- Published on
1.基础篇-前端面试题汇总
- Authors

- Name
- xiaobai
基础篇
前端基础题型,快速过一遍即可

一、HTML、HTTP、WEB综合问题
1 前端需要注意哪些SEO
- 合理的
title、description、keywords:搜索引擎对这些标签的权重逐渐减小。在title中,强调重点即可,重要关键词不要超过2次,并且要靠前。每个页面的title应该有所不同。description应该高度概括页面内容,长度适当,避免过度堆砌关键词。每个页面的description也应该有所不同。keywords标签应列举出重要关键词即可。- 针对
title标签,可以使用重要关键词、品牌词或描述页面内容的短语。确保标题简洁、准确地概括页面的主题,并吸引用户点击。 - 在编写
description标签时,应尽量使用简洁、具有吸引力的语句来概括页面的内容,吸引用户点击搜索结果。避免堆砌关键词,以自然流畅的方式描述页面 keywords标签已经不再是搜索引擎排名的重要因素,但仍然可以列举出与页面内容相关的几个重要关键词,以便搜索引擎了解页面的主题。
- 针对
- 语义化的
HTML代码,符合W3C规范:使用语义化的HTML代码可以让搜索引擎更容易理解网页的结构和内容。遵循W3C规范可以提高网页的可读性和可访问性,对SEO也有好处。 - 重要内容
HTML代码放在最前:搜索引擎抓取HTML的顺序是从上到下,有些搜索引擎对抓取长度有限制。因此,将重要的内容放在HTML的前面,确保重要内容一定会被抓取。 - 重要内容不要用
js输出:爬虫不会执行JavaScript,所以重要的内容不应该依赖于通过JavaScript动态生成。确保重要内容在HTML中静态存在。 - 少用
iframe:搜索引擎通常不会抓取iframe中的内容,因此应该尽量减少iframe的使用,特别是对于重要的内容。 - 非装饰性图片必须加
alt:为非装饰性图片添加alt属性,可以为搜索引擎提供关于图片内容的描述,同时也有助于可访问性。 - 提高网站速度:网站速度是搜索引擎排序的一个重要指标
2 <img>的title和alt有什么区别
title属性:title属性是HTML元素通用的属性,适用于各种元素,不仅仅是<img>标签。当鼠标滑动到元素上时,浏览器会显示title属性的内容,提供额外的信息或解释,帮助用户了解元素的用途或含义。对于<img>标签,鼠标悬停在图片上时会显示title属性的内容。alt属性:alt属性是<img>标签的特有属性,用于提供图片的替代文本描述。当图片无法加载时,浏览器会显示alt属性的内容,或者在可访问性场景中,读屏器会读取alt属性的内容。alt属性的主要目的是提高图片的可访问性,使无法查看图片的用户也能了解图片的内容或含义。除了纯装饰性图片外,所有<img>标签都应该设置有意义的alt属性值。- 补充答案:
title属性主要用于提供额外的信息或提示,是对图片的补充描述,可以用于提供更详细的说明,如图片的来源、作者、相关信息等。它不是必需的,但可以增强用户体验,特别是在需要显示更多信息时。alt属性是图片内容的等价描述,应该简洁明了地描述图片所表达的信息。它对于可访问性至关重要,确保无障碍用户能够理解图片的含义,同时也是搜索引擎重点分析的内容。在设置alt属性时,应该避免过度堆砌关键词,而是提供准确、有意义的描述。
3 HTTP的几种请求方法用途
GET方法:- 用途:发送一个请求来获取服务器上的某一资源。
- 面试可能涉及的问题:
- GET方法的特点是什么?
- GET方法是HTTP的一种请求方法,用于从服务器获取资源。
- 它是一种幂等的方法,多次发送相同的GET请求会返回相同的结果。
- GET请求和POST请求的区别是什么?
- GET请求将参数附加在URL的查询字符串中,而POST请求将参数放在请求体中。
- GET请求的数据会显示在URL中,而POST请求的数据不会显示在URL中。
- GET请求一般用于获取数据,而POST请求一般用于提交数据。
- GET请求可以有请求体吗?
- 根据HTTP规范,GET请求不应该有请求体,参数应该通过URL的查询字符串传递。
- GET请求的参数如何传递?
- GET请求的参数可以通过URL的查询字符串传递,例如:
/api/users?id=123&name=poetry。
- GET请求的参数可以通过URL的查询字符串传递,例如:
- GET请求的安全性和幂等性如何保证?
- GET请求不会对服务器端的资源产生副作用,因此被视为安全的。
- GET请求是幂等的,多次发送相同的GET请求不会对服务器端产生影响。
- GET方法的特点是什么?
POST方法:- 用途:向
URL指定的资源提交数据或附加新的数据。 - 面试可能涉及的问题:
- POST方法的特点是什么?
- POST方法是HTTP的一种请求方法,用于向服务器提交数据。
- 它不是幂等的,多次发送相同的POST请求可能会产生不同的结果。
- POST请求和GET请求的区别是什么?
- POST请求将参数放在请求体中,而GET请求将参数附加在URL的查询字符串中。
- POST请求的数据不会显示在URL中,而GET请求的数据会显示在URL中。
- POST请求一般用于提交数据,而GET请求一般用于获取数据。
- POST请求的请求体如何传递数据?
- POST请求的数据可以通过请求体以表单形式传递,或者以JSON等格式传递。
- POST请求的安全性和幂等性如何保证?
- POST请求可能对服务器端的资源产生副作用,因此被视为不安全的。
- POST请求不是幂等的,多次发送相同的POST请求可能会对服务器端产生影响。
- POST方法的特点是什么?
- 用途:向
- PUT方法:
- 用途:将数据发送给服务器,并将其存储在指定的URL位置。与POST方法不同的是,PUT方法指定了资源在服务器上的位置。
- 面试可能涉及的问题:
- PUT方法的特点是什么?
- PUT方法是HTTP的一种请求方法,用于将数据发送给服务器并存储在指定的URL位置。
- 它是一种幂等的方法,多次发送相同的PUT请求会对服务器端产生相同的结果。
- PUT请求和POST请求有什么区别?
- PUT请求用于指定资源在服务器上的位置,而POST请求没有指定位置。
- PUT请求一般用于更新或替换资源,而POST请求一般用于新增资源或提交数据。
- PUT请求的幂等性如何保证?
- PUT请求的幂等性保证是由服务器端实现的。
- 服务器端应该根据请求中的资源位置来处理请求,多次发送相同的PUT请求会对该位置上的资源进行相同的更新或替换操作。
- PUT方法的特点是什么?
HEAD方法- 只请求页面的首部
DELETE方法- 删除服务器上的某资源
OPTIONS方法- 它用于获取当前
URL所支持的方法。如果请求成功,会有一个Allow的头包含类似“GET,POST”这样的信息
- 它用于获取当前
TRACE方法TRACE方法被用于激发一个远程的,应用层的请求消息回路
CONNECT方法- 把请求连接转换到透明的
TCP/IP通道
- 把请求连接转换到透明的
4 从浏览器地址栏输入url到显示页面的步骤
基础版本
- 浏览器根据请求的
URL交给DNS域名解析,找到真实IP,向服务器发起请求; - 服务器交给后台处理完成后返回数据,浏览器接收文件(
HTML、JS、CSS、图象等); - 浏览器对加载到的资源(
HTML、JS、CSS等)进行语法解析,建立相应的内部数据结构(如HTML的DOM); - 载入解析到的资源文件,渲染页面,完成。
详细版
- 在浏览器地址栏输入URL
- 浏览器查看缓存,如果请求资源在缓存中并且新鲜,跳转到转码步骤
- 如果资源未缓存,发起新请求
- 如果已缓存,检验是否足够新鲜,足够新鲜直接提供给客户端,否则与服务器进行验证。
- 检验新鲜通常有两个HTTP头进行控制
Expires和Cache-Control:- HTTP1.0提供Expires,值为一个绝对时间表示缓存新鲜日期
- HTTP1.1增加了Cache-Control: max-age=,值为以秒为单位的最大新鲜时间
- 浏览器解析URL获取协议,主机,端口,path
- 浏览器组装一个HTTP(GET)请求报文
- 浏览器获取主机ip地址,过程如下:
- 浏览器缓存
- 本机缓存
- hosts文件
- 路由器缓存
- ISP DNS缓存
- DNS递归查询(可能存在负载均衡导致每次IP不一样)
- 打开一个socket与目标IP地址,端口建立TCP链接,三次握手如下:
- 客户端发送一个TCP的SYN=1,Seq=X的包到服务器端口
- 服务器发回SYN=1, ACK=X+1, Seq=Y的响应包
- 客户端发送ACK=Y+1, Seq=Z
- TCP链接建立后发送HTTP请求
- 服务器接受请求并解析,将请求转发到服务程序,如虚拟主机使用HTTP Host头部判断请求的服务程序
- 服务器检查HTTP请求头是否包含缓存验证信息如果验证缓存新鲜,返回304等对应状态码
- 处理程序读取完整请求并准备HTTP响应,可能需要查询数据库等操作
- 服务器将响应报文通过TCP连接发送回浏览器
- 浏览器接收HTTP响应,然后根据情况选择关闭TCP连接或者保留重用,关闭TCP连接的四次握手如下:
- 主动方发送Fin=1, Ack=Z, Seq= X报文
- 被动方发送ACK=X+1, Seq=Z报文
- 被动方发送Fin=1, ACK=X, Seq=Y报文
- 主动方发送ACK=Y, Seq=X报文
- 浏览器检查响应状态吗:是否为1XX,3XX, 4XX, 5XX,这些情况处理与2XX不同
- 如果资源可缓存,进行缓存
- 对响应进行解码(例如gzip压缩)
- 根据资源类型决定如何处理(假设资源为HTML文档)
- 解析HTML文档,构件DOM树,下载资源,构造CSSOM树,执行js脚本,这些操作没有严格的先后顺序,以下分别解释
- 构建DOM树:
- Tokenizing:根据HTML规范将字符流解析为标记
- Lexing:词法分析将标记转换为对象并定义属性和规则
- DOM construction:根据HTML标记关系将对象组成DOM树
- 解析过程中遇到图片、样式表、js文件,启动下载
- 构建CSSOM树:
- Tokenizing:字符流转换为标记流
- Node:根据标记创建节点
- CSSOM:节点创建CSSOM树
- 根据DOM树和CSSOM树构建渲染树:
- 从DOM树的根节点遍历所有可见节点,不可见节点包括:1)
script,meta这样本身不可见的标签。2)被css隐藏的节点,如display: none - 对每一个可见节点,找到恰当的CSSOM规则并应用
- 发布可视节点的内容和计算样式
- 从DOM树的根节点遍历所有可见节点,不可见节点包括:1)
- js解析如下:
- 浏览器创建Document对象并解析HTML,将解析到的元素和文本节点添加到文档中,此时document.readystate为loading
- HTML解析器遇到没有async和defer的script时,将他们添加到文档中,然后执行行内或外部脚本。这些脚本会同步执行,并且在脚本下载和执行时解析器会暂停。这样就可以用document.write()把文本插入到输入流中。同步脚本经常简单定义函数和注册事件处理程序,他们可以遍历和操作script和他们之前的文档内容
- 当解析器遇到设置了async属性的script时,开始下载脚本并继续解析文档。脚本会在它下载完成后尽快执行,但是解析器不会停下来等它下载。异步脚本禁止使用document.write(),它们可以访问自己script和之前的文档元素
- 当文档完成解析,document.readState变成interactive
- 所有defer脚本会按照在文档出现的顺序执行,延迟脚本能访问完整文档树,禁止使用document.write()
- 浏览器在Document对象上触发DOMContentLoaded事件
- 此时文档完全解析完成,浏览器可能还在等待如图片等内容加载,等这些内容完成载入并且所有异步脚本完成载入和执行,document.readState变为complete,window触发load事件
- 显示页面(HTML解析过程中会逐步显示页面)
详细简版
- 从浏览器接收
url到开启网络请求线程(这一部分可以展开浏览器的机制以及进程与线程之间的关系) - 开启网络线程到发出一个完整的
HTTP请求(这一部分涉及到dns查询,TCP/IP请求,五层因特网协议栈等知识) - 从服务器接收到请求到对应后台接收到请求(这一部分可能涉及到负载均衡,安全拦截以及后台内部的处理等等)
- 后台和前台的
HTTP交互(这一部分包括HTTP头部、响应码、报文结构、cookie等知识,可以提下静态资源的cookie优化,以及编码解码,如gzip压缩等) - 单独拎出来的缓存问题,
HTTP的缓存(这部分包括http缓存头部,ETag,catch-control等) - 浏览器接收到
HTTP数据包后的解析流程(解析html-词法分析然后解析成dom树、解析css生成css规则树、合并成render树,然后layout、painting渲染、复合图层的合成、GPU绘制、外链资源的处理、loaded和DOMContentLoaded等) CSS的可视化格式模型(元素的渲染规则,如包含块,控制框,BFC,IFC等概念)JS引擎解析过程(JS的解释阶段,预处理阶段,执行阶段生成执行上下文,VO,作用域链、回收机制等等)- 其它(可以拓展不同的知识模块,如跨域,web安全,
hybrid模式等等内容)
5 如何进行网站性能优化
content方面- 减少
HTTP请求:合并文件、CSS精灵、inline Image - 减少
DNS查询:DNS缓存、将资源分布到恰当数量的主机名 - 减少
DOM元素数量
- 减少
Server方面- 使用
CDN - 配置
ETag - 对组件使用
Gzip压缩
- 使用
Cookie方面- 减小
cookie大小
- 减小
css方面- 将样式表放到页面顶部
- 不使用
CSS表达式 - 使用
<link>不使用@import
Javascript方面- 将脚本放到页面底部
- 将
javascript和css从外部引入 - 压缩
javascript和css - 删除不需要的脚本
- 减少
DOM访问
- 图片方面
- 优化图片:根据实际颜色需要选择色深、压缩
- 优化
css精灵 - 不要在
HTML中拉伸图片
你有用过哪些前端性能优化的方法?
- 减少
http请求次数:CSS Sprites,JS、CSS源码压缩、图片大小控制合适;网页Gzip,CDN托管,data缓存 ,图片服务器。 - 前端模板 JS+数据,减少由于HTML标签导致的带宽浪费,前端用变量保存
AJAX请求结果,每次操作本地变量,不用请求,减少请求次数 - 用
innerHTML代替DOM操作,减少DOM操作次数,优化javascript性能。 - 当需要设置的样式很多时设置
className而不是直接操作style - 少用全局变量、缓存DOM节点查找的结果。减少IO读取操作
- 避免使用
CSS Expression(css表达式)又称Dynamic properties(动态属性) - 图片预加载,将样式表放在顶部,将脚本放在底部 加上时间戳
- 避免在页面的主体布局中使用
table,table要等其中的内容完全下载之后才会显示出来,显示比div+css布局慢
谈谈性能优化问题
- 代码层面:避免使用
css表达式,避免使用高级选择器,通配选择器 - 缓存利用:缓存
Ajax,使用CDN,使用外部js和css文件以便缓存,添加Expires头,服务端配置Etag,减少DNS查找等 - 请求数量:合并样式和脚本,使用
css图片精灵,初始首屏之外的图片资源按需加载,静态资源延迟加载 - 请求带宽:压缩文件,开启
GZIP
前端性能优化最佳实践?
- 性能评级工具(
PageSpeed或YSlow) - 合理设置
HTTP缓存:Expires与Cache-control - 静态资源打包,开启 Gzip 压缩(节省响应流量)
CSS3模拟图像,图标base64(降低请求数)- 模块延迟(defer)加载/异步(
async)加载 Cookie隔离(节省请求流量)localStorage(本地存储)- 使用
CDN加速(访问最近服务器) - 启用
HTTP/2(多路复用,并行加载) - 前端自动化(
gulp/webpack)
6 HTTP状态码及其含义
1XX:信息状态码100 Continue继续,一般在发送post请求时,已发送了http header之后服务端将返回此信息,表示确认,之后发送具体参数信息
2XX:成功状态码200 OK正常返回信息201 Created请求成功并且服务器创建了新的资源202 Accepted服务器已接受请求,但尚未处理
3XX:重定向301 Moved Permanently请求的网页已永久移动到新位置。302 Found临时性重定向。303 See Other临时性重定向,且总是使用GET请求新的URI。304 Not Modified自从上次请求后,请求的网页未修改过。
4XX:客户端错误400 Bad Request服务器无法理解请求的格式,客户端不应当尝试再次使用相同的内容发起请求。401 Unauthorized请求未授权。403 Forbidden禁止访问。404 Not Found找不到如何与URI相匹配的资源。
5XX:服务器错误500 Internal Server Error最常见的服务器端错误。503 Service Unavailable服务器端暂时无法处理请求(可能是过载或维护)
7 语义化的理解
语义化是指在编写HTML和CSS代码时,通过恰当的选择标签和属性,使得代码更具有语义性和可读性,使得页面结构和内容更加清晰明了。语义化的目的是让页面具备良好的可访问性、可维护性和可扩展性。
语义化的重要性体现在以下几个方面:
- 可访问性(Accessibility):通过使用恰当的标签和属性,可以提高页面的可访问性,使得辅助技术(如屏幕阅读器)能够更好地理解和解析页面内容,使得残障用户能够正常浏览和使用网页。
- 搜索引擎优化(SEO):搜索引擎更喜欢能够理解和解析的页面内容,语义化的HTML结构可以提高页面在搜索引擎结果中的排名,增加网页的曝光和访问量。
- 代码可读性和可维护性:使用语义化的标签和属性,可以让代码更易于阅读和理解,提高代码的可维护性。开发人员可以更快速地定位和修改特定功能或内容。
- 设备兼容性:不同设备和平台对于网页的渲染和解析方式有所不同,语义化的代码可以增加网页在各种设备上的兼容性,确保页面在不同环境中的正确显示和使用。
语义化在前端开发中的具体表现和实践包括以下几个方面:
- 选择合适的HTML标签:在构建页面结构时,选择恰当的HTML标签来描述内容的含义。例如,使用
<header>表示页面的页眉,<nav>表示导航栏,<article>表示独立的文章内容等。 - 使用有意义的标签和属性:避免滥用
<div>标签,而是选择更具语义的标签来表达内容的含义。同时,合理使用标签的属性,如alt属性用于图像的替代文本,title属性用于提供额外的信息等。 - 结构和层次化:通过正确嵌套和组织HTML元素,构建清晰的页面结构和层次关系。使用语义化的父子关系,让内容的层级关系更加明确,便于样式和脚本的编写和维护。
- 文本格式化:使用合适的标签和属性来标记文本的格式和语义。例如,使用
<strong>标签表示重要文本,<em>标签表示强调文本,<blockquote>标签表示引用文本等。 - 无障碍支持:考虑到残障用户的需求,使用语义化的标签和属性可以提高页面的可访问性。例如,为表格添加适当的表头和描述信息,为表单元素关联标签等。
- CSS选择器的语义化:在编写CSS样式时,尽量使用具有语义的类名和ID,避免过于依赖元素标签选择器,以增强样式的可读性和可维护性。
通过遵循语义化的原则,我们能够构建出更具有可读性、可访问性和可维护性的前端代码,提高用户体验和开发效率。同时,也能够使网页在不同的环境和设备上保持一致的表现,增强网站的可持续性和可扩展性。
总结
- 用正确的标签做正确的事情!
HTML语义化就是让页面的内容结构化,便于对浏览器、搜索引擎解析;- 在没有样式
CSS情况下也以一种文档格式显示,并且是容易阅读的。 - 搜索引擎的爬虫依赖于标记来确定上下文和各个关键字的权重,利于
SEO。 - 使阅读源代码的人对网站更容易将网站分块,便于阅读维护理解
8 介绍一下你对浏览器内核的理解?
浏览器内核是浏览器的核心组成部分,主要分为两个部分:渲染引擎(也称为布局引擎或渲染引擎)和 JavaScript 引擎。
- 渲染引擎:渲染引擎负责解析网页的 HTML、XML、图像等内容,并将其转换为可视化的网页形式展示给用户。它负责处理网页的布局、样式计算、绘制等任务。不同浏览器的内核对网页的解释和渲染方式可能会有差异,因此不同浏览器的渲染效果也会有所不同。常见的渲染引擎包括:
WebKit:主要用于 Safari 和 Chrome 浏览器。Gecko:主要用于 Firefox 浏览器。Trident:主要用于旧版本的 Internet Explorer 浏览器。Blink:基于 WebKit,用于 Chrome、Opera 和部分 Chromium 浏览器。
- JavaScript 引擎:JavaScript 引擎负责解析和执行网页中的 JavaScript 代码,实现网页的动态交互和功能。不同浏览器的 JavaScript 引擎性能和特性也可能存在差异。常见的 JavaScript 引擎包括:
V8:用于 Chrome 和Opera浏览器,具有高性能和快速执行速度。SpiderMonkey:用于Firefox浏览器。JavaScriptCore:用于Safari浏览器。
- 在早期,渲染引擎和 JavaScript 引擎没有明确的分离,它们在同一个内核中工作。随着时间的推移,JavaScript 引擎逐渐独立出来,使内核更专注于页面渲染和布局方面的任务。
- 理解浏览器内核对于前端开发人员非常重要,因为不同的内核可能会对网页的解释和渲染产生影响,从而影响页面的布局、样式和交互效果。在开发过程中,需要考虑不同浏览器内核的差异,并进行兼容性测试和优化,以确保网页在不同浏览器上都能正确显示和运行。
9 html5有哪些新特性、移除了那些元素?
HTML5现在已经不是SGML的子集,主要是关于图像,位置,存储,多任务等功能的增加- 新增选择器
document.querySelector、document.querySelectorAll - 拖拽释放(
Drag and drop) API - 媒体播放的
video和audio - 本地存储
localStorage和sessionStorage - 离线应用
manifest - 桌面通知
Notifications - 语意化标签
article、footer、header、nav、section - 增强表单控件
calendar、date、time、email、url、search - 地理位置
Geolocation - 多任务
webworker - 全双工通信协议
websocket - 历史管理
history - 跨域资源共享(CORS)
Access-Control-Allow-Origin - 页面可见性改变事件
visibilitychange - 跨窗口通信
PostMessage Form Data对象- 绘画
canvas
- 新增选择器
- 移除的元素:
- 纯表现的元素:
basefont、big、center、font、s、strike、tt、u - 对可用性产生负面影响的元素:
frame、frameset、noframes
- 纯表现的元素:
- 支持
HTML5新标签:IE8/IE7/IE6支持通过document.createElement方法产生的标签- 可以利用这一特性让这些浏览器支持
HTML5新标签 - 浏览器支持新标签后,还需要添加标签默认的样式
- 当然也可以直接使用成熟的框架、比如
html5shim
如何区分 HTML 和 HTML5
DOCTYPE声明、新增的结构元素、功能元素
10 HTML5的离线储存怎么使用,工作原理能不能解释一下?
- 在用户没有与因特网连接时,可以正常访问站点或应用,在用户与因特网连接时,更新用户机器上的缓存文件
- 原理:
HTML5的离线存储是基于一个新建的.appcache文件的缓存机制(不是存储技术),通过这个文件上的解析清单离线存储资源,这些资源就会像cookie一样被存储了下来。之后当网络在处于离线状态下时,浏览器会通过被离线存储的数据进行页面展示 - 如何使用:
- 页面头部像下面一样加入一个
manifest的属性; - 在
cache.manifest文件的编写离线存储的资源 - 在离线状态时,操作
window.applicationCache进行需求实现
- 页面头部像下面一样加入一个
CACHE MANIFEST
#v0.11
CACHE:
js/app.js
css/style.css
NETWORK:
resourse/logo.png
FALLBACK:
/offline.html
@前端进阶之旅: 代码已经复制到剪贴板
11 浏览器是怎么对HTML5的离线储存资源进行管理和加载的呢
- 在线的情况下,浏览器发现
html头部有manifest属性,它会请求manifest文件,如果是第一次访问app,那么浏览器就会根据manifest文件的内容下载相应的资源并且进行离线存储。如果已经访问过app并且资源已经离线存储了,那么浏览器就会使用离线的资源加载页面,然后浏览器会对比新的manifest文件与旧的manifest文件,如果文件没有发生改变,就不做任何操作,如果文件改变了,那么就会重新下载文件中的资源并进行离线存储。 - 离线的情况下,浏览器就直接使用离线存储的资源。
12 请描述一下 cookies,sessionStorage 和 localStorage 的区别?
cookies、sessionStorage和localStorage都是在 Web 开发中用于在客户端存储数据的技术,但它们在以下方面存在区别:
存储容量
cookies:通常存储容量较小,一般限制在4KB左右。sessionStorage:存储容量比cookies大,不同浏览器的限制有所不同,但一般可以存储5MB或更多的数据。localStorage:存储容量也较大,通常和sessionStorage相近,能满足大多数 Web 应用的存储需求。
数据有效期
cookies:可以设置过期时间,若不设置,默认在浏览器关闭时失效。如果设置了过期时间,那么在过期时间之前,cookies会一直存在于客户端,即使浏览器关闭后重新打开也依然有效。sessionStorage:数据仅在当前会话期间有效,当浏览器窗口关闭时,sessionStorage中的数据会被自动清除。localStorage:数据没有自动过期时间,除非主动删除,否则数据会一直保存在客户端,即使浏览器关闭、电脑重启,数据依然存在。
作用域
cookies:在同域名下的不同页面之间可以共享,但如果设置了Path属性,那么只有在指定路径下的页面才能访问该cookie。此外,cookies还可以通过设置Domain属性在不同子域名之间共享。sessionStorage:具有严格的页面级作用域,即只有在同一个浏览器窗口(或标签页)中打开的页面才能共享sessionStorage中的数据。不同浏览器窗口或标签页之间无法访问彼此的sessionStorage数据,即使它们来自同一个域名。localStorage:在同域名下的所有页面都可以共享localStorage中的数据,只要是在同一个浏览器中访问该域名,无论在哪个页面存储的数据,其他页面都可以读取和修改。
与服务器的交互
cookies:每次向服务器发送请求时,浏览器会自动将同域名下的cookies发送到服务器,这可能会增加不必要的网络传输开销,尤其是当cookies数据量较大时。sessionStorage和localStorage:数据仅存储在客户端,不会自动发送到服务器。如果需要与服务器进行数据交互,需要通过 Ajax 等方式手动将数据发送到服务器。
应用场景
cookies:常用于存储用户登录状态、购物车信息、用户偏好设置等。由于其会在每次请求时发送到服务器,所以也可以用于在客户端和服务器之间传递一些少量的必要信息。sessionStorage:适合存储一些临时数据,例如在一个多步骤的表单填写过程中,存储用户在当前页面填写的数据,当用户完成整个流程或关闭页面时,这些数据就不再需要了。localStorage:用于长期存储用户相关的数据,如用户的配置信息、离线缓存数据等。例如,一个 Web 应用可以将一些常用的静态资源存储在localStorage中,以便在离线状态下仍然能够访问应用的部分功能。
13 iframe有那些缺点?
iframe是一种在网页中嵌入其他网页或文档的标签,虽然它在某些情况下可以提供一些便利,但也存在一些缺点需要考虑:
- 阻塞主页面的
onload事件:当页面中存在iframe时,iframe的加载会阻塞主页面的onload事件触发。这可能会导致页面加载速度变慢,影响用户体验。 - 不利于
SEO:搜索引擎的爬虫程序通常不能很好地解读iframe内部的内容。因此,如果重要的页面内容被放置在iframe中,搜索引擎可能无法正确地索引和收录这些内容,从而影响网页的搜索引擎优化(SEO)。 - 连接限制和并行加载:
iframe和主页面共享连接池,而大多数浏览器对相同域的连接数有限制。这意味着当页面中包含多个iframe时,浏览器需要同时处理这些连接,可能会影响页面的并行加载能力,导致页面加载速度变慢。
为了避免以上问题,可以考虑以下解决方案:
- 尽量避免使用
iframe,特别是在主要内容部分。 - 如果必须使用
iframe,可以通过JavaScript动态地给iframe添加src属性值,而不是在静态HTML中指定。这样可以绕开阻塞主页面的onload事件。 对于需要被搜索引擎索引的重要内容,避免将其放置在iframe中。 - 考虑使用其他替代方案,如
AJAX加载内容或使用现代的前端框架来实现类似的效果。 - 总之,
iframe在某些场景下可以提供方便,但在使用时需要注意其缺点,并根据具体情况进行权衡和选择。
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
23 viewport
<meta name="viewport" content="width=device-width,initial-scale=1.0,minimum-scale=1.0,maximum-scale=1.0,user-scalable=no" />
// width 设置viewport宽度,为一个正整数,或字符串‘device-width’
// device-width 设备宽度
// height 设置viewport高度,一般设置了宽度,会自动解析出高度,可以不用设置
// initial-scale 默认缩放比例(初始缩放比例),为一个数字,可以带小数
// minimum-scale 允许用户最小缩放比例,为一个数字,可以带小数
// maximum-scale 允许用户最大缩放比例,为一个数字,可以带小数
// user-scalable 是否允许手动缩放
@前端进阶之旅: 代码已经复制到剪贴板
- 延伸提问
- 怎样处理 移动端
1px被 渲染成2px问题?
