出
print(f"右对齐: |{text3.rjust(20)}|")
# 使用0在左侧填充字符串到10个字符宽度并输出
print(f"零填充: |{text3.zfill(10)}|") # 00000Hello
```
### 3.5.分割和连接
- `split(sep=None, maxsplit=-1)`:将字符串按指定分隔符分割成列表,sep为分隔符,maxsplit为分割次数,默认全部分割。
- `rsplit(sep=None, maxsplit=-1)`:从右侧开始分割,其他用法同split。
- `splitlines(keepends=False)`:按行分割字符串,返回每一行组成的列表,`keepends`为`True`时保留换行符。
- `join(iterable)`:用指定字符串连接可迭代对象中的元素,生成一个新的字符串。
```python
# 分割字符串
csv_data = "apple,banana,orange,grape"
sentence = "Hello World of Python"
lines = "第一行\n第二行\n第三行"
print("分割操作:")
print(f"CSV分割: {csv_data.split(',')}") # ['apple', 'banana', 'orange', 'grape']
print(f"句子分割: {sentence.split()}") # ['Hello', 'World', 'of', 'Python']
print(f"限制分割: {sentence.split(' ', 2)}") # ['Hello', 'World', 'of Python']
print(f"行分割: {lines.splitlines()}") # ['第一行', '第二行', '第三行']
print(f"从右边分割: {sentence.rsplit(' ', 2)}") # ['Hello World', 'of', 'Python']
# 连接字符串
fruits = ['apple', 'banana', 'orange']
print(f"连接: {', '.join(fruits)}") # apple, banana, orange
print(f"连接: {' - '.join(fruits)}") # apple - banana - orange
```
## 4.字符串格式化
字符串格式化是将变量或表达式的值以特定格式嵌入到字符串中的方法。Python常用的字符串格式化方式有三种:
- f-string(格式化字符串字面量,Python 3.6+ 推荐)
- format() 方法
- % 操作符(旧式格式化)
这三种方式都可以实现字符串的插值和格式控制,推荐优先使用f-string,其次是format(),%方式主要用于兼容老代码。
### 4.1.f-string
- 语法:在字符串前加f,花括号 `{}` 中放变量或表达式。
- 例:`f"姓名: {name}, 年龄: {age}"`
- 优点:简洁、支持表达式、易读。
```python
name = "Alice"
age = 25
salary = 5000.50
print("f-string格式化:")
print(f"姓名: {name}, 年龄: {age}")
print(f"薪资: ${salary:.2f}")
print(f"明年年龄: {age + 1}")
print(f"名字大写: {name.upper()}")
# 表达式和函数调用
items = ['apple', 'banana', 'orange']
print(f"物品数量: {len(items)}")
print(f"第二个物品: {items[1]}")
# 格式化对齐
number = 42
print(f"右对齐: |{number:>10}|")
print(f"左对齐: |{number:<10}|")
print(f"居中对齐: |{number:^10}|")
print(f"零填充: |{number:010}|")
```
### 4.2.format() 方法
- 语法:字符串中用 `{}` 占位,调用 `format()` 传入对应的值。
- 例:`"{} is {} years old".format(name, age)`
- 支持位置参数、关键字参数、格式控制。
```python
# format() 方法
name = "Bob"
age = 30
print("format() 方法:")
print("{} is {} years old".format(name, age))
print("{0} is {1} years old. Hello {0}!".format(name, age))
print("{name} is {age} years old".format(name=name, age=age))
# 数字格式化
pi = 3.14159
print("PI = {:.2f}".format(pi))
print("二进制: {:b}".format(10))
print("十六进制: {:x}".format(255))
```
### 4.3.% 操作符
- 语法:字符串中用%占位符,后面用%传入元组或字典。
- 例:"%s is %d years old" % (name, age)
- 占位符有%s(字符串)、%d(整数)、%f(浮点数)等。
```python
# % 操作符 (传统方法)
name = "Charlie"
age = 35
print("% 格式化:")
print("%s is %d years old" % (name, age))
print("PI = %.3f" % 3.14159)
```
## 5.字符串编码
字符串编码是指将字符串(字符序列)转换为字节序列的过程,常见编码有UTF-8、GBK等。
解码则是将字节序列还原为字符串。
在Python中,str.encode()方法用于编码,bytes.decode()方法用于解码。
常见编码方式:
- UTF-8:通用、支持所有字符,推荐使用。
- GBK:中文Windows常用,兼容简体中文。
- ASCII:仅支持英文和部分符号。
```python
text = "Hello 世界 🐍"
print(f"原始字符串: {text}")
# 编码为字节
utf8_bytes = text.encode('utf-8')
gbk_bytes = text.encode('gbk', errors='ignore')
print(f"UTF-8字节: {utf8_bytes}")
print(f"GBK字节: {gbk_bytes}")
# 解码回字符串
decoded_utf8 = utf8_bytes.decode('utf-8')
decoded_gbk = gbk_bytes.decode('gbk')
print(f"UTF-8解码: {decoded_utf8}")
print(f"GBK解码: {decoded_gbk}")
# 字符和编码点
for char in "ABC世界":
print(f"字符 '{char}' -> Unicode码点: {ord(char):04X}")
```
## 6.字符串不可变性
字符串在Python中是不可变对象(immutable),这意味着一旦创建,字符串的内容就不能被直接修改。所有对字符串的操作(如拼接、替换、大小写转换等)都会返回一个新的字符串对象,原有字符串保持不变。
这种不可变性带来如下特点和好处:
- **安全性**:字符串作为键(key)用于字典等哈希结构时,内容不会被意外更改,保证哈希值稳定。
- **多线程安全**:多个线程可以安全地共享字符串对象,无需担心内容被修改。
- **高效缓存**:Python可以对相同内容的字符串进行内部缓存和重用,提升性能。
**注意**:虽然不能直接修改字符串的某个字符,但可以通过切片、拼接等方式生成新的字符串。
```python
original = "Hello"
print(f"原始字符串: {original}, id: {id(original)}")
# 看起来是修改,实际上是创建了新字符串
modified = original + " World"
print(f"修改后: {modified}, id: {id(modified)}")
print(f"原始字符串未改变: {original}")
# 尝试直接修改会报错
try:
original[0] = 'h' # TypeError
except TypeError as e:
print(f"错误: {e}")
# 可以通过重新赋值来"改变"
original = "New Value"
print(f"重新赋值后: {original}, id: {id(original)}")
```
## 7.以下内容不用看,Python全部学完后再看
## 8.实际应用示例
### 8.1.示例1:文本处理工具
```python
def text_processor(text):
"""文本处理工具"""
print("文本分析报告:")
print("=" * 40)
print(f"原始文本: {text}")
print(f"文本长度: {len(text)} 字符")
print(f"单词数量: {len(text.split())}")
print(f"句子数量: {text.count('.') + text.count('!') + text.count('?')}")
print(f"大写字母: {sum(1 for c in text if c.isupper())}")
print(f"小写字母: {sum(1 for c in text if c.islower())}")
print(f"数字数量: {sum(1 for c in text if c.isdigit())}")
print(f"空格数量: {text.count(' ')}")
# 最常用的5个字符
from collections import Counter
char_count = Counter(text.replace(' ', ''))
print(f"最常用字符: {char_count.most_common(5)}")
sample_text = "Hello World! This is a sample text. It contains 123 numbers and some punctuation!"
text_processor(sample_text)
```
### 8.2.示例2:密码强度检查
```python
def password_strength_checker(password):
"""密码强度检查器"""
strength = 0
feedback = []
# 长度检查
if len(password) >= 8:
strength += 1
else:
feedback.append("密码至少8位")
# 大写字母检查
if any(c.isupper() for c in password):
strength += 1
else:
feedback.append("包含大写字母")
# 小写字母检查
if any(c.islower() for c in password):
strength += 1
else:
feedback.append("包含小写字母")
# 数字检查
if any(c.isdigit() for c in password):
strength += 1
else:
feedback.append("包含数字")
# 特殊字符检查
special_chars = "!@#$%^&*()_+-=[]{}|;:,.<>?"