- 怎样处理 移动端
局部处理
meta标签中的viewport属性 ,initial-scale设置为1rem按照设计稿标准走,外加利用transform的scale(0.5)缩小一倍即可;
全局处理
mata标签中的viewport属性 ,initial-scale设置为0.5rem按照设计稿标准走即可
24 渲染优化
- 禁止使用
iframe(阻塞父文档onload事件)iframe会阻塞主页面的Onload事件- 搜索引擎的检索程序无法解读这种页面,不利于SEO
iframe和主页面共享连接池,而浏览器对相同域的连接有限制,所以会影响页面的并行加载- 使用
iframe之前需要考虑这两个缺点。如果需要使用iframe,最好是通过javascript - 动态给
iframe添加src属性值,这样可以绕开以上两个问题
- 禁止使用
gif图片实现loading效果(降低CPU消耗,提升渲染性能) - 使用
CSS3代码代替JS动画(尽可能避免重绘重排以及回流) - 对于一些小图标,可以使用base64位编码,以减少网络请求。但不建议大图使用,比较耗费
CPU- 小图标优势在于
- 减少
HTTP请求 - 避免文件跨域
- 修改及时生效
- 减少
- 小图标优势在于
- 页面头部的
<style></style><script></script>会阻塞页面;(因为Renderer进程中JS线程和渲染线程是互斥的) - 页面中空的
href和src会阻塞页面其他资源的加载 (阻塞下载进程) - 网页
gzip,CDN托管,data缓存 ,图片服务器 - 前端模板 JS+数据,减少由于
HTML标签导致的带宽浪费,前端用变量保存AJAX请求结果,每次操作本地变量,不用请求,减少请求次数 - 用
innerHTML代替DOM操作,减少DOM操作次数,优化javascript性能 - 当需要设置的样式很多时设置
className而不是直接操作style - 少用全局变量、缓存
DOM节点查找的结果。减少IO读取操作 - 图片预加载,将样式表放在顶部,将脚本放在底部 加上时间戳
- 对普通的网站有一个统一的思路,就是尽量向前端优化、减少数据库操作、减少磁盘
IO
25 meta viewport相关
<!DOCTYPE html> <!--H5标准声明,使用 HTML5 doctype,不区分大小写-->
<head lang=”en”> <!--标准的 lang 属性写法-->
<meta charset=’utf-8′> <!--声明文档使用的字符编码-->
<meta http-equiv=”X-UA-Compatible” content=”IE=edge,chrome=1″/> <!--优先使用 IE 最新版本和 Chrome-->
<meta name=”description” content=”不超过150个字符”/> <!--页面描述-->
<meta name=”keywords” content=””/> <!-- 页面关键词-->
<meta name=”author” content=”name, email@gmail.com”/> <!--网页作者-->
<meta name=”robots” content=”index,follow”/> <!--搜索引擎抓取-->
<meta name=”viewport” content=”initial-scale=1, maximum-scale=3, minimum-scale=1, user-scalable=no”> <!--为移动设备添加 viewport-->
<meta name=”apple-mobile-web-app-title” content=”标题”> <!--iOS 设备 begin-->
<meta name=”apple-mobile-web-app-capable” content=”yes”/> <!--添加到主屏后的标题(iOS 6 新增)
是否启用 WebApp 全屏模式,删除苹果默认的工具栏和菜单栏-->
<meta name=”apple-itunes-app” content=”app-id=myAppStoreID, affiliate-data=myAffiliateData, app-argument=myURL”>
<!--添加智能 App 广告条 Smart App Banner(iOS 6+ Safari)-->
<meta name=”apple-mobile-web-app-status-bar-style” content=”black”/>
<meta name=”format-detection” content=”telphone=no, email=no”/> <!--设置苹果工具栏颜色-->
<meta name=”renderer” content=”webkit”> <!-- 启用360浏览器的极速模式(webkit)-->
<meta http-equiv=”X-UA-Compatible” content=”IE=edge”> <!--避免IE使用兼容模式-->
<meta http-equiv=”Cache-Control” content=”no-siteapp” /> <!--不让百度转码-->
<meta name=”HandheldFriendly” content=”true”> <!--针对手持设备优化,主要是针对一些老的不识别viewport的浏览器,比如黑莓-->
<meta name=”MobileOptimized” content=”320″> <!--微软的老式浏览器-->
<meta name=”screen-orientation” content=”portrait”> <!--uc强制竖屏-->
<meta name=”x5-orientation” content=”portrait”> <!--QQ强制竖屏-->
<meta name=”full-screen” content=”yes”> <!--UC强制全屏-->
<meta name=”x5-fullscreen” content=”true”> <!--QQ强制全屏-->
<meta name=”browsermode” content=”application”> <!--UC应用模式-->
<meta name=”x5-page-mode” content=”app”> <!-- QQ应用模式-->
<meta name=”msapplication-tap-highlight” content=”no”> <!--windows phone 点击无高亮
设置页面不缓存-->
<meta http-equiv=”pragma” content=”no-cache”>
<meta http-equiv=”cache-control” content=”no-cache”>
<meta http-equiv=”expires” content=”0″>
@前端进阶之旅: 代码已经复制到剪贴板
26 你做的页面在哪些流览器测试过?这些浏览器的内核分别是什么?
IE使用的是Trident内核。Firefox使用的是Gecko内核。Safari使用的是WebKit内核。Opera在过去使用的是Presto内核,但现在已经改用了与Google Chrome相同的Blink内核。Chrome使用的是基于WebKit开发的Blink内核。
这些浏览器内核的不同决定了它们在渲染网页时的行为和特性支持。在开发和测试网页时,通常需要在不同的浏览器上进行测试,以确保网页在不同内核的浏览器上都能正确显示和运行。
27 div+css的布局较table布局有什么优点?
- 改版的时候更方便 只要改
css文件。 - 页面加载速度更快、结构化清晰、页面显示简洁。
- 表现与结构相分离。
- 易于优化(
seo)搜索引擎更友好,排名更容易靠前。
28 a:img的alt与title有何异同?b:strong与em的异同?
alt(alt text): 用于为不能显示图像、窗体或applets的用户代理(UA)提供替代文字。它由lang属性指定替代文字的语言。在某些浏览器中,当没有title属性时,会将alt属性作为工具提示(tooltip)显示。title(tool tip): 用于为元素提供额外的提示信息,当鼠标悬停在元素上时显示。它提供了一种向用户解释元素用途或提供有关元素的补充信息的方式。
b:strong与em的异同?
strong: 是表示文本的重要性或紧急性的标签,通常呈现为加粗的文本样式。它用于强调内容的重要性,可以为内容赋予更大的权重。em: 是表示文本的强调或重要性的标签,通常呈现为斜体的文本样式。它用于更强烈地强调内容,使其在阅读时更具有突出性,但并不改变内容的含义。
注意:strong和em都是语义化标签,用于表示文本的语义和重要性,而不仅仅是样式上的改变。
29 你能描述一下渐进增强和优雅降级之间的不同吗
- 渐进增强:针对低版本浏览器进行构建页面,保证最基本的功能,然后再针对高级浏览器进行效果、交互等改进和追加功能达到更好的用户体验。
- 优雅降级:一开始就构建完整的功能,然后再针对低版本浏览器进行兼容。
区别:优雅降级是从复杂的现状开始,并试图减少用户体验的供给,而渐进增强则是从一个非常基础的,能够起作用的版本开始,并不断扩充,以适应未来环境的需要。降级(功能衰减)意味着往回看;而渐进增强则意味着朝前看,同时保证其根基处于安全地带
30 为什么利用多个域名来存储网站资源会更有效?
利用多个域名来存储网站资源可以带来以下好处:
- CDN缓存更方便:内容分发网络(CDN)可以更轻松地缓存和分发位于不同域名下的资源,提高资源的访问速度和可用性。
- 突破浏览器并发限制:大多数浏览器对同一域名下的并发请求数量有限制,通过将资源分布在多个域名下,可以突破这一限制,同时发送更多的并发请求,加快页面加载速度。
- 节约cookie带宽:浏览器在每个请求中都会携带相应域名下的cookie信息,通过将资源分布在不同的域名下,可以减少对cookie的传输,节约带宽和提高性能。
- 节约主域名的连接数:浏览器对同一域名下的连接数也有限制,通过将资源请求分散到多个域名下,可以减少对主域名的连接数占用,提高页面的响应速度和并发处理能力。
- 防止不必要的安全问题:将静态资源与主要网站内容分离到不同的域名下,可以降低恶意攻击者利用资源加载过程中的安全漏洞对主站点进行攻击的风险。
综上所述,通过利用多个域名来存储网站资源,可以提升网站的性能、安全性和用户体验。
31 简述一下src与href的区别
src和href是HTML中两个常见的属性,它们有以下区别:
src属性(source)用于指定要嵌入到当前文档中的外部资源的位置。例如,<script src="script.js"></script>用于引入一个外部的JavaScript文件,或者<img src="image.jpg" alt="Image">用于显示一个外部的图像文件。浏览器在解析到带有src属性的元素时,会暂停当前文档的加载和解析,去下载并执行或显示指定的资源。href属性(hypertext reference)用于建立当前文档和引用资源之间的关联。它通常用于链接到其他文档或外部资源,例如<a href="https://www.example.com">Link</a>用于创建一个指向外部网页的链接,或者<link href="styles.css" rel="stylesheet">用于引入外部的CSS样式表。浏览器在解析到带有href属性的元素时,会同时进行当前文档和引用资源的加载和处理,而不会阻塞当前文档的解析。
总结来说:
src用于替换当前元素,指向的资源会嵌入到文档中,例如脚本、图像、框架等。href用于建立文档与引用资源之间的链接,例如链接到其他文档或引入外部样式表。
注意:尽管它们的用途不同,但在实际使用时,需要根据元素的类型和需求正确地选择使用src或href属性。
32 知道的网页制作会用到的图片格式有哪些?
在网页制作中,常用的图片格式包括:
- JPEG(Joint Photographic Experts Group):适用于存储照片和复杂的图像,具有较高的压缩比,但会有一定的图像质量损失。
- PNG(Portable Network Graphics):适用于图标、透明背景的图像以及需要保留较高图像质量的场景。可以选择使用
PNG-8或PNG-24,前者支持最多256种颜色,后者支持更多颜色但文件体积更大。 - GIF(Graphics Interchange Format):适用于简单动画和图标,支持透明背景和基本的透明度。
- SVG(Scalable Vector Graphics):矢量图形格式,使用XML描述图形,具有无损缩放和可编辑性。
除了上述常见的图片格式,还有一些新兴的图片格式:
- WebP:由Google开发的一种旨在提高图片加载速度的格式,具有较高的压缩率和图像质量,逐渐被主流浏览器支持。
- APNG(Animated Portable Network Graphics):是PNG的位图动画扩展,支持帧动画效果,但浏览器兼容性较差。
请注意,选择合适的图片格式应根据具体需求,如图像内容、透明度要求、动画效果等。新的图片格式如WebP和APNG可以根据项目需求和兼容性考虑是否使用。
33 在CSS/JS代码上线之后,开发人员经常会优化性能。从用户刷新网页开始,一次JS请求一般情况下有哪些地方会有缓存处理?
在进行JS请求时,可以在以下几个地方进行缓存处理,以提高性能和减少资源加载时间:
- DNS缓存:浏览器会缓存已解析的域名和对应的IP地址,这样在下次请求同一域名时可以直接使用缓存的IP地址,避免重新进行DNS解析。
- CDN缓存:如果使用了内容分发网络(CDN),CDN会缓存静态资源文件,如CSS和JS文件,以便快速地分发给用户。当用户再次请求同一资源时,可以从CDN缓存中获取,减少向源服务器的请求次数。
- 浏览器缓存:浏览器会缓存已请求的静态资源文件,如CSS和JS文件。可以通过设置HTTP响应头中的
Cache-Control和Expires字段来控制浏览器缓存的行为。如果设置了适当的缓存策略,浏览器在下次请求同一资源时可以直接从本地缓存中获取,而不需要再次向服务器请求。 - 服务器缓存:服务器可以对动态生成的JS文件进行缓存,以避免重复生成相同的响应。服务器可以通过设置响应头中的
Cache-Control和Expires字段,或者使用缓存代理服务器来进行缓存处理。
需要注意的是,缓存的有效期限和缓存策略的设置需要根据具体的需求和业务场景来确定。合理地利用缓存可以显著提高网页加载速度和用户体验。
33 一个页面上有大量的图片(大型电商网站),加载很慢,你有哪些方法优化这些图片的加载,给用户更好的体验。
- 使用图像压缩技术:通过使用图像压缩工具,如PhotoShop、TinyPNG等,将图片文件的大小减小,以减少加载时间。
- 使用适当的图像格式:根据图像的特性选择合适的图像格式,如JPEG、PNG、WebP等。JPEG适用于照片和复杂图像,而PNG适用于简单的图标和透明图像。WebP是一种现代的图像格式,可以在保持良好质量的同时减小文件大小。
- 图片CDN加速:使用内容分发网络(CDN)来加速图片的传输,将图片文件缓存到离用户更近的服务器,减少传输时间。
- 图片延迟加载:采用图片懒加载技术,将页面上不可见区域的图片暂时不加载,当用户滚动页面至可见区域时再进行加载,以减少初始加载时间。
- 使用CSS精灵图:将多个小图标或背景图片合并为一张大图,并利用CSS的
background-position来定位显示需要的部分,减少HTTP请求的数量。 - 使用矢量图形:使用矢量图形(如SVG)代替位图,以减小文件大小并保持清晰度,适用于简单的图形和图标。
- 响应式图片:针对不同的设备和屏幕尺寸提供适当大小的图片,以避免在小屏幕设备上加载过大的图片。
- 图片懒加载、预加载:根据用户的浏览行为,提前加载下一页或下一组图片,以提高用户体验和流畅度。
- 图片缓存:设置适当的缓存策略,让浏览器在首次加载后对图片进行缓存,减少重复加载的次数。
综合应用这些优化技术可以减小图片的加载大小和加载时间,提升网页的加载速度,给用户更好的体验。
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
41 http2.0 做了哪些改进 http3.0 呢
HTTP/2 的特性包括:
1. 二进制分帧
- HTTP/1.x:基于文本格式,报文以明文形式传输,解析过程复杂且容易出错,效率较低。
- HTTP/2:采用二进制分帧层,将所有传输的信息分割为更小的帧,并对这些帧进行二进制编码。帧是 HTTP/2 数据传输的最小单位,包括头帧和数据帧等。这种二进制分帧的方式使得协议的解析更加高效、准确,提高了数据传输的性能。
2. 多路复用
- HTTP/1.x:同一时间一个连接只能处理一个请求,当有多个请求时,需要依次排队等待处理,容易出现“队头阻塞”问题,即一个请求阻塞会影响后续请求的处理。
- HTTP/2:通过多路复用机制,允许在一个连接上同时并行处理多个请求和响应。每个请求和响应被拆分成多个独立的帧,这些帧可以在连接上乱序发送和接收,然后在另一端根据帧的标识进行重新组装。这样可以充分利用网络带宽,提高连接的利用率,避免了“队头阻塞”问题。
3. 头部压缩
- HTTP/1.x:请求和响应的头部信息通常以明文形式重复传输,包含了很多重复的字段,如
User - Agent、Cookie等,会占用大量的带宽。 - HTTP/2:采用 HPACK 算法对头部信息进行压缩。HPACK 会维护一个静态表和一个动态表,对于重复出现的头部字段,只需要在表中存储一次,后续传输时只需传输对应的索引,从而大大减少了头部信息的传输量,降低了带宽消耗。
4. 服务器推送
- HTTP/1.x:客户端需要明确请求服务器上的资源,服务器只能被动响应客户端的请求,无法主动向客户端推送资源。
- HTTP/2:支持服务器推送功能,服务器可以在客户端请求某个资源时,主动将客户端可能需要的其他资源一起推送给客户端。例如,当客户端请求一个 HTML 页面时,服务器可以同时推送该页面所需的 CSS、JavaScript 等资源,减少了客户端的请求次数,提高了页面的加载速度。
而 HTTP/3 则是基于 QUIC 协议的新一代 HTTP 协议。QUIC 是一个基于 UDP 的传输协议,具有以下特性:
1. 基于 QUIC 协议
- HTTP/2:仍然基于 TCP 协议,TCP 协议在处理丢包重传、拥塞控制等方面存在一些固有的问题,可能会导致“队头阻塞”问题,影响数据传输的性能。
- HTTP/3:采用 QUIC(快速 UDP 互联网连接)协议作为传输层协议。QUIC 基于 UDP 实现,但在 UDP 的基础上增加了可靠传输、拥塞控制、加密等功能。QUIC 协议的连接建立速度更快,并且在丢包情况下不会影响其他流的传输,避免了 TCP 协议中的“队头阻塞”问题,进一步提高了数据传输的性能和可靠性。
2. 连接迁移
- HTTP/2:基于 TCP 协议,TCP 连接依赖于源 IP 地址、目的 IP 地址、源端口和目的端口,当设备的网络环境发生变化(如从 Wi - Fi 切换到移动数据网络)时,TCP 连接会中断,需要重新建立连接,这可能会导致数据传输中断和延迟。
- HTTP/3:QUIC 协议通过连接 ID 来标识连接,而不是依赖于 IP 地址和端口。当设备的网络环境发生变化时,只要连接 ID 不变,QUIC 连接可以保持不变,实现无缝的连接迁移,提高了用户体验。
3. 更灵活的拥塞控制
- HTTP/2:TCP 协议的拥塞控制算法是固定的,不同的网络环境可能需要不同的拥塞控制策略,TCP 难以快速适应网络变化。
- HTTP/3:QUIC 协议的拥塞控制更加灵活,可以根据不同的网络情况动态调整拥塞控制策略,更好地适应各种复杂的网络环境,提高数据传输的效率。
总结:HTTP/2 和 HTTP/3 都是在传输层进行的协议改进,HTTP/2 在 TCP 上引入了二进制分帧传输、多路复用、头部压缩和服务器推送等特性,而 HTTP/3 则是基于 UDP 的 QUIC 协议,引入了连接迁移、无队头阻塞、自定义拥塞控制和前向安全和前向纠错等新特性。
二、CSS相关
1 css sprite是什么,有什么优缺点
CSS Sprite(CSS精灵)是一种将多个小图片合并到一张大图中的技术。通过在页面中引用这张大图,并设置合适的background-position和尺寸,可以显示出所需的小图标或背景图案。
优点:
- 减少
HTTP请求数:将多个小图片合并成一张大图,减少了浏览器与服务器之间的请求次数,提高了页面加载速度。 - 提高性能:由于减少了请求数,减少了网络传输时间和延迟,加快了页面加载速度,提升了用户体验。
- 减小图片大小:合并后的大图可以使用更高效的压缩算法进行压缩,减小了图片的文件大小。
- 方便更换风格:只需要替换或修改一张大图中的小图标或背景图案,就可以改变整个页面的样式,维护和更换风格更加方便。
缺点:
- 图片合并麻烦:合并图片需要手动调整和拼接小图标或背景图案,需要一定的工作量。
- 维护麻烦:如果需要修改其中一个小图标或背景图案,可能需要重新布局整个大图,并且需要更新相应的CSS样式。
总结:
CSS Sprite通过将多个小图片合并成一张大图,减少了HTTP请求,提高了页面加载速度和性能。它的优点包括减少请求数、提高性能、减小图片大小和方便更换风格。然而,它的缺点在于图片合并和维护的麻烦。
2 display: none;与visibility: hidden;的区别
display: none;和visibility: hidden;都可以使元素不可见,但它们在实现上有一些区别。
区别:
display: none;会使元素完全从渲染树中消失,不占据任何空间,而visibility: hidden;不会使元素从渲染树中消失,仍然占据空间,只是内容不可见。display: none;是非继承属性,子孙节点消失是因为元素本身从渲染树中消失,修改子孙节点的属性无法使其显示。而visibility: hidden;是继承属性,子孙节点消失是因为继承了hidden属性,通过设置visibility: visible;可以使子孙节点显示。- 修改具有常规流的元素的
display属性通常会导致文档重排(重新计算元素的位置和大小)。而修改visibility属性只会导致本元素的重绘(重新绘制元素的可见部分)。 - 读屏器(屏幕阅读软件)不会读取
display: none;元素的内容,但会读取visibility: hidden;元素的内容。
综上所述,
display: none;和visibility: hidden;虽然都可以使元素不可见,但在元素在渲染树中的位置、对子孙节点的影响、性能方面有所不同。选择使用哪种方式取决于具体的需求和场景。
3 link与@import的区别
<link>是HTML方式,@import是CSS方式。<link>标签在HTML文档的<head>部分中使用,用于引入外部CSS文件;@import是在CSS文件中使用,用于引入其他CSS文件。<link>标签最大限度地支持并行下载,浏览器会同时下载多个外部CSS文件;而@import引入的CSS文件会导致串行下载,浏览器会按照顺序逐个下载CSS文件,这可能导致页面加载速度变慢,出现FOUC(Flash of Unstyled Content)问题。<link>标签可以通过rel="alternate stylesheet"指定候选样式表,用户可以在浏览器中切换样式;而@import不支持rel属性,无法提供候选样式表功能。- 浏览器对
<link>标签的支持早于@import,一些古老的浏览器可能不支持@import方式引入CSS文件,而可以正确解析<link>标签。 @import必须出现在样式规则之前,而且只能在CSS文件的顶部引用其他文件;而<link>标签可以放置在文档的任何位置。- 总体来说,
<link>标签在性能、兼容性和灵活性方面优于@import。
因此,在实际使用中,推荐使用
<link>标签来引入外部CSS文件。
4 什么是FOUC?如何避免
FOUC(Flash Of Unstyled Content)指的是在页面加载过程中,由于外部样式表(CSS)加载较慢或延迟,导致页面先以无样式的方式显示,然后突然闪烁出样式的现象。
为了避免FOUC,可以采取以下方法:
- 将样式表放置在文档的
<head>标签中:通过将样式表放在文档头部,确保浏览器在渲染页面内容之前先加载和解析样式表,从而避免了页面一开始的无样式状态。 - 使用内联样式:将关键的样式直接写在HTML标签的
style属性中,这样即使外部样式表加载延迟,页面仍然可以有基本的样式展示,避免出现完全无样式的情况。 - 使用样式预加载:在HTML的
<head>中使用<link rel="preload">标签,将样式表提前预加载,以确保在页面渲染之前样式表已经下载完毕。 - 避免过多的样式表和样式文件:减少页面中使用的样式表数量和样式文件大小,优化样式表的结构和规则,从而加快样式表的加载速度。
- 使用媒体查询避免不必要的样式加载:通过媒体查询(
@media)在适当的条件下加载特定的样式,避免在不需要的情况下加载不必要的样式。
综上所述,通过优化样式加载顺序、使用内联样式、样式预加载和合理使用媒体查询等方法,可以有效避免FOUC的出现,提供更好的用户体验。
5 如何创建块级格式化上下文(block formatting context),BFC有什么用
BFC(Block Formatting Context),块级格式化上下文,是一个独立的渲染区域,让处于 BFC 内部的元素与外部的元素相互隔离,使内外元素的定位不会相互影响
要创建一个块级格式化上下文(BFC),可以应用以下方法:
- 使用
float属性:将元素的float属性设置为除none以外的值,可以创建一个BFC。 - 使用
overflow属性:将元素的overflow属性设置为除visible以外的值,例如auto或hidden,可以创建一个BFC。 - 使用
display属性:将元素的display属性设置为inline-block、table-cell、table-caption等特定的值,可以创建一个BFC。 - 使用
position属性:将元素的position属性设置为absolute、fixed、relative或sticky,可以创建一个BFC。 - 使用
contain属性:将元素的contain属性设置为layout,可以创建一个BFC(仅适用于部分浏览器)。
在
IE下,Layout,可通过zoom:1触发
BFC布局与普通文档流布局区别 普通文档流布局:
- 浮动的元素是不会被父级计算高度
- 非浮动元素会覆盖浮动元素的位置
margin会传递给父级元素- 两个相邻元素上下的
margin会重叠
BFC布局规则:
- 浮动的元素会被父级计算高度(父级元素触发了
BFC) - 非浮动元素不会覆盖浮动元素的位置(非浮动元素触发了
BFC) margin不会传递给父级(父级触发BFC)- 属于同一个
BFC的两个相邻元素上下margin会重叠
开发中的应用
- 阻止
margin重叠 - 可以包含浮动元素 —— 清除内部浮动(清除浮动的原理是两个
div都位于同一个BFC区域之中) - 自适应两栏布局
- 可以阻止元素被浮动元素覆盖
6 display、float、position的关系
- 如果
display取值为none,那么position和float都不起作用,这种情况下元素不产生框 - 否则,如果
position取值为absolute或者fixed,框就是绝对定位的,float的计算值为none,display根据下面的表格进行调整。 - 否则,如果
float不是none,框是浮动的,display根据下表进行调整 - 否则,如果元素是根元素,
display根据下表进行调整 - 其他情况下
display的值为指定值 - 总结起来:绝对定位、浮动、根元素都需要调整
display

综上所述,display、float和position之间存在一定的关系,它们的取值会相互影响元素的布局和显示方式。根据不同的取值组合,元素的display值可能会被调整。
7 清除浮动的几种方式,各自的优缺点
以下是清除浮动的几种常见方式以及它们的优缺点:
- 父级
div定义height: 将父级容器的高度设置为已浮动元素的高度。优点是简单易实现,缺点是需要提前知道浮动元素的高度,如果高度发生变化,需要手动调整。 - 结尾处加空
div标签clear:both: 在浮动元素后面添加一个空的div标签,并设置clear:both。优点是简单易实现,缺点是需要添加多余的空标签,不符合语义化。 - 父级
div定义伪类:after和zoom: 父级容器使用伪元素:after清除浮动,并设置zoom:1触发hasLayout。优点是不需要额外添加多余的标签,清除浮动效果好,缺点是对老版本浏览器的兼容性需要考虑。 - 父级
div定义overflow:hidden: 将父级容器的overflow属性设置为hidden。优点是简单易实现,不需要添加额外的标签,缺点是可能会造成内容溢出隐藏。 - 父级
div也浮动,需要定义宽度: 将父级容器也设置为浮动,并定义宽度。优点是清除浮动效果好,缺点是需要定义宽度,不够灵活。 - 结尾处加
br标签clear:both: 在浮动元素后面添加br标签,并设置clear:both。和第2种方式类似,优缺点也相似。 - 使用 clearfix 类: 在父级容器上应用 clearfix 类,该类包含伪元素清除浮动。优点是代码简洁易懂,不需要额外添加标签,缺点是需要定义并引用
clearfix类。
总体而言,使用伪类
:after和zoom的方式是较为常见和推荐的清除浮动的方法,它可以避免添加多余的标签,并具有较好的兼容性。然而,不同场景下适合使用不同的清除浮动方式,需要根据实际情况选择合适的方法。
8 为什么要初始化CSS样式?
初始化 CSS 样式的目的主要有以下几点:
- 浏览器兼容性: 不同浏览器对于 HTML 元素的默认样式存在差异,通过初始化 CSS 样式,可以尽量消除不同浏览器之间的显示差异,使页面在各个浏览器中更加一致。
- 统一样式: 通过初始化 CSS 样式,可以为各个元素提供一个统一的基础样式,避免默认样式的影响。这有助于开发者在项目中构建一致的界面风格,提高开发效率。
- 提高可维护性: 初始化 CSS 样式可以避免在编写具体样式时受到浏览器默认样式的干扰,减少不必要的样式覆盖和调整,从而提高代码的可维护性和可读性。
- 优化性能: 通过初始化 CSS 样式,可以避免不必要的样式计算和渲染,减少浏览器的工作量,提升页面加载和渲染性能。
需要注意的是,在进行 CSS 样式初始化时,应该注意选择合适的方式和范围,避免过度初始化造成不必要的代码冗余和性能损耗。同时,针对具体项目和需求,可以选择使用已有的 CSS 初始化库或者自定义初始化样式。
9 css3有哪些新特性
CSS3引入了许多新特性,以下是其中一些常见的新特性:
- 新增选择器:例如
:nth-child()、:first-of-type、:last-of-type等,可以根据元素在父元素中的位置进行选择。 - 弹性盒模型:通过
display: flex;可以创建弹性布局,简化了元素的排列和对齐方式。 - 多列布局:使用
column-count和column-width等属性可以实现将内容分为多列显示。 - 媒体查询:通过
@media可以根据设备的特性和屏幕大小应用不同的样式规则。 - 个性化字体:使用
@font-face可以引入自定义字体,并在网页中使用。 - 颜色透明度:通过
rgba()可以设置颜色的透明度。 - 圆角:使用
border-radius可以给元素添加圆角效果。 - 渐变:使用
linear-gradient()可以创建线性渐变背景效果。 - 阴影:使用
box-shadow可以为元素添加阴影效果。 - 倒影:使用
box-reflect可以为元素添加倒影效果。 - 文字装饰:使用
text-stroke-color可以设置文字描边的颜色。 - 文字溢出:使用
text-overflow可以处理文字溢出的情况。 - 背景效果:使用
background-size可以控制背景图片的大小。 - 边框效果:使用
border-image可以为边框使用图片来创建特殊效果。 - 转换:使用
transform可以实现元素的旋转、倾斜、位移和缩放等变换效果。 - 平滑过渡:使用
transition可以为元素的属性变化添加过渡效果。 - 动画:通过
@keyframes和animation可以创建元素的动画效果。
CSS3引入了许多新的伪类,以下是一些常见的新增伪类:
:nth-child(n):选择父元素下的第n个子元素。:first-child:选择父元素下的第一个子元素。:last-child:选择父元素下的最后一个子元素。:nth-of-type(n):选择父元素下特定类型的第n个子元素。:first-of-type:选择父元素下特定类型的第一个子元素。:last-of-type:选择父元素下特定类型的最后一个子元素。:only-child:选择父元素下仅有的一个子元素。:only-of-type:选择父元素下特定类型的唯一一个子元素。:empty:选择没有任何子元素或者文本内容的元素。:target:选择当前活动的目标元素。:enabled:选择可用的表单元素。:disabled:选择禁用的表单元素。:checked:选择被选中的单选框或复选框。:focus:选择当前获取焦点的元素。:hover:选择鼠标悬停在上方的元素。:visited:选择已访问过的链接。:not(selector):选择不符合给定选择器的元素。
这些新增的伪类为选择元素提供了更多的灵活性和精确性,使得开发者能够更好地控制和样式化文档中的元素。
10 display有哪些值?说明他们的作用
display属性用于定义元素应该生成的框类型。以下是常见的display属性值及其作用:
block:将元素转换为块状元素,独占一行,可设置宽度、高度、边距等属性。inline:将元素转换为行内元素,不独占一行,只占据内容所需的空间,无法设置宽度、高度等块级属性。none:设置元素不可见,在渲染时将其完全隐藏,不占据任何空间。inline-block:使元素既具有行内元素的特性(不独占一行),又具有块级元素的特性(可设置宽度、高度等属性),可以看作是行内块状元素。list-item:将元素作为列表项显示,常用于有序列表(<ol>)和无序列表(<ul>)中,会添加列表标记。table:将元素作为块级表格显示,常用于构建表格布局,类似于<table>元素。inherit:规定应从父元素继承display属性的值,使元素继承父元素的框类型。
这些display属性值用于控制元素的外观和布局,通过选择适当的值可以实现不同的布局效果。
11 介绍一下标准的CSS的盒子模型?低版本IE的盒子模型有什么不同的?
- 有两种,
IE盒子模型、W3C盒子模型;- 盒模型:内容(content)、填充(
padding)、边界(margin)、 边框(border);- 区 别: IE
的content部分把border和padding`计算了进去;
- 盒子模型构成:内容(
content)、内填充(padding)、 边框(border)、外边距(margin) IE8及其以下版本浏览器,未声明DOCTYPE,内容宽高会包含内填充和边框,称为怪异盒模型(IE盒模型)- 标准(
W3C)盒模型:元素宽度 =width + padding + border + margin - 怪异(
IE)盒模型:元素宽度 =width + margin - 标准浏览器通过设置 css3 的
box-sizing: border-box属性,触发“怪异模式”解析计算宽高
box-sizing 常用的属性有哪些?分别有什么作用
box-sizing属性用于控制元素的盒模型类型,常用的属性值有:
content-box:默认值,使用标准的W3C盒模型,元素的宽度和高度仅包括内容区域(content),不包括填充、边框和外边距。border-box:使用怪异的IE盒模型,元素的宽度和高度包括内容区域(content)、填充(padding)和边框(border),但不包括外边距(margin)。即元素的宽度和高度指定的是内容区域加上填充和边框的总宽度和高度。inherit:继承父元素的box-sizing属性值。
通过设置不同的box-sizing属性值,可以控制元素的盒模型类型,进而影响元素的布局和尺寸计算。使用border-box可以更方便地处理元素的宽度和高度,特别适合响应式布局和网格系统的设计。
12 CSS优先级算法如何计算?
CSS优先级是用于确定当多个样式规则应用到同一个元素时,哪个样式规则会被应用的一种规则。优先级的计算基于选择器的权重。
以下是CSS优先级计算的一般规则:
!important:样式规则使用了!important标记,具有最高优先级,无论其位置在哪里。- 内联样式:直接应用在元素上的
style属性具有较高的优先级。 - ID选择器:使用ID选择器的样式规则具有较高的优先级。例如,
#myElement。 - 类选择器、属性选择器和伪类选择器:使用类选择器(例如
.myClass)、属性选择器(例如[type="text"])和伪类选择器(例如:hover)的样式规则的优先级较低于ID选择器。 - 元素选择器和伪元素选择器:使用元素选择器(例如
div)和伪元素选择器(例如::before)的样式规则的优先级较低于类选择器、属性选择器和伪类选择器。
当存在多个样式规则具有相同的优先级时,会根据以下规则进行决定:
- 就近原则:当同一元素上存在多个具有相同优先级的样式规则时,最后出现的样式规则将被应用。
- 继承:某些样式属性可以被子元素继承,如果父元素具有样式规则,子元素将继承该样式。
需要注意的是,以上规则仅适用于一般情况,有些情况下可能存在更复杂的优先级计算。同时,使用!important应该谨慎,过度使用!important可能导致样式管理困难和维护问题。
13 对BFC规范的理解?
- 一个页面是由很多个
Box组成的,元素的类型和display属性,决定了这个Box的类型- 不同类型的
Box,会参与不同的Formatting Context(决定如何渲染文档的容器),因此Box内的元素会以不同的方式渲染,也就是说BFC内部的元素和外部的元素不会互相影响
BFC(Block Formatting Context)是CSS中的一种渲染规范,用于决定和控制元素在文档中的布局和渲染方式。BFC定义了一个独立的渲染区域,使得处于不同BFC内部的元素相互隔离,互不影响。
以下是对BFC规范的一些理解:
- BFC的创建条件:触发BFC的条件包括元素的
float属性不为none、position属性为absolute或fixed、display属性为inline-block、table-cell、table-caption等,以及通过特定的CSS属性(如overflow)进行触发。 - BFC的特性:
- 内部的块级盒子会在垂直方向上一个接一个地放置。
- 相邻的两个块级盒子的垂直外边距会发生合并。
- BFC的区域不会与浮动元素重叠。
- BFC在页面布局时会考虑浮动元素。
- BFC可以包含浮动元素,并计算其高度。
- BFC的边界会阻止边距重叠。
- BFC的应用:
- 清除浮动:创建一个父级元素成为BFC,可以清除其内部浮动的影响,避免父元素塌陷。
- 创建自适应的两栏布局:通过将两个列容器设置为BFC,可以避免它们相互影响。
- 阻止边距重叠:当两个相邻元素的边距发生重叠时,将其中一个元素设置为BFC,可以解决边距重叠问题。
总的来说,BFC规范通过创建独立的渲染上下文,使得元素的布局和渲染更加可控,避免了一些常见的布局问题和冲突。它在清除浮动、解决边距重叠等方面具有重要的应用价值。
14 谈谈浮动和清除浮动
浮动(float)是CSS中的一种布局方式,它允许元素向左或向右浮动并脱离文档的正常流,其他元素会围绕浮动元素进行布局。
浮动的特点和应用:
- 元素浮动后,其原位置会被其他元素填充,不再占据文档流中的空间。
- 浮动元素会尽可能地靠近其包含块的左侧或右侧,直到遇到另一个浮动元素或包含块的边界。
- 浮动元素可以通过设置
float属性为left或right进行左浮动或右浮动。 - 常见应用包括实现多列布局、文字环绕图片等。
清除浮动(clear float)是为了解决浮动元素带来的影响和布局问题而采取的措施。
浮动元素会导致其父元素的高度塌陷(父元素无法检测到浮动元素的高度),以及其他元素可能与浮动元素重叠。为了解决这些问题,可以使用清除浮动的方法:
- 空元素清除浮动:在浮动元素后面添加一个空的块级元素,并设置其
clear属性为both,使其在浮动元素下方换行,达到清除浮动的效果。 - 父级元素使用
overflow属性:给包含浮动元素的父元素设置overflow属性为auto或hidden,可以触发BFC(块格式化上下文),从而包含浮动元素。 - 使用伪元素清除浮动:使用
::after伪元素给包含浮动元素的父元素添加一个清除浮动的样式,例如设置content为空字符串、display为table等。 - 使用clearfix类:给包含浮动元素的父元素添加一个clearfix类,该类定义了清除浮动的样式,例如设置
clearfix类的::after伪元素清除浮动。
需要注意的是,清除浮动的方法应当适用于具体的布局需求和兼容性考虑。同时,清除浮动可能会影响到其他样式的布局,因此需要综合考虑和测试。
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
34 伪类和伪元素的区别
- 伪类表状态
- 伪元素是真的有元素
- 前者单冒号,后者双冒号
以下是对伪类和伪元素的更详细解释:
- 伪类(Pseudo-classes)是用于选择元素的特定状态或条件的关键词。它们以单冒号(
:)作为前缀,并应用于选择器的末尾。伪类选择器可以选择处于特定状态的元素,例如鼠标悬停、被点击、被选中等。常见的伪类包括:hover、:active、:visited、:nth-child等。 - 伪元素(Pseudo-elements)则是用于在文档中创建虚拟的元素,这些元素可以在选中的元素中添加额外的样式和内容。伪元素以双冒号(
::)作为前缀,并应用于选择器的末尾。伪元素可以在选中的元素中插入新的内容或样式,如在元素前、后插入内容或改变选中元素的某个部分的样式。常见的伪元素包括::before、::after、::first-line、::first-letter等。
总结来说,伪类用于选择特定状态的元素,而伪元素则用于在选中的元素中创建虚拟的元素。伪类以单冒号(:)作为前缀,伪元素以双冒号(::)作为前缀。在实际使用中,由于历史原因,有些伪元素也可以使用单冒号(:)来表示,但为了遵循最新的规范,推荐使用双冒号(::)表示伪元素。
35 base64的使用
- 用于减少
HTTP请求 - 适用于小图片
base64的体积约为原图的3/4
base64 是一种将二进制数据编码为 ASCII 字符串的方法,它常被用于将小文件(如图片、字体文件等)嵌入到 HTML、CSS 或 JavaScript 中,从而减少对服务器的请求次数。
使用 base64 编码可以将二进制文件转换为文本字符串,这样可以直接将字符串嵌入到代码中,而无需单独请求文件。这样做的好处是可以减少 HTTP 请求的数量,提升页面加载速度,尤其适用于小图片或者一些图标字体等。
然而,使用 base64 编码也有一些注意事项。由于 base64 编码后的文本字符串比原始二进制数据体积大约增加了 1/3,因此对于大文件来说,使用 base64 会导致数据传输量增加,可能会影响网页的加载速度。此外,由于嵌入了文件内容,导致代码体积增大,也会对可维护性产生一定的影响。
因此,通常建议将 base64 使用在小文件上,如小图标、小图片等,而对于大文件,仍然应该以原始文件的形式进行请求和传输,以获得更好的性能和可维护性。
36 自适应布局
思路:
- 左侧浮动或者绝对定位,然后右侧
margin撑开 - 使用
<div>包含,然后靠负margin形成bfc - 使用
flex
自适应布局是指能够根据不同设备或窗口尺寸自动调整布局的一种设计方式。下面是几种常见的自适应布局方法:
- 使用浮动或绝对定位:左侧元素使用浮动或绝对定位,右侧元素通过设置左侧元素的
margin来撑开布局。这种方法需要手动计算和设置宽度和间距,适用于简单的布局需求。
.left {
float: left;
width: 200px;
}
.right {
margin-left: 220px;
}
@前端进阶之旅: 代码已经复制到剪贴板
- 使用包含元素和负边距:将左右两个元素放在一个容器内,设置容器的
overflow属性为hidden,然后通过负边距将左侧元素向左移动,右侧元素则会自动占据剩余空间。这种方法需要使用负边距,适用于复杂布局需求。
.container {
overflow: hidden;
}
.left {
float: left;
width: 200px;
margin-left: -100%;
}
.right {
float: left;
}
@前端进阶之旅: 代码已经复制到剪贴板
- 使用 Flexbox 布局:使用 Flexbox 弹性布局可以轻松实现自适应布局。通过设置容器的
display属性为flex,并使用flex-grow属性来控制元素的伸缩性,可以自动调整元素的宽度和布局。
.container {
display: flex;
}
.left {
flex-grow: 0;
flex-shrink: 0;
width: 200px;
}
.right {
flex-grow: 1;
}
@前端进阶之旅: 代码已经复制到剪贴板
以上是一些常见的自适应布局方法,根据具体的需求和场景,可以选择合适的方法来实现自适应布局。
37 请用CSS写一个简单的幻灯片效果页面
知道是要用
CSS3。使用animation动画实现一个简单的幻灯片效果
/**css**/
.ani{
width:480px;
height:320px;
margin:50px auto;
overflow: hidden;
box-shadow:0 0 5px rgba(0,0,0,1);
background-size: cover;
background-position: center;
-webkit-animation-name: "loops";
-webkit-animation-duration: 20s;
-webkit-animation-iteration-count: infinite;
}
@-webkit-keyframes "loops" {
0% {
background:url(http://d.hiphotos.baidu.com/image/w%3D400/sign=c01e6adca964034f0fcdc3069fc27980/e824b899a9014c08e5e38ca4087b02087af4f4d3.jpg) no-repeat;
}
25% {
background:url(http://b.hiphotos.baidu.com/image/w%3D400/sign=edee1572e9f81a4c2632edc9e72b6029/30adcbef76094b364d72bceba1cc7cd98c109dd0.jpg) no-repeat;
}
50% {
background:url(http://b.hiphotos.baidu.com/image/w%3D400/sign=937dace2552c11dfded1be2353266255/d8f9d72a6059252d258e7605369b033b5bb5b912.jpg) no-repeat;
}
75% {
background:url(http://g.hiphotos.baidu.com/image/w%3D400/sign=7d37500b8544ebf86d71653fe9f9d736/0df431adcbef76095d61f0972cdda3cc7cd99e4b.jpg) no-repeat;
}
100% {
background:url(http://c.hiphotos.baidu.com/image/w%3D400/sign=cfb239ceb0fb43161a1f7b7a10a54642/3b87e950352ac65ce2e73f76f9f2b21192138ad1.jpg) no-repeat;
}
}
@前端进阶之旅: 代码已经复制到剪贴板
38 什么是外边距重叠?重叠的结果是什么?
外边距重叠就是margin-collapse
- 在CSS当中,相邻的两个盒子(可能是兄弟关系也可能是祖先关系)的外边距可以结合成一个单独的外边距。这种合并外边距的方式被称为折叠,并且因而所结合成的外边距称为折叠外边距。
折叠结果遵循下列计算规则:
- 两个相邻的外边距都是正数时,折叠结果是它们两者之间较大的值。
- 两个相邻的外边距都是负数时,折叠结果是两者绝对值的较大值。
- 两个外边距一正一负时,折叠结果是两者的相加的和。
下面是详细分析
外边距重叠(margin collapse)指的是在某些情况下,相邻的两个元素之间的外边距会发生合并,并且取两者之间的较大值作为最终的外边距值。外边距重叠主要发生在垂直方向上,而水平方向上的外边距不会发生重叠。
外边距重叠的结果是两个相邻元素的外边距被合并成一个单独的外边距,这可能会导致布局上的一些意外效果,比如元素之间的间距变得比预期的要大。
下面是一些常见情况下外边距重叠的例子:
- 相邻的兄弟元素的外边距重叠:
<div class="box"></div>
<div class="box"></div>
@前端进阶之旅: 代码已经复制到剪贴板
.box {
margin-top: 20px;
margin-bottom: 30px;
}
@前端进阶之旅: 代码已经复制到剪贴板
在这个例子中,两个相邻的兄弟元素之间的上下外边距会发生重叠,最终的外边距值为30px,而不是预期的50px。
- 父元素与第一个/最后一个子元素的外边距重叠:
<div class="parent">
<div class="child"></div>
</div>
@前端进阶之旅: 代码已经复制到剪贴板
.parent {
margin-bottom: 20px;
}
.child {
margin-top: 30px;
}
@前端进阶之旅: 代码已经复制到剪贴板
在这个例子中,父元素的下外边距和子元素的上外边距发生重叠,最终的外边距值为30px,而不是预期的50px。
了解外边距重叠的规则可以帮助我们更好地控制元素的布局,避免意外的外边距重叠效果。在需要避免外边距重叠的情况下,可以使用一些方法,如使用内边距(padding)或边框(border)来隔离外边距、使用浮动(float)或绝对定位(position)等。
39 rgba()和opacity的透明效果有什么不同?
rgba()是一种CSS颜色值表示方法,可以在其中指定红、绿、蓝三个通道的颜色值以及透明度。通过调整透明度值来实现元素的透明效果,仅影响元素的颜色或背景色,不影响元素内的其他内容的透明度。
.element {
background-color: rgba(255, 0, 0, 0.5); /* 半透明红色背景 */
}
@前端进阶之旅: 代码已经复制到剪贴板
opacity是CSS属性,用于设置元素的整体透明度。它会影响元素以及元素内的所有内容的透明度,包括文本、图像等。设置元素的透明度会影响整个元素及其内容的可见性。
.element {
opacity: 0.5; /* 元素及其内容半透明 */
}
@前端进阶之旅: 代码已经复制到剪贴板
需要注意的是,opacity 的值是一个0到1之间的数字,0表示完全透明,1表示完全不透明。而 rgba() 中的透明度值是一个介于0到1之间的数字,0表示完全透明,1表示完全不透明。
另外,需要注意的是,opacity 的透明度是继承的,子元素会继承父元素的透明度效果,而 rgba() 设置的透明度不会继承给子元素。
综上所述,rgba() 和 opacity 在实现透明效果上有一些不同,需要根据具体的需求和效果来选择使用哪种方式。
小结
rgba()和opacity都能实现透明效果,但最大的不同是opacity作用于元素,以及元素内的所有内容的透明度,- 而
rgba()只作用于元素的颜色或其背景色。(设置rgba透明的元素的子元素不会继承透明效果!)
40 css中可以让文字在垂直和水平方向上重叠的两个属性是什么?
- 垂直方向:
line-height - 水平方向:
letter-spacing
在CSS中,可以使用以下两个属性实现文字在垂直和水平方向上的重叠:
垂直方向:
line-height- 通过设置
line-height属性,可以控制行高,从而实现文字在垂直方向上的重叠。将line-height的值设置为大于文字大小的值,可以使文字垂直居中或与其他文字重叠。
.text { line-height: 1.5; /* 行高为文字大小的1.5倍 */ }@前端进阶之旅: 代码已经复制到剪贴板
- 通过设置
水平方向:
letter-spacing- 通过设置
letter-spacing属性,可以控制字符之间的间距,从而实现文字在水平方向上的重叠。将letter-spacing的值设置为负数,可以让字符紧密排列,产生重叠效果。
.text { letter-spacing: -2px; /* 字符间距为负数,产生重叠效果 */ }@前端进阶之旅: 代码已经复制到剪贴板
- 通过设置
这两个属性可以根据具体的需求来调整,实现文字的垂直和水平方向上的重叠效果。
41 如何垂直居中一个浮动元素?
垂直居中一个浮动元素可以使用以下两种方法:
方法一(已知元素的高宽):
#div1 {
background-color: #6699FF;
width: 200px;
height: 200px;
position: absolute; /* 父元素需要相对定位 */
top: 50%;
left: 50%;
margin-top: -100px; /* 二分之一的height */
margin-left: -100px; /* 二分之一的width */
}
@前端进阶之旅: 代码已经复制到剪贴板
方法二:
#div1 {
width: 200px;
height: 200px;
background-color: #6699FF;
margin: auto;
position: absolute; /* 父元素需要相对定位 */
left: 0;
top: 0;
right: 0;
bottom: 0;
}
@前端进阶之旅: 代码已经复制到剪贴板
对于垂直居中一个 <img>,可以使用更简便的方法:
#container {
display: flex;
justify-content: center;
align-items: center;
}
@前端进阶之旅: 代码已经复制到剪贴板
上述代码将 <img> 元素放置在一个容器中(#container),通过使用 Flex 布局的 justify-content: center; 和 align-items: center; 属性,实现了图片在容器中的垂直居中效果。
42 px和em的区别
px和em是两种不同的长度单位,它们的区别如下:
px(像素)是一个绝对单位,表示固定的像素大小。无论父元素的字体大小如何,px的值都不会改变,它是一个固定的长度单位。em(倍数)是一个相对单位,它相对于父元素的字体大小来确定自身的大小。如果没有设置字体大小,则1em等于浏览器默认的字体大小(通常是16px)。如果父元素的字体大小是16px,那么1em就等于16px,2em就等于32px,以此类推。
由于em是相对单位,它具有一定的灵活性和可扩展性。当需要调整整个页面的字体大小时,只需更改根元素的字体大小,其他使用em作为单位的元素会自动按比例调整大小,从而实现页面的整体缩放效果。
相对于px来说,em更适用于实现弹性布局、响应式设计以及根据用户偏好进行字体大小调整等场景。
小结
px和em都是长度单位,区别是,px的值是固定的,指定是多少就是多少,计算比较容易。em得值不是固定的,并且em会继承父级元素的字体大小。- 浏览器的默认字体高都是
16px。所以未经调整的浏览器都符合:1em=16px。那么12px=0.75em,10px=0.625em。
- px 相对于显示器屏幕分辨率,无法用浏览器字体放大功能
- em 值并不是固定的,会继承父级的字体大小: em = 像素值 / 父级font-size
43 Sass、LESS是什么?大家为什么要使用他们?
- 他们是
CSS预处理器。他是CSS上的一种抽象层。他们是一种特殊的语法/语言编译成CSS。 - 例如Less是一种动态样式语言. 将CSS赋予了动态语言的特性,如变量,继承,运算, 函数.