if any(c in special_chars for c in password):
strength += 1
else:
feedback.append("包含特殊字符")
# 强度评级
if strength == 5:
rating = "非常强"
elif strength >= 3:
rating = "中等"
else:
rating = "弱"
return {
'strength': strength,
'rating': rating,
'feedback': feedback,
'length': len(password)
}
# 测试密码
passwords = ["abc", "password", "Password123", "StrongP@ssw0rd!"]
print("密码强度检查:")
for pwd in passwords:
result = password_strength_checker(pwd)
print(f"密码: {pwd:15} -> 强度: {result['strength']}/5 ({result['rating']})")
if result['feedback']:
print(f" 改进建议: {', '.join(result['feedback'])}")
```
- any() 是Python内置函数,用于判断可迭代对象中是否有元素为True,只要有一个为True就返回True,否则返回False。
### 8.3.示例3:CSV数据解析
```python
# 定义一个函数用于解析CSV格式的数据
def parse_csv_data(csv_string):
# 去除字符串首尾空白,并按换行符分割成多行
lines = csv_string.strip().split('\n')
# 取第一行作为表头,并按逗号分割
headers = lines[0].split(',')
# 打印提示信息,表示开始解析CSV数据
print("CSV数据解析:")
# 打印表头信息
print(f"列头: {headers}")
# 打印分隔线
print("-" * 50)
# 创建一个空列表用于存储解析后的数据
data = []
# 遍历每一行数据(从第二行开始),i为行号
for i, line in enumerate(lines[1:], 1):
# 按逗号分割每一行,得到每列的值
values = line.split(',')
# 将表头和每行的值组合成字典
row_data = dict(zip(headers, values))
# 将字典添加到数据列表中
data.append(row_data)
# 打印当前行的解析结果
print(f"行 {i}: {row_data}")
# 返回解析后的数据列表
return data
# 定义CSV格式的字符串数据
csv_data = """name,age,city,salary
Alice,28,New York,50000
Bob,32,San Francisco,75000
Charlie,25,Chicago,45000
Diana,29,Boston,60000"""
# 调用解析函数并保存结果
parsed_data = parse_csv_data(csv_data)
```
- list:有序元素的集合,用于存储多个值。
- enumerate:为可迭代对象添加索引,常用于循环时获取元素和下标。
- zip:将多个可迭代对象“打包”成元组对,常用于并行遍历。
### 8.4.示例4:模板生成器
```python
def email_template_generator(name, product, price, discount=0):
"""邮件模板生成器"""
template = """
尊敬的 {name},
感谢您购买 {product}!
订单详情:
- 产品: {product}
- 原价: ${original_price:.2f}
- 折扣: {discount_percent}%
- 实付: ${final_price:.2f}
如有任何问题,请随时联系我们。
祝好,
客服团队
"""
original_price = price
discount_amount = price * discount / 100
final_price = price - discount_amount
email_content = template.format(
name=name,
product=product,
original_price=original_price,
discount_percent=discount,
final_price=final_price
)
return email_content.strip()
# 生成邮件
email = email_template_generator("张三", "Python编程书", 59.99, 10)
print("生成的邮件:")
print(email)
```
## 9.字符串性能考虑
```python
# 不推荐的方式:频繁拼接
import time
start_time = time.time()
result = ""
for i in range(10000):
result += str(i) # 每次拼接都创建新字符串
end_time = time.time()
print(f"直接拼接耗时: {end_time - start_time:.4f}秒")
# 推荐的方式:使用列表join
start_time = time.time()
parts = []
for i in range(10000):
parts.append(str(i))
result = "".join(parts)
end_time = time.time()
print(f"join方式耗时: {end_time - start_time:.4f}秒")
```
## 10.总结
### 10.1.字符串的关键特性
1. **不可变性**:字符串创建后不能修改
2. **序列操作**:支持索引、切片等序列操作
3. **丰富的方法**:大量内置方法处理文本
4. **多种格式化**:f-string、format()、% 格式化
5. **编码支持**:支持多种字符编码
### 10.2.最佳实践
- 使用f-string进行字符串格式化
- 大量字符串拼接时使用join()
- 理解字符串的不可变性
- 注意字符编码问题
- 使用原始字符串处理路径和正则表达式