LESS既可以在客户端上运行 (支持IE 6+,Webkit,Firefox),也可一在服务端运行 (借助Node.js)
以下是为什么人们选择使用Sass和Less的一些原因:
- 变量和计算:Sass和Less都支持变量,可以定义和重用各种值,如颜色、字体、边距等。它们还允许进行数学计算,简化了样式表的编写和维护。
- 嵌套规则:Sass和Less允许在样式规则中嵌套其他规则,提高了样式表的可读性和可维护性。通过嵌套,可以更清晰地表示元素的层次结构,减少了样式选择器的重复。
- 混合(Mixins):混合是一种可以在多个选择器中重复使用的样式块。通过定义和调用混合,可以避免样式的重复编写,并且使样式表更加模块化和可复用。
- 继承:继承允许一个选择器继承另一个选择器的样式规则,减少了样式的冗余。当多个选择器具有相同的样式时,可以通过继承来避免重复编写样式。
- 模块化和导入:Sass和Less支持将样式表拆分为多个模块,并通过导入机制进行组合。这使得样式表的组织和管理更加灵活和可扩展。
- 自定义函数:Sass和Less都允许定义自定义函数,可以用于处理样式值,进行复杂的计算和操作。
- 强大的工具和生态系统:Sass和Less都有丰富的工具和插件生态系统,提供了许多辅助工具、编译器和构建工具,如预处理器编译器、自动刷新、自动前缀添加等,极大地提升了前端开发的效率。
总而言之,Sass和Less使得CSS的编写更加简洁、模块化和可维护,提供了一些高级功能和工具,使前端开发更加高效和灵活。
44 知道css有个content属性吗?有什么作用?有什么应用?
css的
content属性专门应用在before/after伪元素上,用于来插入生成内容。最常见的应用是利用伪类清除浮动。
/**一种常见利用伪类清除浮动的代码**/
.clearfix:after {
content:"."; //这里利用到了content属性
display:block;
height:0;
visibility:hidden;
clear:both;
}
.clearfix {
*zoom:1;
}
@前端进阶之旅: 代码已经复制到剪贴板
content属性主要用于在::before和::after伪元素中插入生成的内容。它通常与伪元素一起使用,以在文档中插入额外的内容或修饰样式。content属性可以接受多种类型的值,包括文本字符串、URL、计数器、计数器符号和引用标签等。通过设置不同的content值,可以实现一些常见的效果,例如:
- 插入文本内容:可以在伪元素中使用
content属性插入自定义的文本内容,用于装饰样式或添加额外的标识。 - 插入图标和符号:通过设置
content属性为某个图标字体或Unicode编码,可以在伪元素中插入图标和特殊符号。 - 计数器:结合使用
content属性和counter函数,可以在伪元素中显示自动生成的计数器,用于标记序号或计数。 - 引用标签:通过设置
content属性为attr()函数,可以在伪元素中引用元素的属性值,用于显示元素的属性内容。
上述代码示例中,通过设置content属性为一个点字符.,在::after伪元素中插入一个看不见的点,配合其他样式属性实现了清除浮动的效果。这是一种常见的清除浮动的技巧之一。
需要注意的是,content属性只对::before和::after伪元素起作用,对于其他元素并没有效果。此外,content属性必须与display属性一起使用,通常为block或inline-block,以确保生成的内容具有正确的布局。
45 水平居中的方法
- 元素为行内元素,设置父元素
text-align:center - 如果元素宽度固定,可以设置左右
margin为auto; - 绝对定位和移动:
absolute + transform - 使用
flex-box布局,指定justify-content属性为center display设置为tabel-cell
下面进行详细说明:
- 文本居中:如果元素为行内元素,可以将父元素的
text-align属性设置为center,这样子元素就会水平居中对齐。
.parent {
text-align: center;
}
@前端进阶之旅: 代码已经复制到剪贴板
- 固定宽度的居中:如果元素宽度已知并固定,可以通过将左右
margin设置为auto来实现水平居中。
.element {
margin-left: auto;
margin-right: auto;
}
@前端进阶之旅: 代码已经复制到剪贴板
- 绝对定位和移动:可以使用绝对定位和
transform来实现水平居中。首先将元素的左边距和右边距都设置为auto,然后使用transform属性将元素向左平移50%。
.element {
position: absolute;
left: 50%;
transform: translateX(-50%);
}
@前端进阶之旅: 代码已经复制到剪贴板
- Flexbox布局:使用
display: flex将父元素设置为弹性容器,然后使用justify-content属性将子元素水平居中。
.parent {
display: flex;
justify-content: center;
}
@前端进阶之旅: 代码已经复制到剪贴板
- 表格布局:将父元素的
display属性设置为table-cell,并将text-align属性设置为center。
.parent {
display: table-cell;
text-align: center;
}
@前端进阶之旅: 代码已经复制到剪贴板
这些方法可以根据具体的布局需求和浏览器兼容性进行选择和使用。
46 垂直居中的方法
- 将显示方式设置为表格,
display:table-cell,同时设置vertial-align:middle - 使用
flex布局,设置为align-item:center - 绝对定位中设置
bottom:0,top:0,并设置margin:auto - 绝对定位中固定高度时设置
top:50%,margin-top值为高度一半的负值 - 文本垂直居中设置
line-height为height值 inline-block兄弟元素:通过在父元素中插入一个inline-block元素,并设置其垂直对齐方式为middle来实现垂直居中
- 表格布局:将父元素的display属性设置为table,并将子元素的display属性设置为table-cell,然后使用vertical-align属性将子元素垂直居中
- 未知高度的块级父子元素居中,模拟表格布局
- 缺点:IE67不兼容,父级
overflow:hidden失效
.parent {
display: table;
}
.child {
display: table-cell;
vertical-align: middle;
}
@前端进阶之旅: 代码已经复制到剪贴板
- Flexbox布局:将父元素的display属性设置为flex,并使用align-items属性将子元素垂直居中。
.parent {
display: flex;
align-items: center;
}
@前端进阶之旅: 代码已经复制到剪贴板
- 绝对定位和负边距:对于已知高度的子元素,将父元素设置为相对定位,子元素设置为绝对定位,并使用
top: 50%将其垂直居中,然后通过负边距的方式将子元素向上移动一半的高度
.parent {
position: relative;
}
.child {
position: absolute;
top: 50%;
margin-top: -50px; /* 假设子元素高度为100px的一半 */
}
@前端进阶之旅: 代码已经复制到剪贴板
- 文本垂直居中:对于单行文本,可以设置父元素的line-height属性和高度相等,从而实现文本的垂直居中
.parent {
height: 100px;
line-height: 100px;
}
@前端进阶之旅: 代码已经复制到剪贴板
- CSS3位移:使用CSS3的transform属性的translateY函数将子元素向上位移一半的高度实现垂直居中
.child {
position: absolute;
top: 50%;
transform: translateY(-50%);
}
@前端进阶之旅: 代码已经复制到剪贴板
- inline-block兄弟元素:通过在父元素中插入一个inline-block元素,并设置其垂直对齐方式为middle来实现垂直居中
.parent {
height: 100%;
}
.extra {
display: inline-block;
vertical-align: middle;
}
.child {
display: inline-block;
vertical-align: middle;
}
@前端进阶之旅: 代码已经复制到剪贴板
47 如何使用CSS实现硬件加速?
硬件加速是指通过创建独立的复合图层,让GPU来渲染这个图层,从而提高性能,
一般触发硬件加速的CSS属性有transform、opacity、filter,为了避免2D动画在开始和结束的时候的repaint操作,一般使用tranform:translateZ(0)
使用CSS实现硬件加速可以通过以下方法:
- 使用3D变换:通过应用3D变换,如
translateZ(0),来触发硬件加速。这会将元素视为3D空间中的一个对象,使浏览器使用GPU进行渲染。
.element {
transform: translateZ(0);
}
@前端进阶之旅: 代码已经复制到剪贴板
- 使用CSS动画:使用CSS动画属性(如
transform、opacity、filter)来触发硬件加速。这可以通过创建一个动画并将其应用于元素来实现。
.element {
animation: myAnimation 1s linear infinite;
}
@keyframes myAnimation {
0% {
transform: translateZ(0);
}
100% {
transform: translateZ(0);
}
}
@前端进阶之旅: 代码已经复制到剪贴板
- 使用CSS过渡:通过使用CSS过渡属性(如
transform、opacity、filter)来触发硬件加速。这可以通过设置过渡效果来实现。
.element {
transition: transform 0.3s ease;
}
.element:hover {
transform: translateZ(0);
}
@前端进阶之旅: 代码已经复制到剪贴板
请注意,硬件加速并不是适用于所有情况的解决方案,它对于涉及大量动画或复杂渲染的元素特别有效。但是,在某些情况下,过多地使用硬件加速可能会导致性能问题,因此需要在实际使用时进行评估和测试。
48 重绘和回流(重排)是什么,如何避免?
重绘(Repaint)和回流(Reflow)是浏览器在渲染页面时的两个关键过程。
- 重绘(Repaint) 是指当元素的外观属性(如颜色、背景等)发生改变,但不影响布局时的重新绘制过程。重绘不会影响元素的几何尺寸和位置。
- 回流(Reflow) 是指当元素的布局属性(如尺寸、位置、隐藏/显示等)发生改变,导致浏览器重新计算元素的几何属性,重新构建渲染树的过程。回流会导致其他相关元素的回流和重绘。
- 回流必将引起重绘,而重绘不一定会引起回流
避免重绘和回流对于提高页面性能和响应速度至关重要。以下是一些减少重绘和回流的方法:
- 使用 CSS3 动画:使用 CSS3 的
transform和opacity等属性来创建动画效果,因为它们会触发硬件加速,减少重绘和回流的影响。 - 批量修改样式:避免频繁修改单个元素的样式,尽可能将修改合并为一次操作,可以使用
class或修改style属性的方式。 - 使用文档片段:当需要添加多个 DOM 元素到文档中时,可以先创建一个文档片段(
DocumentFragment),将元素添加到片段中,然后再将片段一次性添加到文档中,减少回流次数。 - 使用离线 DOM:将元素从文档中移除(
display: none),进行复杂的操作(如修改样式、添加子元素等),完成后再将元素放回文档,以减少回流和重绘的影响。 - 缓存布局属性值:如果需要多次访问某个元素的布局属性(如位置、尺寸等),可以将其值缓存起来,避免多次触发回流计算。
- 避免强制同步布局:避免在 JavaScript 中获取布局属性(如使用
offsetTop、clientWidth等),因为它会强制同步计算布局信息,触发回流。如果需要获取布局信息,最好将获取操作放在一起,或使用getBoundingClientRect()方法。
通过合理的设计和优化,可以最小化重绘和回流的次数,提高页面性能和用户体验。
49 说一说css3的animation
CSS3的animation属性是用于创建动画效果的一种方式。它可以通过关键帧(@keyframes)来定义动画的每一帧,以实现元素的平滑过渡和动态效果。
使用animation属性时,需要设置以下几个关键的子属性:
animation-name:定义动画的名称,对应@keyframes中的动画名。animation-duration:定义动画的持续时间,可以设置为具体的时间值,如2s表示2秒,或者使用关键词infinite表示无限循环。animation-timing-function:定义动画的时间函数,控制动画在不同时间点的速度变化,常见的取值有linear(线性)、ease(缓入缓出)、ease-in(缓入)、ease-out(缓出)、ease-in-out(缓入缓出)等。animation-delay:定义动画的延迟时间,即动画开始之前的等待时间。animation-iteration-count:定义动画的循环次数,可以设置为具体的次数,或者使用关键词infinite表示无限循环。animation-direction:定义动画的播放方向,包括正常播放(normal)、反向播放(reverse)、交替反向播放(alternate)等。animation-fill-mode:定义动画播放之前和之后的样式状态,包括保持初始状态(none)、保持最后状态(forwards)、保持初始和最后状态(both)等。animation-play-state:定义动画的播放状态,可以控制动画的暂停和继续播放,包括paused(暂停)和running(运行)。
通过调整这些子属性的取值,可以创建各种不同的动画效果,使元素在页面上实现平滑的过渡和动态的效果。CSS3的animation提供了一种简洁、易用且高性能的方式来实现动画效果,减少了对JavaScript的依赖。
50 左边宽度固定,右边自适应
左侧固定宽度,右侧自适应宽度的两列布局实现
html结构
<div class="outer">
<div class="left">固定宽度</div>
<div class="right">自适应宽度</div>
</div>
@前端进阶之旅: 代码已经复制到剪贴板
在外层
div(类名为outer)的div中,有两个子div,类名分别为left和right,其中left为固定宽度,而right为自适应宽度
方法1:左侧div设置成浮动:float: left,右侧div宽度会自动适应
.outer {
width: 100%;
height: 500px;
background-color: yellow;
}
.left {
width: 200px;
height: 200px;
background-color: red;
float: left;
}
.right {
height: 200px;
background-color: blue;
}
@前端进阶之旅: 代码已经复制到剪贴板
方法2:对右侧:div进行绝对定位,然后再设置right=0,即可以实现宽度自适应
绝对定位元素的第一个高级特性就是其具有自动伸缩的功能,当我们将
width设置为auto的时候(或者不设置,默认为auto),绝对定位元素会根据其left和right自动伸缩其大小
.outer {
width: 100%;
height: 500px;
background-color: yellow;
position: relative;
}
.left {
width: 200px;
height: 200px;
background-color: red;
}
.right {
height: 200px;
background-color: blue;
position: absolute;
left: 200px;
top:0;
right: 0;
}
@前端进阶之旅: 代码已经复制到剪贴板
方法3:将左侧div进行绝对定位,然后右侧div设置margin-left: 200px
.outer {
width: 100%;
height: 500px;
background-color: yellow;
position: relative;
}
.left {
width: 200px;
height: 200px;
background-color: red;
position: absolute;
}
.right {
height: 200px;
background-color: blue;
margin-left: 200px;
}
@前端进阶之旅: 代码已经复制到剪贴板
方法4:使用flex布局
.outer {
width: 100%;
height: 500px;
background-color: yellow;
display: flex;
flex-direction: row;
}
.left {
width: 200px;
height: 200px;
background-color: red;
}
.right {
height: 200px;
background-color: blue;
flex: 1;
}
@前端进阶之旅: 代码已经复制到剪贴板
51 两种以上方式实现已知或者未知宽度的垂直水平居中
/** 1 **/
.wraper {
position: relative;
.box {
position: absolute;
top: 50%;
left: 50%;
width: 100px;
height: 100px;
margin: -50px 0 0 -50px;
}
}
/** 2 **/
.wraper {
position: relative;
.box {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}
}
/** 3 **/
.wraper {
.box {
display: flex;
justify-content:center;
align-items: center;
height: 100px;
}
}
/** 4 **/
.wraper {
display: table;
.box {
display: table-cell;
vertical-align: middle;
}
}
@前端进阶之旅: 代码已经复制到剪贴板
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
72 margin和padding分别适合什么场景使用
margin 和 padding 在布局和样式设计中有不同的用途和适用场景。
适合使用 margin 的场景:
- 创建元素之间的空白间距,用于调整元素之间的间隔。
- 添加外部空白,使元素与周围的元素或容器之间产生间距。
- 用于调整元素的定位和对齐。
- 用于调整元素的外边距折叠效果(当相邻元素的外边距相遇时)。
适合使用 padding 的场景:
- 在元素的内部添加空白区域,用于调整元素内部内容与边框之间的距离。
- 用于创建元素的背景色或背景图的填充区域。
- 用于调整元素的内边距,影响元素内容与边框的距离。
- 用于控制元素的尺寸和布局。
需要根据具体的设计需求和布局目标来决定使用 margin 还是 padding。在一些情况下,它们可以互相替代使用,但在其他情况下,选择正确的属性可以更好地控制布局和样式效果。
73 抽离样式模块怎么写,说出思路
抽离样式模块的思路可以按照以下步骤进行:
- 识别公共样式:分析页面中多个模块或页面之间共享的样式,例如颜色、字体、按钮样式等,将其提取为公共样式。
- 创建公共样式表:将公共样式抽离到单独的样式表文件中,例如
common.css,以便在多个页面或模块中引用。 - 定义命名规范:为业务样式定义统一的命名规范,例如使用 BEM(Block-Element-Modifier)或其他命名约定,确保样式模块的可维护性和可扩展性。
- 拆分业务样式:根据页面或模块的功能和结构,将样式拆分为多个模块,并命名为相应的类名或选择器。每个模块应只关注自身的样式,并尽量避免与其他模块产生冲突。
- 创建样式模块文件:为每个样式模块创建单独的样式文件,例如
header.css、sidebar.css等,并按需引入到页面中。 - 构建样式层级结构:根据页面或模块的结构和层级关系,合理组织样式文件的引入顺序,确保样式的层叠顺序和继承关系正确。
- 统一管理样式文件:根据项目需要,可以使用构建工具(如 webpack、gulp 等)进行样式文件的合并、压缩和打包,减少网络请求和提升页面加载速度。
- 维护和更新:在日常开发中,根据需求的变化和新功能的添加,及时更新和维护样式模块,保持样式的一致性和可复用性。
通过以上步骤,可以将样式按照模块化的方式进行抽离和管理,提高代码的可读性、可维护性和重用性。同时,样式模块的拆分也有助于团队协作和并行开发。
74 元素竖向的百分比设定是相对于容器的高度吗
实际上,元素竖向的百分比设定是相对于包含它的父元素的高度,而不是宽度。当给一个元素设置竖向的百分比高度时,它会根据其父元素的高度进行计算。例如,如果一个元素的高度设置为50%,则表示该元素的高度将是其父元素高度的50%。
请注意,如果父元素没有明确设置高度,或者父元素的高度是由其内容决定的(如默认的height: auto),那么百分比高度可能无效,因为无法确定相对的基准高度。
需要注意的是,元素的宽度百分比设定是相对于包含它的父元素的宽度。因此,元素的百分比设定在竖向和横向方向上是不同的。
75 全屏滚动的原理是什么? 用到了CSS的那些属性
全屏滚动(Full Page Scroll)的原理是通过设置页面的高度为视口高度,并使用滚动事件来控制页面的滚动效果。通过监听滚动事件,当用户滚动页面时,根据滚动的距离来切换页面的显示内容,实现页面的切换效果。
在实现全屏滚动时,可能会用到以下一些CSS属性:
overflow: hidden;:用于隐藏超出视口范围的内容,以实现滚动效果。transform: translate(100%, 100%);:通过translate属性将页面移动到视口之外,从而隐藏页面的初始位置。display: none;:可以将页面的初始状态设置为隐藏,待滚动到相应位置时再显示。
这些属性可以结合使用,根据滚动事件的触发来控制页面的显示和隐藏,从而实现全屏滚动的效果。具体的实现方式可能因应用场景而有所差异。
76 什么是响应式设计?响应式设计的基本原理是什么?如何兼容低版本的IE
- 响应式设计就是网站能够兼容多个终端,而不是为每个终端做一个特定的版本
- 基本原理是利用CSS3媒体查询,为不同尺寸的设备适配不同样式
- 对于低版本的IE,可采用JS获取屏幕宽度,然后通过
resize方法来实现兼容:
$(window).resize(function () {
screenRespond();
});
screenRespond();
function screenRespond(){
var screenWidth = $(window).width();
if(screenWidth <= 1800){
$("body").attr("class", "w1800");
}
if(screenWidth <= 1400){
$("body").attr("class", "w1400");
}
if(screenWidth > 1800){
$("body").attr("class", "");
}
}
@前端进阶之旅: 代码已经复制到剪贴板
77 什么是视差滚动效果,如何给每页做不同的动画
视差滚动效果是一种在网页中使用的动画效果,通过在滚动页面时,不同层级的元素以不同的速度移动,形成立体的运动效果。这种效果可以给用户带来更加丰富、生动的视觉体验。
实现视差滚动效果时,可以将页面划分为背景层、内容层和悬浮层等不同的层级。通过设置不同层级的元素以不同的速度移动,可以形成层次感和立体效果。
具体实现视差滚动效果的方法如下:
- 使用HTML和CSS创建页面的不同层级,如背景层、内容层和悬浮层。
- 监听滚动事件(如鼠标滚轮事件或触摸滑动事件)。
- 当滚动事件触发时,根据滚动的距离和速度,计算出不同层级元素的位移值。
- 使用CSS的
transform属性或JavaScript的动画库(如GSAP、ScrollMagic等)来实现元素的平移或缩放效果。 - 根据需求,为每个页面或元素设置不同的动画效果,如淡入淡出、旋转、缩放等。
- 根据滚动的进度和方向,控制元素的动画播放顺序和速度,以达到预期的视差滚动效果。
需要注意的是,在实现视差滚动效果时,要考虑到性能和用户体验。过多或复杂的动画效果可能会影响页面加载和滚动的流畅性,因此需要谨慎选择和设计动画效果,并进行性能优化,如合理使用硬件加速、使用节流和防抖等技术手段。
另外,为每个页面或元素设置不同的动画效果可以根据具体的设计需求来确定。可以根据页面的主题、内容或目的来决定使用何种动画效果,如淡入淡出效果、元素的移动或旋转效果等,以增加页面的吸引力和交互性。可以通过CSS的animation属性或JavaScript的动画库来实现这些动画效果,并根据滚动进度或其他触发条件来控制动画的播放。
总结
- 视差滚动是指多层背景以不同的速度移动,形成立体的运动效果,具有非常出色的视觉体验
- 一般把网页解剖为:背景层、内容层和悬浮层。当滚动鼠标滚轮时,各图层以不同速度移动,形成视差的
- 实现原理
- 以 “页面滚动条” 作为 “视差动画进度条”
- 以 “滚轮刻度” 当作 “动画帧度” 去播放动画的
- 监听 mousewheel 事件,事件被触发即播放动画,实现“翻页”效果
78 a标签上四个伪类的执行顺序是怎么样的
伪类在a标签上的执行顺序是 link(未访问链接) -> visited(已访问链接) -> hover(鼠标悬停) -> active(激活状态)。
执行顺序可以用记忆口诀 "L-V-H-A"(Love Hate)来记忆,表示喜欢和讨厌的顺序。首先应用 link 样式,然后是 visited 样式,接着是 hover 样式,最后是 active 样式。这个顺序也是 CSS 解析和应用伪类样式的规定顺序。
79 伪元素和伪类的区别和作用
- 伪元素 – 在内容元素的前后插入额外的元素或样式,但是这些元素实际上并不在文档中生成。
- 它们只在外部显示可见,但不会在文档的源代码中找到它们,因此,称为“伪”元素。例如:
p::before {content:"第一章:";}
p::after {content:"Hot!";}
p::first-line {background:red;}
p::first-letter {font-size:30px;}
@前端进阶之旅: 代码已经复制到剪贴板
- 伪类 – 将特殊的效果添加到特定选择器上。它是已有元素上添加类别的,不会产生新的元素。例如:
a:hover {color: #FF00FF}
p:first-child {color: red}
@前端进阶之旅: 代码已经复制到剪贴板
80 ::before 和 :after 中双冒号和单冒号有什么区别
- 在 CSS 中伪类一直用
:表示,如:hover,:active等 - 伪元素在CSS1中已存在,当时语法是用
:表示,如:before和:after - 后来在CSS3中修订,伪元素用
::表示,如::before和::after,以此区分伪元素和伪类 - 由于低版本IE对双冒号不兼容,开发者为了兼容性各浏览器,继续使使用
:after这种老语法表示伪元素 - 总结起来,
::before是CSS3中写伪元素的新语法,而:after是早期版本CSS中存在的、兼容IE的旧语法,用于表示伪元素。在实际开发中,为了兼容性考虑,可以选择使用单冒号的写法。
81 如何修改Chrome记住密码后自动填充表单的黄色背景
- 产生原因:由于Chrome默认会给自动填充的
input表单加上input:-webkit-autofill私有属性造成的 - 解决方案1:在
form标签上直接关闭了表单的自动填充:autocomplete="off" - 解决方案2:
input:-webkit-autofill { background-color: transparent; }
input [type=search] 搜索框右侧小图标如何美化?
input[type="search"]::-webkit-search-cancel-button{
-webkit-appearance: none;
height: 15px;
width: 15px;
border-radius: 8px;
background:url("images/searchicon.png") no-repeat 0 0;
background-size: 15px 15px;
}
@前端进阶之旅: 代码已经复制到剪贴板
82 网站图片文件,如何点击下载?而非点击预览
可以通过在 <a> 标签中添加 href 属性来指定图片文件的路径,并使用 download 属性来指示浏览器下载该文件而非预览。
<a href="logo.jpg" download>下载</a>
@前端进阶之旅: 代码已经复制到剪贴板
上述代码会在网页中显示一个链接,点击该链接会下载名为 logo.jpg 的图片文件。
您还可以通过添加 download 属性的值来指定下载文件的名称,如下所示:
<a href="logo.jpg" download="网站LOGO">下载</a>
@前端进阶之旅: 代码已经复制到剪贴板
上述代码会下载名为 网站LOGO.jpg 的图片文件。
请注意,download 属性在某些浏览器中可能不被支持或具有限制。在不支持该属性的浏览器中,点击链接可能仍然会打开预览。此外,如果您在网站中使用了内容安全策略(Content Security Policy),可能需要额外配置才能允许下载文件。
确保文件路径正确,并根据需要设置适当的下载文件名称。
83 你对 line-height 是如何理解的
line-height是一行字的高度,包括了字体的实际高度以及行间距(字间距)。- 当一个元素没有显式设置
height属性时,它的高度会由line-height决定。 - 如果一个容器没有设置高度,并且容器内部有文本内容,那么容器的高度会由
line-height撑开。 - 如果将
line-height设置为与容器的height相同的值,可以实现单行文本的垂直居中。 - 注意,
line-height和height都可以撑开元素的高度,但是设置height属性会触发元素的haslayout(仅适用于部分浏览器),而line-height不会触发该特性。
需要注意的是,line-height 还可以影响多行文本的行间距和垂直居中,它是一个很常用的属性用于调整文本的排版和布局。
84 line-height 三种赋值方式有何区别?(带单位、纯数字、百分比)
对于 line-height 的三种赋值方式,如下所述:
- 带单位:使用像素 (
px) 或其他单位 (如em) 进行赋值。当使用固定值(如px)时,line-height会直接采用该固定值作为行高。而当使用相对单位(如em)时,line-height会根据元素的父元素的字体大小 (font-size) 来计算行高,即乘以相应的倍数。 - 纯数字:直接使用数字进行赋值。这种情况下,数字会被传递给后代元素,作为其行高的比例因子。例如,如果父元素的行高为
1.5,而子元素的字体大小为18px,那么子元素的行高就会被计算为1.5 * 18 = 27px。 - 百分比:使用百分比进行赋值。百分比值会相对于父元素的字体大小进行计算,并将计算后的值传递给后代元素作为其行高。
总的来说,带单位的方式是直接指定具体的行高值,纯数字和百分比的方式会将计算后的行高值传递给后代元素。这些不同的赋值方式可以根据具体的需求和设计效果来选择使用。
85 设置元素浮动后,该元素的 display 值会如何变化
- 设置元素浮动后,元素的
display值并不会自动变成block,而是保持原有的display值。浮动元素的display值仍然是根据元素的默认样式或通过 CSS 显式设置的值。 - 然而,浮动元素会生成一个块级框,并且脱离了正常的文档流,会影响其他元素的布局。常见的浮动值为
left或right,使元素向左或向右浮动,并允许其他内容环绕在其周围。 - 需要注意的是,对于一些内联元素,如
span、a等,默认的display值是inline,当设置这些内联元素为浮动时,会自动转换为block,但这并不适用于所有元素。
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
5 Javascript如何实现继承?
在 JavaScript 中,实现继承的方式有多种,包括构造继承、原型继承、实例继承和拷贝继承等。其中,使用构造函数与原型混合方式是较常用和推荐的方式。
以下是使用构造函数与原型混合方式实现继承的示例代码:
function Parent() {
this.name = 'poetry';
}
function Child() {
this.age = 28;
}
// 使用构造函数继承
Child.prototype = new Parent();
Child.prototype.constructor = Child;
var demo = new Child();
console.log(demo.age); // 输出: 28
console.log(demo.name); // 输出: poetry
console.log(demo.constructor); // 输出: Child
@前端进阶之旅: 代码已经复制到剪贴板
通过将 Child.prototype 设置为 new Parent(),子类 Child 继承了父类 Parent 的属性和方法。然后,通过手动将 Child.prototype.constructor 设置为 Child,确保子类的构造函数指向自身。
这样,demo.constructor 的输出将是 Child,表示 demo 实例的构造函数是 Child,以确保子类的实例通过 constructor 属性可以准确地识别其构造函数。
6 谈谈This对象的理解
- 在全局作用域中,
this指向全局对象(在浏览器环境中通常是window对象)。 - 在函数中,
this的值取决于函数的调用方式。- 如果函数是作为对象的方法调用,
this指向调用该方法的对象。 - 如果函数是作为普通函数调用,
this指向全局对象(非严格模式下)或undefined(严格模式下)。 - 如果函数是通过
call、apply或bind方法调用,this指向call、apply或bind方法的第一个参数所指定的对象。 - 如果函数是作为构造函数调用(使用
new关键字),this指向新创建的对象。
- 如果函数是作为对象的方法调用,
- 在箭头函数中,
this的值是继承自外部作用域的,它不会因为调用方式的改变而改变。
下面是一些示例代码,以说明 this 的不同情况:
// 全局作用域中的 this
console.log(this); // 输出: Window
// 对象方法中的 this
const obj = {
name: 'poetry',
sayHello: function() {
console.log(`Hello, ${this.name}!`);
}
};
obj.sayHello(); // 输出: Hello, poetry!
// 普通函数调用中的 this
function greeting() {
console.log(`Hello, ${this.name}!`);
}
greeting(); // 输出: Hello, undefined (非严格模式下输出: Hello, [全局对象的某个属性值])
// 使用 call/apply/bind 改变 this
const person = {
name: 'poetry'
};
greeting.call(person); // 输出: Hello, poetry!
greeting.apply(person); // 输出: Hello, poetry!
const boundGreeting = greeting.bind(person);
boundGreeting(); // 输出: Hello, poetry!
// 构造函数中的 this
function Person(name) {
this.name = name;
}
const poetry = new Person('poetry');
console.log(poetry.name); // 输出: poetry
// 箭头函数中的 this
const arrowFunc = () => {
console.log(this);
};
arrowFunc(); // 输出: Window
@前端进阶之旅: 代码已经复制到剪贴板
7 事件模型
事件流分为三个阶段:捕获阶段、目标阶段和冒泡阶段。
- 捕获阶段(Capture Phase):事件从最外层的父节点开始向下传递,直到达到目标元素的父节点。在捕获阶段,事件会经过父节点、祖父节点等,但不会触发任何事件处理程序。
- 目标阶段(Target Phase):事件到达目标元素本身,触发目标元素上的事件处理程序。如果事件有多个处理程序绑定在目标元素上,它们会按照添加的顺序依次执行。
- 冒泡阶段(Bubble Phase):事件从目标元素开始向上冒泡,传递到父节点,直到传递到最外层的父节点或根节点。在冒泡阶段,事件会依次触发父节点、祖父节点等的事件处理程序。
事件流的默认顺序是从目标元素的最外层父节点开始的捕获阶段,然后是目标阶段,最后是冒泡阶段。但是可以通过事件处理程序的绑定顺序来改变事件处理的执行顺序。
例如,以下代码演示了事件流的执行顺序:
<div id="outer">
<div id="inner">
<button id="btn">Click me</button>
</div>
</div>
@前端进阶之旅: 代码已经复制到剪贴板
var outer = document.getElementById('outer');
var inner = document.getElementById('inner');
var btn = document.getElementById('btn');
outer.addEventListener('click', function() {
console.log('Outer div clicked');
}, true); // 使用捕获阶段进行事件监听
inner.addEventListener('click', function() {
console.log('Inner div clicked');
}, false); // 使用冒泡阶段进行事件监听
btn.addEventListener('click', function() {
console.log('Button clicked');
}, false); // 使用冒泡阶段进行事件监听
@前端进阶之旅: 代码已经复制到剪贴板
当点击按钮时,事件的执行顺序如下:
- 捕获阶段:触发外层div的捕获事件处理程序。
- 目标阶段:触发按钮的事件处理程序。
- 冒泡阶段:触发内层div的冒泡事件处理程序。
输出结果为:
Outer div clicked
Button clicked
Inner div clicked
@前端进阶之旅: 代码已经复制到剪贴板
这个示例展示了事件流中捕获阶段、目标阶段和冒泡阶段的执行顺序。
可以通过
addEventListener方法的第三个参数来控制事件处理函数在捕获阶段或冒泡阶段执行,true表示捕获阶段,false或不传表示冒泡阶段。
8 new操作符具体干了什么呢?
- 创建一个空对象,并且
this变量引用该对象,同时还继承了该函数的原型 - 属性和方法被加入到
this引用的对象中 - 新创建的对象由
this所引用,并且最后隐式的返回this
实现一个简单的 new 方法,可以按照以下步骤进行操作:
- 创建一个新的空对象。
- 将新对象的原型链接到构造函数的原型对象。
- 将构造函数的作用域赋给新对象,以便在构造函数中使用
this引用新对象。 - 执行构造函数,并将参数传递给构造函数。
- 如果构造函数没有显式返回一个对象,则返回新对象。
function myNew(constructor, ...args) {
// 创建一个新的空对象
const newObj = {};
// 将新对象的原型链接到构造函数的原型对象
Object.setPrototypeOf(newObj, constructor.prototype);
// 将构造函数的作用域赋给新对象,并执行构造函数
const result = constructor.apply(newObj, args);
// 如果构造函数有显式返回一个对象,则返回该对象;否则返回新对象
return typeof result === 'object' && result !== null ? result : newObj;
}
@前端进阶之旅: 代码已经复制到剪贴板
使用上述自定义的 myNew 方法,可以实现与 new 操作符类似的效果,如下所示:
function Person(name, age) {
this.name = name;
this.age = age;
}
Person.prototype.sayHello = function() {
console.log('Hello, my name is ' + this.name);
};
var poetry = myNew(Person, 'poetry', 25);
console.log(poetry.name); // 输出: poetry
console.log(poetry.age); // 输出: 25
poetry.sayHello(); // 输出: Hello, my name is poetry
@前端进阶之旅: 代码已经复制到剪贴板
注意,这只是一个简化的实现,不考虑一些复杂的情况,例如原型链的继承和构造函数返回对象的情况。在实际应用中,建议使用内置的 new 操作符来创建对象实例,因为它处理了更多的细节和边界情况。
9 Ajax原理
Ajax的原理简单来说是在用户和服务器之间加了—个中间层(AJAX引擎),通过XmlHttpRequest对象来向服务器发异步请求,从服务器获得数据,然后用javascript来操作DOM而更新页面。使用户操作与服务器响应异步化。这其中最关键的一步就是从服务器获得请求数据Ajax的过程只涉及JavaScript、XMLHttpRequest和DOM。XMLHttpRequest是ajax的核心机制
// 手写简易ajax
/** 1. 创建连接 **/
var xhr = null;
xhr = new XMLHttpRequest()
/** 2. 连接服务器 **/
xhr.open('get', url, true)
/** 3. 发送请求 **/
xhr.send(null);
/** 4. 接受请求 **/
xhr.onreadystatechange = function(){
if(xhr.readyState == 4){
if(xhr.status == 200){
success(xhr.responseText);
} else {
/** false **/
fail && fail(xhr.status);
}
}
}
@前端进阶之旅: 代码已经复制到剪贴板
// promise封装
function ajax(url) {
const p = new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest()
xhr.open('GET', url, true)
xhr.onreadystatechange = function () {
if (xhr.readyState === 4) {
if (xhr.status === 200) {
resolve(
JSON.parse(xhr.responseText)
)
} else if (xhr.status === 404 || xhr.status === 500) {
reject(new Error('404 not found'))
}
}
}
xhr.send(null)
})
return p
}
@前端进阶之旅: 代码已经复制到剪贴板
// 测试
const url = '/data/test.json'
ajax(url)
.then(res => console.log(res))
.catch(err => console.error(err))
@前端进阶之旅: 代码已经复制到剪贴板
ajax 有那些优缺点?
- 优点:
- 通过异步模式,提升了用户体验.
- 优化了浏览器和服务器之间的传输,减少不必要的数据往返,减少了带宽占用.
Ajax在客户端运行,承担了一部分本来由服务器承担的工作,减少了大用户量下的服务器负载。Ajax可以实现动态不刷新(局部刷新)
- 缺点:
- 安全问题
AJAX暴露了与服务器交互的细节。 - 对搜索引擎的支持比较弱。
- 不容易调试。
- 安全问题
10 如何解决跨域问题?
首先了解下浏览器的同源策略 同源策略
/SOP(Same origin policy)是一种约定,由Netscape公司1995年引入浏览器,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,浏览器很容易受到XSS、CSRF等攻击。所谓同源是指"协议+域名+端口"三者相同,即便两个不同的域名指向同一个ip地址,也非同源
1. 通过jsonp跨域
封装一个可用的 JSONP 方法,可以参考以下示例代码:
function jsonp(url, params, callback) {
// 生成唯一的回调函数名
const callbackName = 'jsonp_' + Date.now();
// 将参数拼接到 URL 中
const queryString = Object.keys(params)
.map(key => encodeURIComponent(key) + '=' + encodeURIComponent(params[key]))
.join('&');
// 创建 script 元素
const script = document.createElement('script');
script.src = url + '?' + queryString + '&callback=' + callbackName;
// 定义回调函数
window[callbackName] = function(data) {
// 调用回调函数
callback(data);
// 删除 script 元素和回调函数
document.head.removeChild(script);
delete window[callbackName];
};
// 将 script 元素添加到页面中
document.head.appendChild(script);
}
@前端进阶之旅: 代码已经复制到剪贴板
使用示例:
jsonp('http://www.example.com/api', { user: 'admin' }, function(data) {
console.log(data);
});
@前端进阶之旅: 代码已经复制到剪贴板
这个 jsonp 函数接受三个参数:URL、参数对象和回调函数。它会生成一个唯一的回调函数名,并将参数拼接到 URL 中。然后创建一个 <script> 元素,并将 URL 设置为带有回调函数名的 URL。定义一个全局的回调函数,当响应返回时调用该回调函数,并将数据传递给回调函数。最后将 <script> 元素添加到页面中,触发跨域请求。当请求完成后,删除 <script> 元素和回调函数。
这样,你就可以通过封装的 JSONP 方法来实现跨域请求并获取响应数据了。
2. document.domain + iframe跨域
自
Chrome 101版本开始,document.domain将变为可读属性,也就是意味着上述这种跨域的方式被禁用了
此方案仅限主域相同,子域不同的跨域应用场景
1.)父窗口:(http://www.domain.com/a.html)
<iframe id="iframe" src="http://child.domain.com/b.html"></iframe>
<script>
document.domain = 'domain.com';
var user = 'admin';
</script>
@前端进阶之旅: 代码已经复制到剪贴板
2.)子窗口:(http://child.domain.com/b.html)
document.domain = 'domain.com';
// 获取父窗口中的变量
alert('get js data from parent ---> ' + window.parent.user);
@前端进阶之旅: 代码已经复制到剪贴板
3. nginx代理跨域
通过 Nginx 配置反向代理,将跨域请求转发到同源接口,从而避免浏览器的同源策略限制。
下面是一个示例配置,展示了如何通过 Nginx 实现跨域代理:
server {
listen 80;
server_name your-domain.com;
location /api {
# 设置代理目标地址
proxy_pass http://api.example.com;
# 设置允许的跨域请求头
add_header Access-Control-Allow-Origin $http_origin;
add_header Access-Control-Allow-Methods "GET, POST, OPTIONS";
add_header Access-Control-Allow-Credentials true;
add_header Access-Control-Allow-Headers "Origin, X-Requested-With, Content-Type, Accept";
# 处理预检请求(OPTIONS 请求)
if ($request_method = OPTIONS) {
return 200;
}
}
}
@前端进阶之旅: 代码已经复制到剪贴板
在上面的示例中,假设你的域名是 your-domain.com,需要代理访问 api.example.com。你可以将这个配置添加到 Nginx 的配置文件中。
这个配置会将 /api 路径下的请求代理到 http://api.example.com。同时,通过添加 Access-Control-Allow-* 头部,允许跨域请求的来源、方法、头部等。
这样,当你在前端发送请求到 /api 路径时,Nginx 会将请求代理到 http://api.example.com,并在响应中添加跨域相关的头部,从而解决跨域问题。注意要根据实际情况进行配置,包括监听的端口、域名和代理的目标地址等。
4. nodejs中间件代理跨域
使用 Node.js 构建一个中间件,在服务器端代理请求,将跨域请求转发到同源接口,然后将响应返回给前端。
可以使用 http-proxy-middleware 模块来创建一个简单的代理服务器。下面是一个示例代码:
const express = require('express');
const { createProxyMiddleware } = require('http-proxy-middleware');
const app = express();
// 创建代理中间件
const apiProxy = createProxyMiddleware('/api', {
target: 'http://api.example.com', // 设置代理目标地址
changeOrigin: true, // 修改请求头中的 Origin 为目标地址
pathRewrite: {
'^/api': '', // 重写请求路径,去掉 '/api' 前缀
},
// 可选的其他配置项...
});
// 将代理中间件应用到 '/api' 路径
app.use('/api', apiProxy);
// 启动服务器
app.listen(3000, () => {
console.log('Proxy server is running on port 3000');
});
@前端进阶之旅: 代码已经复制到剪贴板
在上面的示例中,首先使用 express 框架创建一个服务器实例。然后,使用 http-proxy-middleware 模块创建一个代理中间件。通过配置代理中间件的 target 选项,将请求代理到目标地址 http://api.example.com。
你可以通过其他可选的配置项来进行更多的定制,例如修改请求头、重写请求路径等。在这个示例中,我们将代理中间件应用到路径 /api 下,即当请求路径以 /api 开头时,会被代理到目标地址。
最后,启动服务器并监听指定的端口(这里是 3000)。
请确保你已经安装了 express 和 http-proxy-middleware 模块,并将上述代码保存为一个文件(例如 proxy-server.js)。然后通过运行 node proxy-server.js 来启动代理服务器。
现在,当你在前端发送请求到 /api 路径时,Node.js 代理服务器会将请求转发到 http://api.example.com,从而实现跨域访问。记得根据实际情况修改目标地址和端口号。
5. 后端在头部信息里面设置安全域名
后端可以在响应的头部信息中设置 Access-Control-Allow-Origin 字段,指定允许跨域访问的域名。例如,在 Node.js 中可以使用 cors 模块来实现:
const express = require('express');
const cors = require('cors');
const app = express();
// 允许所有域名跨域访问
app.use(cors());
// 其他路由和逻辑处理...
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
@前端进阶之旅: 代码已经复制到剪贴板
6. 通过webpack devserver代理
使用 webpack-dev-server 的代理功能可以实现在开发过程中的跨域请求。你可以配置 devServer 对象中的 proxy 选项来设置代理。下面是一个示例配置:
module.exports = {
// 其他配置项...
devServer: {
proxy: {
'/api': {
target: 'http://api.example.com', // 设置代理目标地址
pathRewrite: { '^/api': '' }, // 重写请求路径,去掉 '/api' 前缀
changeOrigin: true, // 修改请求头中的 Origin 为目标地址
},
},
},
};
@前端进阶之旅: 代码已经复制到剪贴板
在上面的示例中,我们配置了一个代理,将以 /api 开头的请求转发到 http://api.example.com。通过 pathRewrite 选项,我们去掉了请求路径中的 /api 前缀,以符合目标地址的接口路径。
将上述配置添加到你的 webpack.config.js 文件中,然后启动 webpack-dev-server。现在,当你在前端发送以 /api 开头的请求时,webpack-dev-server 会将请求转发到目标地址,并返回响应结果。
注意,这里的配置是针对开发环境下的代理,当你构建生产环境的代码时,代理配置不会生效。
请确保你已经安装了 webpack-dev-server,并在你的 package.json 文件的 scripts 中添加启动命令,例如:
{
"scripts": {
"start": "webpack-dev-server --open"
}
}
@前端进阶之旅: 代码已经复制到剪贴板
运行 npm start 或 yarn start 来启动 webpack-dev-server。
这样,通过配置 webpack-dev-server 的代理,你就可以在开发过程中实现跨域请求。记得根据实际情况修改目标地址和请求路径。
7. CORS(跨域资源共享)
在服务端设置响应头部,允许特定的域名或所有域名访问该资源。可以通过在响应头部中设置 Access-Control-Allow-Origin 字段来指定允许访问的域名。
示例代码(Node.js + Express):
const express = require('express');
const app = express();
// 允许所有域名访问
app.use((req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', '*');
next();
});
// 路由和处理逻辑
// ...
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
@前端进阶之旅: 代码已经复制到剪贴板
8. WebSocket
使用 WebSocket 协议进行通信,WebSocket 不受同源策略限制,因此可以在不同域之间进行双向通信。
示例代码(JavaScript):
const socket = new WebSocket('ws://example.com/socket');
socket.onopen = () => {
console.log('WebSocket connection established.');
// 发送数据
socket.send('Hello, server!');
};
socket.onmessage = (event) => {
console.log('Received message from server:', event.data);
};
socket.onclose = () => {
console.log('WebSocket connection closed.');
};
@前端进阶之旅: 代码已经复制到剪贴板
9. 代理服务器
在同一域名下,前端通过发送请求给同域下的代理服务器,然后由代理服务器转发请求到目标服务器,并将响应返回给前端,实现跨域请求。
示例代码(Node.js + Express):
const express = require('express');
const axios = require('axios');
const app = express();
app.get('/api/data', (req, res) => {
// 向目标服务器发送请求
axios.get('http://api.example.com/data')
.then((response) => {
// 将目标服务器的响应返回给前端
res.json(response.data);
})
.catch((error) => {
res.status(500).json({ error: 'An error occurred' });
});
});
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
@前端进阶之旅: 代码已经复制到剪贴板
11 模块化开发怎么做?
当涉及模块化开发时,有多种方法可供选择:
1. 立即执行函数模式:
- 使用立即执行函数来创建模块,将私有成员放在函数作用域内,不直接暴露给外部。
- 通过返回一个包含公共方法的对象,使这些方法可以在外部访问。
var module = (function() {
var privateVar = 'Private Variable';
function privateMethod() {
console.log('This is a private method');
}
function publicMethod() {
console.log('This is a public method');
}
return {
publicMethod: publicMethod
};
})();
module.publicMethod(); // Output: This is a public method
@前端进阶之旅: 代码已经复制到剪贴板
2. CommonJS:
- 使用
require导入模块,使用module.exports或exports导出模块。 - 适用于 Node.js 环境。
// math.js
function add(a, b) {
return a + b;
}
function subtract(a, b) {
return a - b;
}
module.exports = {
add,
subtract
};
@前端进阶之旅: 代码已经复制到剪贴板
// app.js
const math = require('./math');
console.log(math.add(2, 3)); // Output: 5
console.log(math.subtract(5, 2)); // Output: 3
@前端进阶之旅: 代码已经复制到剪贴板
3. ES Modules:
- 使用
import导入模块,使用export导出模块。 - 适用于现代浏览器环境和支持 ES6 模块的工具链。
// math.js
export function add(a, b) {
return a + b;
}
export function subtract(a, b) {
return a - b;
}
@前端进阶之旅: 代码已经复制到剪贴板
// app.js
import { add, subtract } from './math';
console.log(add(2, 3)); // Output: 5
console.log(subtract(5, 2)); // Output: 3
@前端进阶之旅: 代码已经复制到剪贴板
4. AMD(Asynchronous Module Definition):
- 使用
define定义模块,通过异步加载模块。 - 适用于浏览器环境和需要按需加载模块的场景。
// math.js
define([], function() {
function add(a, b) {
return a + b;
}
function subtract(a, b) {
return a - b;
}
return {
add,
subtract
};
});
@前端进阶之旅: 代码已经复制到剪贴板
// app.js
require(['math'], function(math) {
console.log(math.add(2, 3)); // Output: 5
console.log(math.subtract(5, 2)); // Output: 3
});
@前端进阶之旅: 代码已经复制到剪贴板
以上是常见的模块化开发方式,每种方式都有自己的特点和使用场景,可以根据具体需求选择适合的模块化规范。
12 异步加载JS的方式有哪些?
你提到的异步加载 JS 的方式都是常见且有效的方法。以下是对每种方式的简要介绍:
1. 设置<script>属性 async="async":
- 通过将
async属性设置为"async",脚本将异步加载并立即执行,不会阻塞页面的解析和渲染。 - 脚本加载完成后,将在页面中的任何位置立即执行。
<script src="script.js" async="async"></script>
@前端进阶之旅: 代码已经复制到剪贴板
2. 动态创建 script DOM:
- 使用 JavaScript 动态创建
<script>元素,并将其添加到文档中。 - 通过设置
src属性指定脚本的 URL,异步加载脚本。
var script = document.createElement('script');
script.src = 'script.js';
document.head.appendChild(script);
@前端进阶之旅: 代码已经复制到剪贴板
3. XmlHttpRequest 脚本注入:
- 使用
XmlHttpRequest对象加载脚本内容,并将其注入到页面中。 - 通过异步请求获取脚本内容后,使用
eval()函数执行脚本。
var xhr = new XMLHttpRequest();
xhr.open('GET', 'script.js', true);
xhr.onreadystatechange = function() {
if (xhr.readyState === 4 && xhr.status === 200) {
eval(xhr.responseText);
}
};
xhr.send();
@前端进阶之旅: 代码已经复制到剪贴板
4. 异步加载库 LABjs:
LABjs是一个用于异步加载 JavaScript 的库,可以管理和控制加载顺序。- 它提供了简洁的 API 来定义和加载依赖关系,以及控制脚本加载的时机。
$LAB
.script('script1.js')
.wait()
.script('script2.js');
@前端进阶之旅: 代码已经复制到剪贴板
5. 模块加载器 Sea.js:
Sea.js是一个用于 Web 端模块化开发的加载器,可以异步加载和管理模块依赖关系。- 它支持异步加载 JavaScript 模块,并在模块加载完成后执行回调函数。
seajs.use(['module1', 'module2'], function(module1, module2) {
// 执行依赖模块加载完成后的逻辑
});
@前端进阶之旅: 代码已经复制到剪贴板
6. Deferred Scripts(延迟脚本):
- 使用
<script>元素的defer属性可以将脚本延迟到文档解析完成后再执行。 - 延迟脚本会按照它们在文档中出现的顺序执行,但在
DOMContentLoaded事件触发之前执行。
<script src="script.js" defer></script>
@前端进阶之旅: 代码已经复制到剪贴板
7. Dynamic Import(动态导入):
- 使用动态导入语法
import()可以异步加载 JavaScript 模块。 - 这种方式返回一个 Promise 对象,可以通过
then()方法处理模块加载完成后的逻辑。
import('module.js')
.then(module => {
// 执行模块加载完成后的逻辑
})
.catch(error => {
// 处理加载失败的情况
});
@前端进阶之旅: 代码已经复制到剪贴板
8. Web Workers(Web 工作者):
Web Workers是运行在后台线程中的 JavaScript 脚本,可以进行耗时操作而不会阻塞主线程。- 可以使用
Web Workers异步加载和执行 JavaScript 脚本,以提高页面的响应性。
var worker = new Worker('worker.js');
worker.onmessage = function(event) {
// 处理从 Worker 返回的消息
};
worker.postMessage('start');
@前端进阶之旅: 代码已经复制到剪贴板
13 那些操作会造成内存泄漏?
JavaScript 内存泄露指对象在不需要使用它时仍然存在,导致占用的内存不能使用或回收
- 未使用
var声明的全局变量 - 闭包函数(
Closures) - 循环引用(两个对象相互引用)
- 控制台日志(
console.log) - 移除存在绑定事件的
DOM元素(IE) setTimeout的第一个参数使用字符串而非函数的话,会引发内存泄漏- 垃圾回收器定期扫描对象,并计算引用了每个对象的其他对象的数量。如果一个对象的引用数量为
0(没有其他对象引用过该对象),或对该对象的惟一引用是循环的,那么该对象的内存即可回收
下面是一些常见操作可能导致内存泄漏的示例代码:
- 未使用
var声明的全局变量:
function foo() {
bar = 'global variable'; // 没有使用 var 声明
}
foo();
@前端进阶之旅: 代码已经复制到剪贴板
- 闭包函数(Closures):
function outer() {
var data = 'sensitive data';
return function() {
// 内部函数形成了闭包
console.log(data);
};
}
var inner = outer();
inner(); // 闭包引用了外部函数的变量,导致变量无法被释放
@前端进阶之旅: 代码已经复制到剪贴板
- 循环引用:
function createObjects() {
var obj1 = {};
var obj2 = {};
obj1.ref = obj2;
obj2.ref = obj1;
// 对象之间形成循环引用,导致无法被垃圾回收
}
createObjects();
@前端进阶之旅: 代码已经复制到剪贴板
- 控制台日志(
console.log):
function processData(data) {
console.log(data); // 控制台日志可能会引用数据,阻止垃圾回收
// 处理数据的逻辑
}
@前端进阶之旅: 代码已经复制到剪贴板
- 移除存在绑定事件的 DOM 元素(
IE):
var element = document.getElementById('myElement');
element.onclick = function() {
// 处理点击事件
};
// 移除元素时没有显式地解绑事件处理程序,可能导致内存泄漏(在 IE 浏览器中)
element.parentNode.removeChild(element);
@前端进阶之旅: 代码已经复制到剪贴板
- 使用字符串作为
setTimeout的第一个参数:
setTimeout('console.log("timeout");', 1000);
// 使用字符串作为参数,会导致内存泄漏(不推荐)
@前端进阶之旅: 代码已经复制到剪贴板
注意:以上示例只是为了说明可能导致内存泄漏的操作,并非一定会发生内存泄漏。在实际开发中,需要注意避免这些操作或及时进行相应的内存管理和资源释放。
14 XML和JSON的区别?
XML(可扩展标记语言)和JSON(JavaScript对象表示法)是两种常用的数据格式,它们在以下几个方面有一些区别:
- 数据体积方面:
JSON相对于XML来说,数据的体积小,因为JSON使用了较简洁的语法,所以传输的速度更快。
- 数据交互方面:
JSON与JavaScript的交互更加方便,因为JSON数据可以直接被JavaScript解析和处理,无需额外的转换步骤。XML需要使用DOM操作来解析和处理数据,相对而言更复杂一些。
- 数据描述方面:
XML对数据的描述性较强,它使用标签来标识数据的结构和含义,可以自定义标签名,使数据更具有可读性和可扩展性。JSON的描述性较弱,它使用简洁的键值对表示数据,适合于简单的数据结构和传递。
- 传输速度方面:
JSON的解析速度要快于XML,因为JSON的语法更接近JavaScript对象的表示,JavaScript引擎能够更高效地解析JSON数据。
需要根据具体的需求和使用场景选择合适的数据格式,一般来说,如果需要简单、轻量级的数据交互,并且与JavaScript紧密集成,可以选择JSON。而如果需要较强的数据描述性和扩展性,或者需要与其他系统进行数据交互,可以选择XML。
15 谈谈你对webpack的看法
Webpack是一个功能强大的模块打包工具,它在现代Web开发中扮演着重要的角色。以下是对Webpack的看法:
- 模块化开发:Webpack以模块化的方式管理项目中的各种资源,包括JavaScript、CSS、图片、字体等。它能够将这些资源视为模块,并根据模块之间的依赖关系进行打包,使代码结构更清晰、可维护性更高。
- 强大的打包能力:Webpack具有强大的打包能力,能够将项目中的多个模块打包成一个或多个静态资源文件。它支持各种模块加载器和插件,可以处理各种类型的资源文件,并且能够进行代码压缩、文件合并、按需加载等优化操作,以提高应用的性能和加载速度。
- 生态系统丰富:Webpack拥有一个庞大的插件生态系统,可以满足各种项目的需求。通过使用各种插件,我们可以实现代码的优化、资源的压缩、自动化部署等功能,大大提升了开发效率。
- 开发工具支持:Webpack提供了开发工具和开发服务器,支持热模块替换(Hot Module Replacement)等功能,使开发过程更加高效和便捷。它能够实时监听文件的变化并自动重新编译和刷新页面,极大地提升了开发体验。
- 社区活跃:Webpack拥有一个庞大的社区,开发者们积极分享各种有用的插件和工具,提供了大量的学习资源和解决方案。通过与社区的交流和学习,我们可以更好地了解Webpack的使用技巧和最佳实践。
总的来说,Webpack是一个非常强大和灵活的模块打包工具,它在现代Web开发中发挥着重要作用。通过Webpack,我们可以更好地组织和管理项目代码,提高开发效率和代码质量,同时也能够享受到丰富的插件和工具支持。
16 说说你对AMD和Commonjs的理解
对于AMD(Asynchronous Module Definition)和CommonJS的理解如下:
1. AMD(异步模块定义):
- AMD是一种用于浏览器端的模块定义规范。
- 它支持异步加载模块,允许在模块加载完成后执行回调函数。
- AMD推荐的风格是通过
define函数定义模块,并通过返回一个对象来暴露模块的接口。 - 典型的AMD实现是RequireJS。
2. CommonJS:
- CommonJS是一种用于服务器端的模块定义规范,Node.js采用了这个规范。
- 它使用同步加载模块的方式,即只有模块加载完成后才能执行后续操作。
- CommonJS的风格是通过对
module.exports或exports的属性赋值来暴露模块的接口。 - CommonJS适用于服务器端的模块加载,因为在服务器端文件的读取是同步的,不会影响性能。
总结:
- AMD和CommonJS是两种不同的模块定义规范,分别适用于浏览器端和服务器端的模块加载。
- AMD采用异步加载模块的方式,适用于浏览器环境,允许并行加载多个模块,适用于复杂的模块依赖关系。
- CommonJS采用同步加载模块的方式,适用于服务器环境,因为在服务器端文件的读取是同步的。
- 在实际开发中,可以根据项目的需求和运行环境选择使用AMD或CommonJS规范来组织和加载模块。
AMD 示例代码:
// 模块定义
define(['moduleA', 'moduleB'], function(moduleA, moduleB) {
// 模块代码
var foo = moduleA.foo();
var bar = moduleB.bar();
return {
baz: function() {
console.log(foo + bar);
}
};
});
// 模块加载
require(['myModule'], function(myModule) {
myModule.baz(); // 调用模块方法
});
@前端进阶之旅: 代码已经复制到剪贴板
CommonJS 示例代码:
// 模块定义
// moduleA.js
exports.foo = function() {
return 'Hello';
};
// moduleB.js
exports.bar = function() {
return 'World';
};
// 主程序
// main.js
var moduleA = require('./moduleA');
var moduleB = require('./moduleB');
var foo = moduleA.foo();
var bar = moduleB.bar();
console.log(foo + ' ' + bar);
@前端进阶之旅: 代码已经复制到剪贴板
在浏览器环境下,可以使用RequireJS作为AMD规范的实现库。在Node.js环境下,CommonJS模块加载是内置的,无需使用额外的库。以上示例代码是在浏览器端和Node.js环境中分别使用AMD和CommonJS规范加载模块的简单示例。
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
26 Node的应用场景
特点:
- 基于事件驱动和非阻塞I/O: Node.js采用事件驱动的编程范式,通过异步非阻塞的I/O模型实现高效的并发处理,能够处理大量的并发连接。
- 单线程: Node.js使用单线程处理请求,避免了传统多线程模型中线程切换的开销,提高了处理请求的效率。
- 基于V8引擎: Node.js使用Google Chrome浏览器中的V8引擎解释执行JavaScript代码,具有高性能和高效的特点。
- 跨平台: Node.js可以在多个操作系统上运行,如Windows、Linux、Mac等。
优点:
- 高并发性能: Node.js的事件驱动和非阻塞I/O模型使其能够处理大量并发请求,适用于构建高性能的网络应用。
- 快速开发: Node.js使用JavaScript语言,具有统一的开发语言,使得前端开发人员可以轻松上手进行服务器端开发。
- 丰富的模块生态系统: Node.js拥有庞大的模块生态系统,提供了丰富的第三方模块和工具,可以快速构建复杂的应用程序。
- 轻量和高效: Node.js具有较小的内存占用和快速的启动时间,适合部署在云环境或资源有限的设备上。
缺点:
- 单线程限制: Node.js使用单线程处理请求,如果有长时间运行的计算密集型任务或阻塞操作,会导致整个应用程序的性能下降。
- 可靠性低: Node.js在处理错误和异常方面相对较弱,一旦代码某个环节崩溃,整个应用程序都可能崩溃,需要仔细处理错误和异常情况。
- 不适合CPU密集型任务: 由于Node.js的单线程特性,不适合处理需要大量计算的CPU密集型任务,这类任务可能会阻塞事件循环,影响整个应用程序的性能。
Node.js的应用场景主要包括以下几个方面:
- 服务器端开发: Node.js在服务器端开发中表现出色。由于其事件驱动、非阻塞的特性,适合处理高并发的网络请求,可以快速构建高性能的网络应用程序,如Web服务器、API服务器、实时聊天应用等。
- 实时应用程序: 基于Node.js的实时应用程序能够实现双向通信,例如实时聊天应用、协作工具、多人游戏等。Node.js的事件驱动模型和非阻塞I/O使得处理大量并发连接变得更加高效。
- 命令行工具: Node.js提供了丰富的API和模块,使得开发命令行工具变得简单和高效。通过Node.js可以编写自定义的命令行工具,用于执行各种任务、自动化流程和脚本处理等。
- 构建工具: Node.js可以用于构建前端的构建工具和任务执行器,如Grunt和Gulp。这些工具利用Node.js的模块化和文件操作能力,帮助开发者自动化地处理代码的编译、压缩、打包等任务。
- 代理服务器: 基于Node.js可以构建高性能的代理服务器,用于代理请求、路由转发、负载均衡等。Node.js的非阻塞I/O使得代理服务器能够同时处理大量的并发请求。
总的来说,Node.js适用于需要处理高并发、实时性要求高、需要构建高性能网络应用的场景。它在Web开发、实时应用、命令行工具等领域都有广泛的应用。
27 谈谈你对AMD、CMD的理解
AMD(Asynchronous Module Definition)和CMD(Common Module Definition)是用于浏览器端的模块加载规范。它们的目标都是解决模块化开发的问题,提供了异步加载模块的机制,以提高网页的性能和加载速度。
AMD(Asynchronous Module Definition)
AMD是由RequireJS提出的一种模块加载规范。AMD规范采用异步加载模块的方式,在使用模块之前,需要先定义模块的依赖关系,然后通过回调函数来使用模块。这种方式适用于浏览器环境,可以避免阻塞页面的加载。AMD规范使用define函数来定义模块,可以指定模块的依赖关系和回调函数。在回调函数中可以获取依赖模块,并进行相应的操作。- 示例代码:
define(['module1', 'module2'], function(module1, module2) {
// 使用module1和module2进行操作
});
@前端进阶之旅: 代码已经复制到剪贴板
CMD(Common Module Definition)
CMD是由SeaJS提出的一种模块加载规范。CMD规范与AMD规范类似,也采用异步加载模块的方式。但与AMD不同的是,CMD规范在使用模块之前不需要先定义依赖关系,而是在使用时才进行模块的加载。CMD规范使用define函数来定义模块,可以在回调函数中使用require函数来加载依赖模块。- 示例代码:
define(function(require) {
var module1 = require('module1');
var module2 = require('module2');
// 使用module1和module2进行操作
});
@前端进阶之旅: 代码已经复制到剪贴板
总体来说,AMD和CMD都是用于浏览器端的模块加载规范,目的是解决模块化开发的问题。它们的区别在于模块定义和加载的时机不同,AMD在定义时就指定依赖关系并加载模块,而CMD在使用时才加载模块。根据具体的项目需求和团队的开发习惯,可以选择适合的规范进行模块化开发。
28 那些操作会造成内存泄漏
除了之前提到的操作,以下是更多可能导致内存泄漏的操作,并附带示例代码:
1. 定时器未清理:
function startTimer() {
setInterval(() => {
// 定时操作
}, 1000);
}
// 没有清理定时器,导致内存泄漏
@前端进阶之旅: 代码已经复制到剪贴板
解决方法:在不需要定时器时,使用 clearInterval 或 clearTimeout 清理定时器。
2. 异步操作未完成导致回调函数未执行:
function fetchData(callback) {
// 异步操作,例如 AJAX 请求或数据库查询
// 忘记调用回调函数,导致内存泄漏
}
// 示例中没有调用 fetchData 的回调函数
@前端进阶之旅: 代码已经复制到剪贴板
解决方法:确保异步操作完成后,调用相应的回调函数,或使用 Promise 或 async/await 等方式管理异步操作的状态。
3. DOM 元素未正确移除:
function createDOMElement() {
const element = document.createElement('div');
// 在页面中插入 element,但没有移除
// 该函数可能被多次调用,导致大量无用的 DOM 元素存在于内存中
}
@前端进阶之旅: 代码已经复制到剪贴板
解决方法:在不需要的时候,使用 removeChild 或其他方法将 DOM 元素从页面中移除。
4. 未释放闭包中的引用:
function createClosure() {
const data = 'sensitive data';
setTimeout(() => {
console.log(data);
}, 1000);
// 闭包中引用了外部的 data 变量,导致 data 无法被垃圾回收
}
@前端进阶之旅: 代码已经复制到剪贴板
解决方法:在不需要使用闭包中的外部变量时,确保取消引用,例如将闭包中的引用设置为 null。
除了之前提到的操作,以下是更多可能导致内存泄漏的操作,并附带示例代码:
5. 未正确释放事件监听器:
function addEventListener() {
const element = document.getElementById('myElement');
element.addEventListener('click', () => {
// 事件处理程序
});
// 没有移除事件监听器,导致内存泄漏
}
@前端进阶之旅: 代码已经复制到剪贴板
解决方法:在不需要监听事件时,使用 removeEventListener 方法将事件监听器移除。
6. 大量数据缓存导致内存占用过高:
function cacheData() {
const data = fetchData(); // 获取大量数据
// 将数据存储在全局变量或其他长久存在的对象中
// 数据缓存过多,占用大量内存资源
}
@前端进阶之旅: 代码已经复制到剪贴板
解决方法:及时清理不再需要的数据缓存,或使用适当的数据存储方案,例如使用数据库等。
7. 循环引用:
function createCircularReference() {
const obj1 = {};
const obj2 = {};
obj1.ref = obj2;
obj2.ref = obj1;
// obj1 和 obj2 彼此引用,导致无法被垃圾回收
}
@前端进阶之旅: 代码已经复制到剪贴板
解决方法:确保循环引用的对象在不再需要时被解除引用,例如将相应的属性设置为 null。
8. 未正确释放资源:
function openResource() {
const resource = openSomeResource();
// 忘记关闭或释放 resource,导致资源泄漏
}
@前端进阶之旅: 代码已经复制到剪贴板
解决方法:在不再需要使用资源时,确保关闭、释放或销毁相应的资源,例如关闭数据库连接、释放文件句柄等。
29 web开发中会话跟踪的方法有哪些
在Web开发中,常见的会话跟踪方法包括:
1. Cookie:
- 使用HTTP Cookie来跟踪会话状态,将会话信息存储在客户端。
示例代码:
// 设置Cookie
document.cookie = "sessionID=abc123; expires=Sat, 31 Dec 2023 23:59:59 GMT; path=/";
// 读取Cookie
var sessionID = document.cookie;
@前端进阶之旅: 代码已经复制到剪贴板
2. Session:
- 使用服务器端的会话管理机制,在服务器端存储会话数据,客户端通过会话ID来进行访问。
示例代码(使用Express.js框架):
// 在服务器端设置Session
app.use(session({ secret: 'secretKey', resave: false, saveUninitialized: true }));
// 在路由处理程序中存储和访问Session数据
req.session.username = 'poetry';
var username = req.session.username;
@前端进阶之旅: 代码已经复制到剪贴板
3. URL重写:
- 在URL中附加会话标识符来进行会话跟踪。
示例代码:
https://example.com/page?sessionID=abc123
@前端进阶之旅: 代码已经复制到剪贴板
4. 隐藏Input:
- 在HTML表单中使用隐藏的输入字段来存储会话信息。
示例代码:
<input type="hidden" name="sessionID" value="abc123">
@前端进阶之旅: 代码已经复制到剪贴板
5. IP地址:
- 根据客户端的IP地址进行会话跟踪,但这种方法可能受到共享IP、代理服务器等因素的影响。
示例代码(使用Node.js):
var clientIP = req.headers['x-forwarded-for'] || req.connection.remoteAddress;
@前端进阶之旅: 代码已经复制到剪贴板
30 JS的基本数据类型和引用数据类型
- 基本数据类型:
undefined: 表示未定义或未初始化的值。null: 表示空值或不存在的对象。boolean: 表示逻辑上的true或false。number: 表示数值,包括整数和浮点数。string: 表示字符串。symbol: 表示唯一的、不可变的值,通常用作对象的属性键。
- 引用数据类型:
object: 表示一个复杂的数据结构,可以包含多个键值对。array: 表示一个有序的、可变长度的集合。function: 表示可执行的代码块,可以被调用执行。
基本数据类型在赋值时是按值传递的,每个变量都有自己的存储空间,修改一个变量不会影响其他变量。而引用数据类型在赋值时是按引用传递的,多个变量引用同一个对象,修改一个变量会影响其他变量。需要注意的是,null和undefined既是基本数据类型,也是特殊的值,表示不同的含义。
31 介绍js有哪些内置对象
JavaScript中有许多内置对象,用于提供各种功能和方法,常见的内置对象包括:
Object: 所有对象的基类。Array: 用于表示和操作数组的对象。Boolean: 代表布尔值true或false。Number: 代表数字,用于执行数值操作和计算。String: 代表字符串,用于处理和操作文本数据。Date: 用于处理日期和时间。RegExp: 用于进行正则表达式匹配。Function: 用于定义和调用函数。Math: 提供数学计算相关的方法和常量。JSON: 用于解析和序列化 JSON 数据。Error: 用于表示和处理错误。Map: 一种键值对的集合,其中键可以是任意类型。Set: 一种集合数据结构,存储唯一的值。Promise: 用于处理异步操作和编写更优雅的异步代码。Symbol: 代表唯一的标识符。
这些内置对象提供了丰富的功能和方法,可以满足不同的编程需求。开发人员可以利用这些对象来处理数据、执行操作、处理错误等。
32 说几条写JavaScript的基本规范
下面是几条常见的写JavaScript的基本规范:
- 使用驼峰命名法(camel case)命名变量、函数和对象属性,例如:
firstName,getUserData(),myObject.property - 使用大写字母开头的驼峰命名法(Pascal case)命名构造函数或类,例如:
Person,UserModel - 使用全大写字母和下划线命名常量,例如:
MAX_VALUE,API_KEY - 使用单行注释(
//)或块注释(/* */)对代码进行注释,解释代码的用途和实现思路 - 使用缩进(通常是四个空格或一个制表符)来表示代码块的层次结构,增加代码的可读性
- 使用严格模式(
"use strict";)来提高代码的安全性和效率,避免使用隐式全局变量 - 尽量避免使用全局变量,封装代码到函数或模块中,使用局部变量来限制作用域,减少命名冲突
- 在声明变量时,使用
let或const来代替var,避免变量提升和作用域问题 - 尽量避免使用隐式类型转换,使用严格相等运算符(
===和!==)进行比较,避免类型不匹配的问题 - 在使用条件语句(
if、else)和循环语句(for、while)时,始终使用花括号来明确代码块的范围,避免歧义和错误 - 使用单引号或双引号来表示字符串,保持一致性,推荐使用单引号
- 尽量使用模板字符串来拼接字符串,避免使用字符串连接符(
+)或复杂的字符串拼接操作 - 使用数组和对象的字面量语法(
[]和{})来创建数组和对象,而不是使用构造函数,例如:let arr = [1, 2, 3],let obj = {name: 'poetry', age: 25} - 对于长的逻辑语句或表达式,可以使用合适的换行和缩进来增加可读性,或者使用括号将其分成多行
- 避免使用
eval()函数和with语句,它们可能引起安全问题和性能问题
这些规范旨在提高代码的可读性、可维护性和一致性,促进团队协作和代码质量的提升。在编写JavaScript代码时,遵循这些规范可以帮助开发人员写出更优雅、健壮和易于
33 JavaScript有几种类型的值
JavaScript有以下几种类型的值:
- 原始数据类型:
Undefined:表示未定义的值。Null:表示空值。Boolean:表示布尔值,只有两个取值:true和false。Number:表示数字,包括整数和浮点数。String:表示字符串,用于表示文本数据。Symbol(ES6新增):表示唯一的、不可变的值。
- 引用数据类型:
Object:表示对象,是一种复合值,可以包含多个键值对。Array:表示数组,是一种有序的、可变的集合。Function:表示函数,可以执行特定的任务。Date:表示日期和时间。RegExp:表示正则表达式,用于匹配和处理字符串。Error:表示错误对象,用于捕获和处理异常情况。
原始数据类型存储在栈中,通过值的复制来进行赋值和传递。而引用数据类型存储在堆中,通过引用的方式进行赋值和传递,实际上传递的是指向堆中对象的引用地址。
注意:ES6新增的Symbol类型是一种唯一的、不可变的数据类型,用于创建唯一的标识符,主要用于对象属性的键值。
34 eval是做什么的
eval() 是 JavaScript 的一个全局函数,用于将传入的字符串作为 JavaScript 代码进行解析和执行。
其主要功能有以下几个方面:
- 动态执行代码:
eval()可以将字符串作为 JavaScript 代码进行执行,将字符串解析为可执行的 JavaScript 代码。这样可以动态生成和执行代码,灵活性较高。 - 计算字符串表达式:
eval()可以计算传入的字符串表达式并返回结果。 - 解析 JSON:在某些情况下,可以使用
eval()将 JSON 字符串解析为 JavaScript 对象。但是需要注意,使用eval()解析 JSON 字符串存在安全风险,因为它会执行传入的任意代码,可能导致恶意代码的注入。
需要注意的是,由于 eval() 执行的字符串会被解析和执行,因此在使用 eval() 时要格外小心,避免执行不可信的代码,以防止安全漏洞和性能问题。在大多数情况下,可以通过其他方式实现相同的功能,而不必使用 eval()。
35 null,undefined 的区别
null 和 undefined 是 JavaScript 中表示空值或缺失值的两个特殊值。
区别如下:
undefined表示变量声明了但没有被赋值,或者访问对象属性不存在时的默认返回值。
- 当变量被声明但未被赋值时,默认值为
undefined。 - 当访问对象的不存在属性时,返回值为
undefined。
null表示变量被赋予了一个空值,表示有一个对象,但该对象为空。
- 当想要明确表示一个变量为空对象时,可以将其赋值为
null。 null是一个特殊的对象值,表示对象为空,即不指向任何内存地址。
总结:
undefined表示缺少值或未定义的值,常见于变量声明但未赋值的情况。null表示空对象,常见于显式地将对象赋值为空。
在使用条件判断时,要注意区分它们的差异。对于严格相等比较,推荐使用 === 来避免类型转换,以准确判断两者是否相等。
36 [“1”, “2”, “3”].map(parseInt) 答案是多少
parseInt(str, radix)
- 解析一个字符串,并返回
10进制整数 - 第一个参数
str,即要解析的字符串 - 第二个参数
radix,基数(进制),范围2-36,以radix进制的规则去解析str字符串。不合法导致解析失败 - 如果没有传
radix- 当
str以0开头,则按照16进制处理 - 当
str以0开头,则按照8进制处理(但是ES5取消了,可能还有一些老的浏览器使用)会按照10进制处理 - 其他情况按照
10进制处理
- 当
eslint会建议parseInt写第二个参数(是因为0开始的那个8进制写法不确定(如078),会按照10进制处理)
// 拆解
const arr = ["1", "2", "3"]
const res = arr.map((item,index,array)=>{
// item: '1', index: 0
// item: '2', index: 1
// item: '3', index: 2
return parseInt(item, index)
// parseInt('1', 0) // 0相当没有传,按照10进制处理返回1 等价于parseInt('1')
// parseInt('2', 1) // NaN 1不符合redix 2-36 的一个范围
// parseInt('3', 2) // 2进制没有3 返回NaN
})
// 答案 [1, NaN, NaN]
@前端进阶之旅: 代码已经复制到剪贴板
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
47 对web标准、可用性、可访问性的理解
Web标准(Web Standards)是指由W3C(World Wide Web Consortium)等组织制定的用于开发和实现Web内容的一系列规范和标准。它包括HTML、CSS、JavaScript等技术规范,旨在确保不同浏览器和设备在呈现网页时的一致性和互操作性。遵循Web标准可以提高网站的可维护性、可访问性和可扩展性,同时提升用户体验。
- 可用性(Usability)是指一个产品或系统在用户使用过程中的易用性和用户满意度。一个具有良好可用性的产品能够满足用户的需求,提供直观、简洁、一致的用户界面,减少用户的学习成本和操作复杂度,提供明确的反馈和帮助信息,从而提升用户的效率和满意度。
- 可访问性(Accessibility)是指Web内容对于所有用户,包括残障用户,的可阅读和可理解性。它涉及到使用无障碍技术和遵循无障碍设计原则,以确保残障用户能够平等地获取和使用Web内容。这包括为视觉、听觉、运动和认知等方面的残障用户提供适当的辅助功能和支持,如屏幕阅读器、放大器、辅助键盘等。
- 可维护性(Maintainability)是指一个系统或代码的易维护性和可理解性。一个具有良好可维护性的系统能够快速定位和修复问题,容易进行功能扩展和修改。为了提高可维护性,代码应具有良好的结构和组织,遵循设计模式和编程规范,提供清晰的注释和文档,同时采用合适的工具和方法进行版本控制和测试。
这三个概念在Web开发中都非常重要。遵循Web标准可以提高网站的可访问性和可用性,从而更好地服务于用户的需求。同时,考虑可维护性可以降低代码的维护成本和风险,使开发团队能够更加高效地进行开发和迭代。
48 如何通过JS判断一个数组
instanceof方法:使用instanceof运算符判断对象是否为数组,返回布尔值。例如:arr instanceof Array。constructor方法:使用constructor属性返回对象的构造函数,并判断该构造函数是否为数组构造函数。例如:arr.constructor == Array。- 使用
Object.prototype.toString.call()方法:利用Object.prototype.toString.call(value)方法,将要判断的变量作为参数传入,并判断返回的字符串是否为"[object Array]"。例如:Object.prototype.toString.call(arr) == '[object Array]'。 ES5新增的isArray()方法:使用Array.isArray()方法判断一个值是否为数组,返回布尔值。例如:Array.isArray(arr)。
49 谈一谈let与var的区别
1. 块级作用域:
let声明的变量具有块级作用域,在块级作用域内定义的变量只在该块内有效。var声明的变量没有块级作用域,它的作用域是函数级的或全局的。
示例代码:
// 使用 let 声明变量
function example1() {
let x = 10;
if (true) {
let x = 20;
console.log(x); // 输出 20
}
console.log(x); // 输出 10
}
example1();
// 使用 var 声明变量
function example2() {
var y = 30;
if (true) {
var y = 40;
console.log(y); // 输出 40
}
console.log(y); // 输出 40
}
example2();
@前端进阶之旅: 代码已经复制到剪贴板
2. 变量提升:
- 使用
let声明的变量不存在变量提升,必须在声明后使用。 - 使用
var声明的变量会存在变量提升,可以在声明之前使用。
示例代码:
// 使用 let 声明变量
function example3() {
console.log(x); // 报错:ReferenceError: x is not defined
let x = 10;
}
example3();
// 使用 var 声明变量
function example4() {
console.log(y); // 输出 undefined
var y = 20;
}
example4();
@前端进阶之旅: 代码已经复制到剪贴板
3. 重复声明:
- 使用
let声明的变量不允许重复声明,重复声明会导致报错。 - 使用
var声明的变量允许重复声明,不会报错,后面的声明会覆盖前面的声明。
示例代码:
// 使用 let 声明变量
let z = 30;
let z = 40; // 报错:SyntaxError: Identifier 'z' has already been declared
// 使用 var 声明变量
var w = 50;
var w = 60; // 不会报错,后面的声明覆盖前面的声明
console.log(w); // 输出 60
@前端进阶之旅: 代码已经复制到剪贴板
4. 循环中的区别
在for循环中,使用var声明的变量具有函数作用域,因此在循环结束后仍然可以访问到循环变量;而使用let声明的变量具有块级作用域,因此在每次循环迭代时会创建一个新的变量实例,避免了常见的循环中的问题。
- 使用
let声明的变量在循环体内部具有块级作用域,每次迭代都会创建一个新的变量。 - 使用
var声明的变量在循环体内部没有块级作用域,变量是函数级的或全局的。
// 使用 let 声明变量的循环
for (let i = 0; i < 3; i++) {
setTimeout(function() {
console.log(i); // 输出 0, 1, 2
}, 1000);
}
// 使用 var 声明变量的循环
for (var j = 0; j < 3; j++) {
setTimeout(function() {
console.log(j); // 输出 3, 3, 3
}, 1000);
}
@前端进阶之旅: 代码已经复制到剪贴板
50 map与forEach的区别
forEach方法是无法中断的,即使在遍历过程中使用return语句也无法停止遍历。而map方法可以使用return语句中断遍历。map方法会生成一个新的数组,并将每次遍历的返回值按顺序放入新数组中。而forEach方法没有返回值,仅用于遍历数组。map方法可以链式调用其他数组方法,比如filter、reduce等。而forEach方法不能链式调用其他数组方法。
示例代码:
const numbers = [1, 2, 3, 4, 5];
// 使用 forEach 方法遍历数组
numbers.forEach(function(item, index, array) {
console.log(item); // 输出数组元素
console.log(index); // 输出索引值
console.log(array); // 输出原数组
});
// 使用 map 方法遍历数组并生成新数组
const doubledNumbers = numbers.map(function(item, index, array) {
return item * 2;
});
console.log(doubledNumbers); // 输出 [2, 4, 6, 8, 10]
@前端进阶之旅: 代码已经复制到剪贴板
在上面的示例中,使用forEach方法遍历数组并输出元素、索引和原数组。而使用map方法遍历数组并返回每个元素的两倍值,生成一个新的数组doubledNumbers。注意,在map的回调函数中使用了return语句来指定返回值。
总结:
forEach方法用于遍历数组,没有返回值;map方法也用于遍历数组,返回一个新的数组,并且可以通过在回调函数中使用return语句来指定每次遍历的返回值。
51 谈一谈你理解的函数式编程
- 简单说,“函数式编程"是一种"编程范式”(programming paradigm),也就是如何编写程序的方法论
- 它具有以下特性:闭包和高阶函数、惰性计算、递归、函数是"第一等公民"、只用"表达式"
函数式编程(Functional Programming)是一种编程范式,它强调将计算过程视为函数求值的数学模型,通过组合和应用函数来进行程序开发。函数式编程具有以下特点:
- 纯函数(Pure Functions):函数的输出只由输入决定,不会产生副作用,即对同样的输入始终返回相同的输出。纯函数不会修改传入的参数,也不会改变外部状态,使得代码更加可预测和易于测试。
- 不可变性(Immutability):数据一旦创建就不能被修改,任何对数据的改变都会创建一个新的数据副本。这种不可变性使得代码更加安全,避免了一些潜在的错误。
- 高阶函数(Higher-Order Functions):函数可以作为参数传递给其他函数,也可以作为返回值返回。这种高阶函数的能力可以用来进行函数的组合、封装和抽象,提高代码的复用性和可读性。
- 函数组合(Function Composition):通过将多个函数组合成一个新的函数,可以实现更复杂的逻辑。函数组合可以通过函数的返回值作为参数传递给另一个函数,将多个函数连接起来形成一个函数链。
- 惰性计算(Lazy Evaluation):只在需要的时候才进行计算,避免不必要的计算。这种惰性计算可以提高程序的性能和效率。
下面是一个简单的函数式编程的示例代码:
// 纯函数示例:计算一个数组中所有偶数的平均值
function calculateAverage(numbers) {
const evenNumbers = numbers.filter((num) => num % 2 === 0);
const sum = evenNumbers.reduce((acc, curr) => acc + curr, 0);
return sum / evenNumbers.length;
}
const numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
const average = calculateAverage(numbers);
console.log(average); // 输出 6
// 高阶函数示例:使用 map 和 reduce 计算数组中每个元素的平方和
function calculateSquareSum(numbers) {
return numbers.map((num) => num * num).reduce((acc, curr) => acc + curr, 0);
}
const numbers = [1, 2, 3, 4, 5];
const squareSum = calculateSquareSum(numbers);
console.log(squareSum); // 输出 55
// 函数组合示例:组合两个函数计算数组中偶数的平方和
const evenNumbersSquareSum = calculateSquareSum(numbers.filter((num) => num % 2 === 0));
console.log(evenNumbersSquareSum); // 输出 20
@前端进阶之旅: 代码已经复制到剪贴板
在上面的示例代码中,我们使用纯函数的方式编写了两个函数calculateAverage和calculateSquareSum,它们接收一个数组作为参数,并根据函数式编程的原则
52 谈一谈箭头函数与普通函数的区别?
this指向: 箭头函数没有自己的this,它会捕获所在上下文的this值。而普通函数的this是在运行时确定的,根据调用方式决定。
// 普通函数中的this指向调用者
function greet() {
console.log(`Hello, ${this.name}!`);
}
const person = { name: 'Alice' };
greet.call(person); // 输出:Hello, Alice!
// 箭头函数中的this指向定义时的上下文
const greetArrow = () => {
console.log(`Hello, ${this.name}!`);
};
greetArrow.call(person); // 输出:Hello, undefined!
@前端进阶之旅: 代码已经复制到剪贴板
- 不可作为构造函数: 箭头函数不能使用
new关键字来创建实例,它没有自己的prototype属性,无法进行实例化。
const Person = (name) => {
this.name = name; // 错误,箭头函数不能作为构造函数
};
const person = new Person('Alice'); // 错误,无法实例化箭头函数
@前端进阶之旅: 代码已经复制到剪贴板
- 无
arguments对象: 箭头函数没有自己的arguments对象,可以使用Rest参数来代替。
function sum() {
console.log(arguments); // 输出函数的参数列表
}
sum(1, 2, 3); // 输出:Arguments(3) [1, 2, 3]
const sumArrow = (...args) => {
console.log(args); // 输出函数的参数列表
};
sumArrow(1, 2, 3); // 输出:[1, 2, 3]
@前端进阶之旅: 代码已经复制到剪贴板
- 无
yield命令: 箭头函数不能用作Generator函数,无法使用yield命令进行函数的暂停和恢复。
function* generatorFunc() {
yield 1;
yield 2;
}
const gen = generatorFunc();
console.log(gen.next().value); // 输出:1
const arrowGen = () => {
yield 1; // 错误,箭头函数不能使用yield命令
};
@前端进阶之旅: 代码已经复制到剪贴板
综上所述,箭头函数与普通函数在
this指向、构造函数能力、arguments对象和yield命令等方面有明显的区别。根据具体的使用场景和需求,选择适合的函数类型进行编程。
总结
- 函数体内的
this对象,就是定义时所在的对象,而不是使用时所在的对象 - 不可以当作构造函数,也就是说,不可以使用
new命令,否则会抛出一个错误 - 不可以使用
arguments对象,该对象在函数体内不存在。如果要用,可以用Rest参数代替 - 不可以使用
yield命令,因此箭头函数不能用作Generator函数
53 谈一谈函数中this的指向
函数中的this指向是根据函数的调用方式而确定的,有以下几种常见的情况:
- 方法调用模式: 当函数作为对象的方法被调用时,
this指向调用该方法的对象。
const person = {
name: 'Alice',
greet: function() {
console.log(`Hello, ${this.name}!`);
}
};
person.greet(); // 输出:Hello, Alice!
@前端进阶之旅: 代码已经复制到剪贴板
- 函数调用模式: 当函数独立调用时,
this指向全局对象(在浏览器环境中通常指向window对象)或undefined(在严格模式下)。
function greet() {
console.log(`Hello, ${this.name}!`);
}
const name = 'Alice';
greet(); // 输出:Hello, undefined!
// 在严格模式下
'use strict';
greet(); // 输出:Hello, undefined!
@前端进阶之旅: 代码已经复制到剪贴板
- 构造器调用模式: 当函数用作构造器(使用
new关键字)创建对象时,this指向新创建的对象。
function Person(name) {
this.name = name;
this.greet = function() {
console.log(`Hello, ${this.name}!`);
};
}
const person = new Person('Alice');
person.greet(); // 输出:Hello, Alice!
@前端进阶之旅: 代码已经复制到剪贴板
apply/call调用模式: 使用apply或call方法来调用函数时,可以手动指定this的值。
function greet() {
console.log(`Hello, ${this.name}!`);
}
const person = {
name: 'Alice'
};
greet.call(person); // 输出:Hello, Alice!
greet.apply(person); // 输出:Hello, Alice!
@前端进阶之旅: 代码已经复制到剪贴板
总结来说,函数中的
this指向是根据函数的调用方式来确定的,可以是调用函数的对象、全局对象、新创建的对象,或者通过apply/call方法手动指定。了解函数的调用方式可以帮助理解和正确使用this关键字。
总结
1. this 指向有哪几种
- 默认绑定:全局环境中,
this默认绑定到window - 隐式绑定:一般地,被直接对象所包含的函数调用时,也称为方法调用,
this隐式绑定到该直接对象 - 隐式丢失:隐式丢失是指被隐式绑定的函数丢失绑定对象,从而默认绑定到
window。显式绑定:通过call()、apply()、bind()方法把对象绑定到this上,叫做显式绑定 new绑定:如果函数或者方法调用之前带有关键字new,它就构成构造函数调用。对于this绑定来说,称为new绑定- 构造函数通常不使用
return关键字,它们通常初始化新对象,当构造函数的函数体执行完毕时,它会显式返回。在这种情况下,构造函数调用表达式的计算结果就是这个新对象的值 - 如果构造函数使用
return语句但没有指定返回值,或者返回一个原始值,那么这时将忽略返回值,同时使用这个新对象作为调用结果 - 如果构造函数显式地使用
return语句返回一个对象,那么调用表达式的值就是这个对象
- 构造函数通常不使用
2. 改变函数内部 this 指针的指向函数(bind,apply,call的区别)
apply:调用一个对象的一个方法,用另一个对象替换当前对象。例如:B.apply(A, arguments);即A对象应用B对象的方法call:调用一个对象的一个方法,用另一个对象替换当前对象。例如:B.call(A, args1,args2);即A对象调用B对象的方法bind除了返回是函数以外,它的参数和call一样
3. 箭头函数
- 箭头函数没有
this,所以需要通过查找作用域链来确定this的值,这就意味着如果箭头函数被非箭头函数包含,this绑定的就是最近一层非箭头函数的this, - 箭头函数没有自己的
arguments对象,但是可以访问外围函数的arguments对象 - 不能通过
new关键字调用,同样也没有new.target值和原型
54 异步编程的实现方式
- 回调函数:在异步操作完成后,通过回调函数来处理结果
- 优点:简单、容易理解
- 缺点:不利于维护,代码耦合高
function fetchData(callback) {
setTimeout(() => {
const data = 'Hello, world!';
callback(data);
}, 1000);
}
fetchData((data) => {
console.log(data); // 输出:Hello, world!
});
@前端进阶之旅: 代码已经复制到剪贴板
- 事件监听:通过事件的发布和订阅来实现异步操作
- 优点:容易理解,可以绑定多个事件,每个事件可以指定多个回调函数
- 缺点:事件驱动型,流程不够清晰
function fetchData() {
setTimeout(() => {
const data = 'Hello, world!';
eventEmitter.emit('dataReceived', data);
}, 1000);
}
eventEmitter.on('dataReceived', (data) => {
console.log(data); // 输出:Hello, world!
});
fetchData();
@前端进阶之旅: 代码已经复制到剪贴板
- 发布/订阅(观察者模式):类似于事件监听,但是可以通过消息中心来管理发布者和订阅者
- 类似于事件监听,但是可以通过‘消息中心’,了解现在有多少发布者,多少订阅者
function fetchData() {
setTimeout(() => {
const data = 'Hello, world!';
messageCenter.publish('dataReceived', data);
}, 1000);
}
messageCenter.subscribe('dataReceived', (data) => {
console.log(data); // 输出:Hello, world!
});
fetchData();
@前端进阶之旅: 代码已经复制到剪贴板
- Promise对象:使用Promise对象可以更方便地处理异步操作的结果和错误
- 优点:可以利用then方法,进行链式写法;可以书写错误时的回调函数;
- 缺点:编写和理解,相对比较难
function fetchData() {
return new Promise((resolve, reject) => {
setTimeout(() => {
const data = 'Hello, world!';
resolve(data);
}, 1000);
});
}
fetchData()
.then((data) => {
console.log(data); // 输出:Hello, world!
})
.catch((error) => {
console.error(error);
});
@前端进阶之旅: 代码已经复制到剪贴板
- Generator函数:使用Generator函数可以实现函数体内外的数据交换和错误处理
- 优点:函数体内外的数据交换、错误处理机制
- 缺点:流程管理不方便
function* fetchData() {
try {
const data = yield new Promise((resolve, reject) => {
setTimeout(() => {
resolve('Hello, world!');
}, 1000);
});
console.log(data); // 输出:Hello, world!
} catch (error) {
console.error(error);
}
}
const generator = fetchData();
const promise = generator.next().value;
promise
.then((data) => {
generator.next(data);
})
.catch((error) => {
generator.throw(error);
});
@前端进阶之旅: 代码已经复制到剪贴板
- async函数:async函数是Generator函数的语法糖,可以更方便地编写和理解异步代码
- 优点:内置执行器、更好的语义、更广的适用性、返回的是Promise、结构清晰。
- 缺点:错误处理机制
async function fetchData() {
try {
const data = await new Promise((resolve, reject) => {
setTimeout(() => {
resolve('Hello, world!');
}, 1000);
});
console.log(data); // 输出:Hello, world!
} catch (error) {
console.error(error);
}
}
fetchData();
@前端进阶之旅: 代码已经复制到剪贴板
56 谈谈你对原生Javascript了解程度
数据类型、运算、对象、Function、继承、闭包、作用域、原型链、事件、
RegExp、JSON、Ajax、DOM、BOM、内存泄漏、跨域、异步装载、模板引擎、前端MVC、路由、模块化、Canvas、ECMAScript
1. 数据类型:JavaScript具有多种数据类型,包括字符串、数字、布尔值、对象、数组、函数等 2. 运算:JavaScript支持常见的算术运算、逻辑运算和比较运算,也支持位运算和三元运算符
let sum = 5 + 3;
let isTrue = true && false;
let isEqual = 10 === 5;
let bitwiseOr = 3 | 5;
let result = (num > 0) ? "Positive" : "Negative";
@前端进阶之旅: 代码已经复制到剪贴板
3. 对象:JavaScript中的对象是键值对的集合,可以通过字面量形式或构造函数创建对象
let person = { name: "poetry", age: 25 };
let car = new Object();
car.brand = "Toyota";
car.color = "Blue";
@前端进阶之旅: 代码已经复制到剪贴板
4. Function:JavaScript中的函数是一等公民,可以作为变量、参数或返回值进行操作
function add(a, b) {
return a + b;
}
let multiply = function(a, b) {
return a * b;
};
let result = multiply(2, 3);
@前端进阶之旅: 代码已经复制到剪贴板
5. 继承: JavaScript使用原型链实现对象之间的继承关系
function Animal(name) {
this.name = name;
}
Animal.prototype.sayHello = function() {
console.log("Hello, I'm " + this.name);
};
function Dog(name, breed) {
Animal.call(this, name);
this.breed = breed;
}
Dog.prototype = Object.create(Animal.prototype);
Dog.prototype.constructor = Dog;
let dog = new Dog("Max", "Labrador");
dog.sayHello();
@前端进阶之旅: 代码已经复制到剪贴板
6. 闭包:闭包是指函数能够访问其词法作用域外的变量,通过闭包可以实现数据的私有化和封装
function outerFunction() {
let count = 0;
return function() {
count++;
console.log(count);
};
}
let increment = outerFunction();
increment(); // 输出:1
increment(); // 输出:2
@前端进阶之旅: 代码已经复制到剪贴板
7. 作用域:JavaScript具有函数作用域和块级作用域,在不同的作用域中变量的可访问性不同
function example() {
let x = 10;
if (true) {
let y = 20;
console.log(x); // 输出:10
console.log(y); // 输出:20
}
}
@前端进阶之旅: 代码已经复制到剪贴板
8. 原型链:原型链是JavaScript中实现对象继承的机制,每个对象都有一个原型对象,形成一个链式结构
function Animal(name) {
this.name = name;
}
Animal.prototype.sayHello = function() {
console.log("Hello, I'm " + this.name);
};
function Dog(name, breed) {
this.breed = breed;
}
Dog.prototype = Object.create(Animal.prototype);
Dog.prototype.constructor = Dog;
let dog = new Dog("Max", "Labrador");
dog.sayHello();
@前端进阶之旅: 代码已经复制到剪贴板
9. 事件:JavaScript通过事件来响应用户的操作,可以通过事件监听和事件处理函数来实现
let button = document.getElementById("myButton");
button.addEventListener("click", function() {
console.log("Button clicked");
});
@前端进阶之旅: 代码已经复制到剪贴板
10. RegExp:正则表达式是一种用于匹配和操作字符串的强大工具,JavaScript中提供了内置的RegExp对象
let pattern = /[a-zA-Z]+/;
let text = "Hello, World!";
let result = pattern.test(text);
console.log(result); // 输出:true
@前端进阶之旅: 代码已经复制到剪贴板
11. JSON:JSON是一种用于数据交换的格式,JavaScript提供了JSON对象来进行解析和生成JSON数据
let jsonStr = '{"name":"poetry", "age":25}';
let obj = JSON.parse(jsonStr);
console.log(obj.name); // 输出:poetry
let obj2 = { name: "Jane", age: 30 };
let jsonStr2 = JSON.stringify(obj2);
console.log(jsonStr2); // 输出:{"name":"Jane","age":30}
@前端进阶之旅: 代码已经复制到剪贴板
12. Ajax:Ajax是一种在后台与服务器进行异步通信的技术,可以实现页面的局部刷新和动态数据加载
let xhr = new XMLHttpRequest();
xhr.open("GET", "https://api.example.com/data", true);
xhr.onreadystatechange = function() {
if (xhr.readyState === 4 && xhr.status === 200) {
let response = xhr.responseText;
console.log(response);
}
};
xhr.send();
@前端进阶之旅: 代码已经复制到剪贴板
13. DOM:DOM是JavaScript操作网页内容和结构的接口,可以通过DOM来增删改查网页元素
let element = document.getElementById("myElement");
element.innerHTML = "New content";
let newElement = document.createElement("div");
newElement.textContent = "Dynamic element";
document.body.appendChild(newElement);
@前端进阶之旅: 代码已经复制到剪贴板
14. BOM:BOM(浏览器对象模型)提供了与浏览器窗口交互的接口,如操作浏览器历史记录、定时器等
window.location.href = "https://www.example.com";
let screenWidth = window.screen.width;
let timer = setTimeout(function() {
console.log("Timer expired");
}, 5000);
@前端进阶之旅: 代码已经复制到剪贴板
15. 内存泄漏:内存泄漏是指无用的内存占用没有被释放,JavaScript中需要注意避免造成内存泄漏
function createHeavyObject() {
let bigArray = new Array(1000000).fill("data");
return bigArray;
}
let data = createHeavyObject();
// 释放无用的引用,帮助垃圾回收器回收内存
data = null;
@前端进阶之旅: 代码已经复制到剪贴板
16. 跨域:跨域是指在浏览器中访问不同源的资源,需要遵守同源策略或通过CORS等方式解决
// 跨域请求示例
let xhr = new XMLHttpRequest();
xhr.open("GET", "https://api.example.com/data", true);
xhr.withCredentials = true;
xhr.onreadystatechange = function() {
if (xhr.readyState === 4 && xhr.status === 200) {
let response = xhr.responseText;
console.log(response);
}
};
xhr.send();
@前端进阶之旅: 代码已经复制到剪贴板
17. 异步装载:通过异步加载资源,如图片、样式表和脚本,可以提高页面加载和性能
// 异步加载脚本
let script = document.createElement("script");
script.src = "https://example.com/script.js";
document.head.appendChild(script);
// 异步加载图片
let image = new Image();
image.src = "https://example.com/image.jpg";
image.onload = function() {
console.log("Image loaded");
};
@前端进阶之旅: 代码已经复制到剪贴板
18. 模板引擎:模板引擎是用于生成动态HTML内容的工具,可以将数据和模板进行结合生成最终的HTML
let data = { name: "poetry", age: 25 };
let template = `
<h1>My Profile</h1>
<p>Name: ${data.name}</p>
<p>Age: ${data.age}</p>
`;
document.getElementById("profileContainer").innerHTML = template;
@前端进阶之旅: 代码已经复制到剪贴板
19. 前端MVC:前端MVC(Model-View-Controller)是一种将应用程序分为数据模型、视图和控制器的架构模式
// 模型(Model)
let user = {
name: "poetry",
age: 25
};
// 视图(View)
function renderUser(user) {
let container = document.getElementById("userContainer");
container.innerHTML = `
<p>Name: ${user.name}</p>
<p>Age: ${user.age}</p>
`;
}
// 控制器(Controller)
function updateUserAge(newAge) {
user.age = newAge;
renderUser(user);
}
updateUserAge(30);
@前端进阶之旅: 代码已经复制到剪贴板
20. 路由:路由是指根据不同的URL路径切换不同的页面或视图,前端路由可以通过URL的变化来加载对应的组件或页面
// 设置路由规则
const routes = [
{ path: "/", component: Home },
{ path: "/about", component: About },
{ path: "/contact", component: Contact }
];
// 监听URL变化
window.addEventListener("hashchange", () => {
const path = window.location.hash.substring(1);
const route = routes.find(route => route.path === path);
if (route) {
const component = new route.component();
component.render();
}
});
// 渲染组件
class Home {
render() {
document.getElementById("app").innerHTML = "<h1>Home Page</h1>";
}
}
class About {
render() {
document.getElementById("app").innerHTML = "<h1>About Page</h1>";
}
}
class Contact {
render() {
document.getElementById("app").innerHTML = "<h1>Contact Page</h1>";
}
}
// 初始加载默认路由
window.location.hash = "/";
@前端进阶之旅: 代码已经复制到剪贴板
21. 模块化:JavaScript模块化通过将代码分割为独立的模块,每个模块具有自己的作用域和接口
// 模块A
export function add(a, b) {
return a + b;
}
export function multiply(a, b) {
return a * b;
}
// 模块B
import { add, multiply } from "./moduleA.js";
let sum = add(2, 3);
let product = multiply(4, 5);
@前端进阶之旅: 代码已经复制到剪贴板
22.Canvas:Canvas是HTML5提供的用于绘制图形和动画的API,可以通过JavaScript操作Canvas元素
let canvas = document.getElementById("myCanvas");
let ctx = canvas.getContext("2d");
ctx.fillStyle = "red";
ctx.fillRect(0, 0, canvas.width, canvas.height);
ctx.strokeStyle = "blue";
ctx.lineWidth = 2;
ctx.beginPath();
ctx.arc(100, 100, 50, 0, 2 * Math.PI);
ctx.stroke();
@前端进阶之旅: 代码已经复制到剪贴板
23. ECMAScript:ECMAScript是JavaScript的标准化规范,定义了语法、数据类型、函数等核心特性
// ECMAScript 6示例
let name = "poetry";
let age = 25;
let message = `My name is ${name} and I'm ${age} years old.`;
console.log(message);
@前端进阶之旅: 代码已经复制到剪贴板
这些是原生JavaScript的一些重要特性和示例代码,涵盖了数据类型、运算、对象、函数、继承、闭包、作用域、原型链、事件、正则表达式、JSON、Ajax、DOM、BOM、内存泄漏、跨域、异步装载、模板引擎、前端MVC、路由、模块化、Canvas和ECMAScript。当然,JavaScript还有许多其他特性和用法,这只是其中一部分。
57 Js动画与CSS动画区别及相应实现
在JavaScript中实现动画可以通过以下方式:
- 使用
setTimeout或setInterval函数结合DOM操作来实现逐帧动画。这种方式需要手动计算和控制每一帧的变化,并且需要注意处理动画的性能问题。
let element = document.getElementById("animate");
let position = 0;
function animate() {
position += 1;
element.style.left = position + "px";
if (position < 200) {
setTimeout(animate, 10);
}
}
animate();
@前端进阶之旅: 代码已经复制到剪贴板
- 使用
requestAnimationFrame函数来实现更高效的动画。requestAnimationFrame会在浏览器每一帧绘制之前调用指定的回调函数,可以更好地利用浏览器的刷新机制。
let element = document.getElementById("animate");
let position = 0;
function animate() {
position += 1;
element.style.left = position + "px";
if (position < 200) {
requestAnimationFrame(animate);
}
}
animate();
@前端进阶之旅: 代码已经复制到剪贴板
- 使用现代JavaScript动画库,如
GSAP(GreenSock Animation Platform),它提供了丰富的动画功能和更高级的控制选项。
let element = document.getElementById("animate");
gsap.to(element, {
x: 200,
duration: 1,
ease: "power2.out"
});
@前端进阶之旅: 代码已经复制到剪贴板
- 使用
Pixi.js实现动画方式
Pixi.js是一个基于WebGL的2D渲染引擎,它提供了丰富的功能和工具来创建高性能的动画效果。使用Pixi.js可以轻松实现复杂的动画效果,并且可以充分利用硬件加速来提高性能。
以下是使用Pixi.js实现动画的示例代码:
4.1 创建Pixi.js应用程序:
// 创建一个Pixi.js应用程序
const app = new PIXI.Application({
width: 800,
height: 600,
backgroundColor: 0x000000
});
// 将Pixi.js应用程序添加到HTML文档中的某个元素中
document.getElementById("container").appendChild(app.view);
@前端进阶之旅: 代码已经复制到剪贴板
4.2 创建并添加精灵对象:
// 创建一个精灵对象
const sprite = PIXI.Sprite.from("image.png");
// 设置精灵对象的位置和缩放
sprite.x = 100;
sprite.y = 100;
sprite.scale.set(0.5);
// 将精灵对象添加到舞台中
app.stage.addChild(sprite);
@前端进阶之旅: 代码已经复制到剪贴板
4.3 实现动画效果:
// 创建一个Tween动画对象
const tween = PIXI.tweenManager.createTween(sprite);
// 设置动画的起始位置和结束位置
tween.from({ x: 100, y: 100 }).to({ x: 500, y: 300 });
// 设置动画的持续时间和缓动函数
tween.time = 1000;
tween.easing = PIXI.tween.Easing.outCubic;
// 开始动画
tween.start();
@前端进阶之旅: 代码已经复制到剪贴板
通过使用Pixi.js提供的TweenManager和Tween类,我们可以轻松地创建和控制动画效果。可以设置动画对象的起始状态、结束状态、持续时间和缓动函数,然后调用start()方法开始动画。
除了Tween动画,Pixi.js还提供了许多其他功能,如粒子效果、骨骼动画、滤镜效果等,可以根据具体需求选择合适的方式来实现动画效果。
需要注意的是,使用Pixi.js来实现动画需要先引入Pixi.js库,并在HTML文档中创建一个容器元素用于显示Pixi.js应用程序的画布。
<div id="container"></div>
@前端进阶之旅: 代码已经复制到剪贴板
然后通过上述示例代码来创建Pixi.js应用程序,并实现所需的动画效果。
相比之下,CSS动画具有以下优点:
- 性能优化:浏览器可以对CSS动画进行硬件加速,以提高动画的性能和流畅度。
- 简单易用:使用CSS关键帧动画可以通过简单的CSS样式声明来定义动画,代码相对简单。
- 兼容性:CSS动画在现代浏览器中得到很好的支持,并且在某些情况下可以更好地处理动画效果。
然而,CSS动画也有一些限制:
- 控制能力受限:CSS动画通常只能实现简单的线性或简单的缓动效果,对于复杂的动画效果和交互控制,可能需要使用JavaScript来实现。
- 兼容性局限:某些老版本的浏览器可能不支持某些CSS动画属性和效果。
因此,根据实际需求和性能考虑,选择合适的动画实现方式是很重要的。在简单的动画效果和性能要求较高时,可以优先考虑使用CSS动画;而在复杂的动画控制和交互需求时,使用JavaScript来实现动画更为灵活。
58 JS 数组和对象的遍历方式,以及几种方式的比较
数组的遍历方式:
1. for循环:
- 可以使用普通的
for循环来遍历数组元素。 - 优点:灵活性高,可以根据索引进行操作。
- 缺点:代码相对繁琐,需要手动管理索引。
const array = [1, 2, 3];
for (let i = 0; i < array.length; i++) {
console.log(array[i]);
}
@前端进阶之旅: 代码已经复制到剪贴板
2. forEach方法:
- 使用数组的
forEach方法进行遍历。 - 优点:简洁、易读,无需手动管理索引。
- 缺点:无法使用
break和continue跳出循环。
const array = [1, 2, 3];
array.forEach((element) => {
console.log(element);
});
@前端进阶之旅: 代码已经复制到剪贴板
3. for…of循环:
- 使用
for...of循环来遍历数组。 - 优点:语法简洁,无需手动管理索引,可以遍历任何可迭代对象。
- 缺点:无法获取当前元素的索引。
const array = [1, 2, 3];
for (const element of array) {
console.log(element);
}
@前端进阶之旅: 代码已经复制到剪贴板
4. map方法:
- 使用数组的
map方法进行遍历并返回新数组。 - 优点:可以同时遍历和转换数组的元素,返回一个新数组。
- 缺点:不适合仅需要遍历而不需要返回新数组的情况。
const array = [1, 2, 3];
const mappedArray = array.map((element) => element * 2);
console.log(mappedArray);
@前端进阶之旅: 代码已经复制到剪贴板
对象的遍历方式:
1. for…in循环:
for...in循环是用于遍历对象属性的,但也可用于遍历数组。- 优点:可以遍历数组的索引或属性。
- 缺点:会遍历数组的原型链,不稳定且性能较差,不推荐在数组上使用。
const obj = { a: 1, b: 2, c: 3 };
for (const key in obj) {
console.log(key, obj[key]);
}
@前端进阶之旅: 代码已经复制到剪贴板
2. Object.keys方法结合forEach方法:
const obj = { a: 1, b: 2, c: 3 };
Object.keys(obj).forEach((key) => {
console.log(key, obj[key]);
});
@前端进阶之旅: 代码已经复制到剪贴板
3. Object.entries方法结合forEach方法:
const obj = { a: 1, b: 2, c: 3 };
Object.entries(obj).forEach(([key, value]) => {
console.log(key, value);
});
@前端进阶之旅: 代码已经复制到剪贴板
比较总结:
for循环是最基本的遍历方式,适用于所有情况,但代码较为繁琐。forEach方法是数组专用的遍历方法,代码简洁,但无法使用break和continue跳出循环。for...of循环适用于遍历可迭代对象,如数组、字符串等,语法简单,但无法获取索引。map方法适用于对数组进行映射转换,返回新数组。for...in循环适用于遍历对象的属性,但会遍历原型链上的属性。Object.keys方法结合forEach方法适用于遍历对象的属性,不遍历原型链。Object.entries方法结合forEach方法适用于遍历对象的键值对。
根据不同的需求和数据结构,选择合适的遍历方式可以提高代码的可读性和性能。使用基本的
for循环可以处理各种情况,forEach和map方法提供了简洁的数组遍历方式,for...of循环适用于遍历可迭代对象,for...in循环和Object.keys/Object.entries结合forEach方法适用于遍历对象的属性和键值对。
59 gulp是什么
gulp`是前端开发过程中一种基于流的代码构建工具,是自动化项目的构建利器;它不仅能对网站资源进行优化,而且在开发过程中很多重复的任务能够使用正确的工具自动完成
- Gulp的核心概念:流,简单来说就是建立在面向对象基础上的一种抽象的处理数据的工具。在流中,定义了一些处理数据的基本操作,如读取数据,写入数据等,程序员是对流进行所有操作的,而不用关心流的另一头数据的真正流向
- gulp正是通过流和代码优于配置的策略来尽量简化任务编写的工作
- Gulp的特点:
- 易于使用:通过代码优于配置的策略,gulp 让简单的任务简单,复杂的任务可管理
- 构建快速 利用
Node.js流的威力,你可以快速构建项目并减少频繁的IO操作 - 易于学习 通过最少的
API,掌握gulp毫不费力,构建工作尽在掌握:如同一系列流管道
const gulp = require('gulp');
const cleanCSS = require('gulp-clean-css');
// 压缩CSS任务
gulp.task('minify-css', () => {
return gulp.src('src/css/*.css')
.pipe(cleanCSS())
.pipe(gulp.dest('dist/css'));
});
// 默认任务
gulp.task('default', gulp.series('minify-css'));
@前端进阶之旅: 代码已经复制到剪贴板
上述示例定义了一个名为minify-css的任务,用于压缩CSS文件。通过使用gulp.src选择要处理的文件,然后通过cleanCSS插件进行压缩操作,最后将压缩后的文件保存到dist/css目录下。通过gulp.task定义任务,最后通过gulp.series定义默认任务,将minify-css任务作为默认任务执行。
总结:
Gulp的特点在于其简单的API和基于流的处理方式。通过使用Gulp,开发者可以轻松地定义和执行各种任务,提高开发效率。它的易用性、快速构建和易学性使得Gulp成为前端开发中常用的自动化构建工具之一
加载中...
加载中...
加载中...
加载中...
加载中...
65 怎样添加、移除、移动、复制、创建和查找节点
下面是一些用于添加、移除、移动、复制、创建和查找节点的常用方法:
创建新节点
document.createElement(tagName); // 创建一个指定标签名的元素节点
document.createTextNode(text); // 创建一个包含指定文本的文本节点
document.createDocumentFragment(); // 创建一个空的文档片段节点
@前端进阶之旅: 代码已经复制到剪贴板
添加、移除、替换、插入节点
parentNode.appendChild(node); // 在父节点的末尾添加一个子节点
parentNode.removeChild(node); // 从父节点中移除指定的子节点
parentNode.replaceChild(newNode, oldNode); // 用新节点替换指定的旧节点
parentNode.insertBefore(newNode, referenceNode); // 在参考节点之前插入一个新节点
@前端进阶之旅: 代码已经复制到剪贴板
查找节点
document.getElementsByTagName(tagName); // 返回指定标签名的元素节点集合
document.getElementsByName(name); // 返回具有指定名称的元素节点集合
document.getElementById(id); // 返回具有指定 id 的元素节点
@前端进阶之旅: 代码已经复制到剪贴板
注意,以上方法都是基于document对象进行操作的,如果需要在特定的节点上执行这些操作,可以使用相应节点的方法,例如parentNode.appendChild(node)。
示例代码:
// 创建新节点
var newElement = document.createElement('div');
var newText = document.createTextNode('Hello, world!');
var fragment = document.createDocumentFragment();
// 添加节点
document.body.appendChild(newElement);
newElement.appendChild(newText);
// 移除节点
document.body.removeChild(newElement);
// 替换节点
var oldElement = document.getElementById('old');
var newElement = document.createElement('div');
document.body.replaceChild(newElement, oldElement);
// 插入节点
var referenceElement = document.getElementById('reference');
var newNode = document.createElement('p');
document.body.insertBefore(newNode, referenceElement);
// 查找节点
var elementsByTagName = document.getElementsByTagName('div');
var elementsByName = document.getElementsByName('name');
var elementById = document.getElementById('id');
@前端进阶之旅: 代码已经复制到剪贴板
以上代码演示了如何创建新节点、添加节点、移除节点、替换节点、插入节点以及查找节点的方法。请根据实际情况调整代码并操作相应的节点。
66 正则表达式
正则表达式构造函数RegExp()和正则表达字面量的主要区别在于语法和使用方式。
正则表达式构造函数 RegExp()
- 使用字符串作为参数,需要进行双重转义,即需要使用双反斜杠来表示特殊字符,如
\d表示数字,\w表示字母数字下划线等。 - 构造函数的参数可以是一个字符串,也可以是两个字符串,第一个字符串是正则表达式模式,第二个字符串是修饰符。
- 如果正则表达式模式是一个变量,只能使用构造函数的方式创建正则表达式。
正则表达字面量 //
- 使用两个斜杠
//将正则表达式包围起来。 - 字面量的方式更简洁,不需要进行双重转义,直接使用特殊字符即可。
- 正则表达式字面量的模式和修饰符直接写在斜杠之间。
在前端面试中,正则表达式是一个常见的考点。以下是一些与正则表达式相关的重要知识点总结:
1. 基本语法
- 正则表达式是由字符和特殊字符组成的模式,用于匹配字符串中的文本。
- 常见的特殊字符包括元字符(如
.、*、+、?等)和字符类(如[...]、[^...]、\d、\w等)。
2. 匹配模式
- 使用正则表达式可以进行文本匹配、查找、替换等操作。
- 匹配模式可以包括固定文本和通配符,用于定义要匹配的模式。
- 量词(如
*、+、?、{n}、{n,m}等)用于指定匹配的次数。
3. 常见的正则表达式应用场景
- 邮箱验证:匹配邮箱的正则表达式可以验证邮箱的合法性。
- 密码验证:通过正则表达式可以验证密码的复杂度要求。
- 手机号验证:使用正则表达式可以验证手机号码的格式是否正确。
- URL 提取:通过正则表达式可以从文本中提取出符合 URL 格式的链接。
- HTML 标签处理:正则表达式可以用于匹配和处理 HTML 标签。
- 字符串替换:使用正则表达式可以进行字符串的替换操作。
4. 常见的正则表达式方法
test():测试字符串是否匹配正则表达式。exec():在字符串中查找匹配的文本,并返回匹配结果。match():在字符串中查找匹配的文本,并返回所有匹配结果的数组。search():在字符串中查找匹配的文本,并返回第一个匹配结果的索引。replace():将匹配的文本替换为指定的字符串。split():根据正则表达式将字符串拆分为数组。
// 示例字符串
const str = 'Hello, World! This is a test string.';
// test(): 测试字符串是否匹配正则表达式
const regex1 = /test/;
console.log(regex1.test(str)); // true
// exec(): 在字符串中查找匹配的文本,并返回匹配结果
const regex2 = /is/g;
let result;
while ((result = regex2.exec(str)) !== null) {
console.log(result[0]); // "is" (每次循环匹配的结果)
console.log(result.index); // 匹配的起始索引
}
// match(): 在字符串中查找匹配的文本,并返回所有匹配结果的数组
const regex3 = /o/g;
console.log(str.match(regex3)); // ["o", "o", "o"]
// search(): 在字符串中查找匹配的文本,并返回第一个匹配结果的索引
const regex4 = /World/;
console.log(str.search(regex4)); // 7
// replace(): 将匹配的文本替换为指定的字符串
const regex5 = /test/;
const newStr = str.replace(regex5, 'replacement');
console.log(newStr); // "Hello, World! This is a replacement string."
// split(): 根据正则表达式将字符串拆分为数组
const regex6 = /[,!\s]/;
const arr = str.split(regex6);
console.log(arr); // ["Hello", "World", "This", "is", "a", "test", "string"]
@前端进阶之旅: 代码已经复制到剪贴板
5. 贪婪匹配和非贪婪匹配
- 贪婪匹配是指正则表达式默认匹配尽可能长的字符串。
- 非贪婪匹配是指正则表达式匹配尽可能短的字符串,在量词后加上
?实现非贪婪匹配。
以下是一些常见的正则表达式面试题考点及其答案总结:
1. 什么是正则表达式?
正则表达式是一种用于匹配和操作字符串的模式,它由字符和特殊字符组成,用于定义匹配规则。
2. 正则表达式的创建方式有哪些?
正则表达式可以通过两种方式创建:
- 字面量方式:使用两个斜杠
//将正则表达式包围起来,如:/pattern/。 - 构造函数方式:使用
RegExp()构造函数创建,接受一个字符串参数,如:new RegExp("pattern")。
3. 常见的正则表达式修饰符有哪些?
常见的正则表达式修饰符包括:
i:不区分大小写匹配。g:全局匹配,找到所有匹配项。m:多行匹配,将^和$应用到每一行。
4. 常用的正则表达式元字符有哪些?
常用的正则表达式元字符包括:
.:匹配除换行符以外的任意字符。^:匹配字符串的开始位置。$:匹配字符串的结束位置。\d:匹配数字字符。\w:匹配字母、数字、下划线。\s:匹配空白字符。
5. 如何匹配邮箱地址?
可以使用以下正则表达式进行邮箱地址的匹配:
/^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$/;
@前端进阶之旅: 代码已经复制到剪贴板
6. 如何匹配手机号码? 可以使用以下正则表达式进行手机号码的匹配:
/^1[3456789]\d{9}$/;
@前端进阶之旅: 代码已经复制到剪贴板
7. 如何匹配 URL 地址?
可以使用以下正则表达式进行 URL 地址的匹配:
/^(https?:\/\/)?([\da-z.-]+)\.([a-z.]{2,6})(\/[\w.-]*)*\/?$/;
@前端进阶之旅: 代码已经复制到剪贴板
8. 如何提取字符串中的数字部分? 可以使用以下正则表达式提取字符串中的数字部分:
/\d+/g;
@前端进阶之旅: 代码已经复制到剪贴板
9. 如何验证密码的复杂度要求?
可以使用以下正则表达式验证密码的复杂度要求,包括至少包含一个大写字母、一个小写字母和一个数字,长度为8-20个字符:
/^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,20}$/;
@前端进阶之旅: 代码已经复制到剪贴板
10. 如何匹配日期格式(YYYY-MM-DD)?
可以使用以下正则表达式匹配日期格式(YYYY-MM-DD):
/^\d{4}-\d{2}-\d{2}$/;
@前端进阶之旅: 代码已经复制到剪贴板
11. 如何匹配 IP 地址?
可以使用以下正则表达式匹配 IP 地址:
/^((25[0-5]|2[0-4]\d|[01]?\d{1,2})\.){3}(25[0-5]|2[0-4]\d|[01]?\d{1,2})$/;
@前端进阶之旅: 代码已经复制到剪贴板
12. 如何匹配 HTML 标签?
可以使用以下正则表达式匹配 HTML 标签:
/<[^>]+>/g;
@前端进阶之旅: 代码已经复制到剪贴板
13. 如何移除字符串中的 HTML 标签?
可以使用以下正则表达式移除字符串中的 HTML 标签:
str.replace(/<[^>]+>/g, '');
@前端进阶之旅: 代码已经复制到剪贴板
67 Javascript中callee和caller的作用?
callee和caller是两个旧的非标准属性,它们在现代的 JavaScript 中已经不推荐使用,且在严格模式下不可用。
caller属性:caller属性用于获取调用当前函数的函数的引用。它返回一个函数对象或者null。这个属性主要用于追踪函数的调用来源。但由于其潜在的安全性问题和性能问题,它已经被废弃了,并且在严格模式下无法使用。callee属性:callee属性返回当前正在执行的函数的引用。它通常在匿名函数或递归函数中使用,允许函数引用自身。但同样由于其潜在的安全性和性能问题,它也已经被废弃了,并且在严格模式下无法使用。
应该尽量避免使用caller和callee属性,而使用更现代的 JavaScript 特性和技术来完成相应的任务。例如,可以使用具名函数表达式来递归调用函数,使用函数引用作为参数传递来追踪函数调用的来源。
以下是一个示例,
如果一对兔子每月生一对兔子;一对新生兔,从第二个月起就开始生兔子;假定每对兔子都是一雌一雄,试问一对兔子,第n个月能繁殖成多少对兔子?(使用callee完成)
var result=[];
function fn(n){ //典型的斐波那契数列
if(n==1){
return 1;
}else if(n==2){
return 1;
}else{
if(result[n]){
return result[n];
}else{
//argument.callee()表示fn()
result[n]=arguments.callee(n-1)+arguments.callee(n-2);
return result[n];
}
}
}
@前端进阶之旅: 代码已经复制到剪贴板
以下是一个示例,展示了如何使用具名函数表达式进行递归调用:
const factorial = function calculateFactorial(n) {
if (n <= 1) {
return 1;
}
return n * calculateFactorial(n - 1);
};
console.log(factorial(5)); // 输出: 120
@前端进阶之旅: 代码已经复制到剪贴板
在这个示例中,使用具名函数表达式calculateFactorial来递归调用自身,计算阶乘的结果。这种方式比使用callee属性更清晰和可维护。
总结
caller是返回一个对函数的引用,该函数调用了当前函数;callee是返回正在被执行的function函数,也就是所指定的function对象的正文
68 window.onload和$(document).ready
原生
JS的window.onload与Jquery的$(document).ready(function(){})有什么不同?如何用原生JS实现Jq的ready方法?
window.onload()方法是必须等到页面内包括图片的所有元素加载完毕后才能执行。$(document).ready()是DOM结构绘制完毕后就执行,不必等到加载完毕
function ready(fn){
if(document.addEventListener) { //标准浏览器
document.addEventListener('DOMContentLoaded', function() {
//注销事件, 避免反复触发
document.removeEventListener('DOMContentLoaded',arguments.callee, false);
fn(); //执行函数
}, false);
}else if(document.attachEvent) { //IE
document.attachEvent('onreadystatechange', function() {
if(document.readyState == 'complete') {
document.detachEvent('onreadystatechange', arguments.callee);
fn(); //函数执行
}
});
}
};
@前端进阶之旅: 代码已经复制到剪贴板
69 addEventListener()和attachEvent()的区别
addEventListener()是DOM Level 2 标准定义的方法,而attachEvent()是早期IE浏览器的非标准方法。addEventListener()可以为同一个元素的同一个事件类型添加多个事件处理函数,而attachEvent()只能绑定一个事件处理函数。addEventListener()使用事件捕获阶段或冒泡阶段来处理事件,可以通过第三个参数来指定是在捕获阶段处理还是在冒泡阶段处理。而attachEvent()只能在冒泡阶段处理事件。addEventListener()的事件处理函数中的this指向触发事件的元素,而attachEvent()的事件处理函数中的this指向window对象。addEventListener()中的事件处理函数可以通过event参数来获取事件信息,而attachEvent()的事件处理函数需要通过window.event来获取事件信息。
由于attachEvent()是早期IE浏览器的非标准方法,且在现代浏览器中已经被废弃,推荐使用addEventListener()来绑定事件。
70 获取页面所有的checkbox
var resultArr= [];
var input = document.querySelectorAll('input');
for(var i = 0; i < input.length; i++ ) {
if(input[i].type == 'checkbox') {
resultArr.push( input[i] );
}
}
//resultArr即中获取到了页面中的所有checkbox
@前端进阶之旅: 代码已经复制到剪贴板
71 数组去重方法总结
方法一、利用ES6 Set去重(ES6中最常用)
function unique (arr) {
return Array.from(new Set(arr))
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {}, {}]
@前端进阶之旅: 代码已经复制到剪贴板
方法二、利用for嵌套for,然后splice去重(ES5中最常用)
function unique(arr){
for(var i=0; i<arr.length; i++){
for(var j=i+1; j<arr.length; j++){
if(arr[i]==arr[j]){ //第一个等同于第二个,splice方法删除第二个
arr.splice(j,1);
j--;
}
}
}
return arr;
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", 15, false, undefined, NaN, NaN, "NaN", "a", {…}, {…}] //NaN和{}没有去重,两个null直接消失了
@前端进阶之旅: 代码已经复制到剪贴板
- 双层循环,外层循环元素,内层循环时比较值。值相同时,则删去这个值。
- 想快速学习更多常用的
ES6语法
方法三、利用indexOf去重
function unique(arr) {
if (!Array.isArray(arr)) {
console.log('type error!')
return
}
var array = [];
for (var i = 0; i < arr.length; i++) {
if (array .indexOf(arr[i]) === -1) {
array .push(arr[i])
}
}
return array;
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
// [1, "true", true, 15, false, undefined, null, NaN, NaN, "NaN", 0, "a", {…}, {…}] //NaN、{}没有去重
@前端进阶之旅: 代码已经复制到剪贴板
新建一个空的结果数组,
for循环原数组,判断结果数组是否存在当前元素,如果有相同的值则跳过,不相同则push进数组
方法四、利用sort()
function unique(arr) {
if (!Array.isArray(arr)) {
console.log('type error!')
return;
}
arr = arr.sort()
var arrry= [arr[0]];
for (var i = 1; i < arr.length; i++) {
if (arr[i] !== arr[i-1]) {
arrry.push(arr[i]);
}
}
return arrry;
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
// [0, 1, 15, "NaN", NaN, NaN, {…}, {…}, "a", false, null, true, "true", undefined] //NaN、{}没有去重
@前端进阶之旅: 代码已经复制到剪贴板
利用
sort()排序方法,然后根据排序后的结果进行遍历及相邻元素比对
方法五、利用对象的属性不能相同的特点进行去重
function unique(arr) {
if (!Array.isArray(arr)) {
console.log('type error!')
return
}
var arrry= [];
var obj = {};
for (var i = 0; i < arr.length; i++) {
if (!obj[arr[i]]) {
arrry.push(arr[i])
obj[arr[i]] = 1
} else {
obj[arr[i]]++
}
}
return arrry;
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", 15, false, undefined, null, NaN, 0, "a", {…}] //两个true直接去掉了,NaN和{}去重
@前端进阶之旅: 代码已经复制到剪贴板
方法六、利用includes
function unique(arr) {
if (!Array.isArray(arr)) {
console.log('type error!')
return
}
var array =[];
for(var i = 0; i < arr.length; i++) {
if( !array.includes( arr[i]) ) {//includes 检测数组是否有某个值
array.push(arr[i]);
}
}
return array
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}, {…}] //{}没有去重
@前端进阶之旅: 代码已经复制到剪贴板
方法七、利用hasOwnProperty
function unique(arr) {
var obj = {};
return arr.filter(function(item, index, arr){
return obj.hasOwnProperty(typeof item + item) ? false : (obj[typeof item + item] = true)
})
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}] //所有的都去重了
@前端进阶之旅: 代码已经复制到剪贴板
利用
hasOwnProperty判断是否存在对象属性
方法八、利用filter
function unique(arr) {
return arr.filter(function(item, index, arr) {
//当前元素,在原始数组中的第一个索引==当前索引值,否则返回当前元素
return arr.indexOf(item, 0) === index;
});
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", true, 15, false, undefined, null, "NaN", 0, "a", {…}, {…}]
@前端进阶之旅: 代码已经复制到剪贴板
方法九、利用递归去重
function unique(arr) {
var array= arr;
var len = array.length;
array.sort(function(a,b){ //排序后更加方便去重
return a - b;
})
function loop(index){
if(index >= 1){
if(array[index] === array[index-1]){
array.splice(index,1);
}
loop(index - 1); //递归loop,然后数组去重
}
}
loop(len-1);
return array;
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "a", "true", true, 15, false, 1, {…}, null, NaN, NaN, "NaN", 0, "a", {…}, undefined]
@前端进阶之旅: 代码已经复制到剪贴板
方法十、利用Map数据结构去重
function arrayNonRepeatfy(arr) {
let map = new Map();
let array = new Array(); // 数组用于返回结果
for (let i = 0; i < arr.length; i++) {
if(map .has(arr[i])) { // 如果有该key值
map .set(arr[i], true);
} else {
map .set(arr[i], false); // 如果没有该key值
array .push(arr[i]);
}
}
return array ;
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "a", "true", true, 15, false, 1, {…}, null, NaN, NaN, "NaN", 0, "a", {…}, undefined]
@前端进阶之旅: 代码已经复制到剪贴板
创建一个空
Map数据结构,遍历需要去重的数组,把数组的每一个元素作为key存到Map中。由于Map中不会出现相同的key值,所以最终得到的就是去重后的结果
方法十一、利用reduce+includes
function unique(arr){
return arr.reduce((prev,cur) => prev.includes(cur) ? prev : [...prev,cur],[]);
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr));
// [1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}, {…}]
@前端进阶之旅: 代码已经复制到剪贴板
方法十二、[…new Set(arr)]
[...new Set(arr)]
//代码就是这么少----(其实,严格来说并不算是一种,相对于第一种方法来说只是简化了代码)
@前端进阶之旅: 代码已经复制到剪贴板
72 (设计题)想实现一个对页面某个节点的拖曳?如何做?(使用原生JS)
- 给需要拖拽的节点绑定
mousedown,mousemove,mouseup事件 mousedown事件触发后,开始拖拽mousemove时,需要通过event.clientX和clientY获取拖拽位置,并实时更新位置mouseup时,拖拽结束- 需要注意浏览器边界的情况
下面是一个使用原生 JavaScript 实现页面节点拖拽的示例代码:
// 获取需要拖拽的节点
var draggableNode = document.getElementById("draggable");
// 初始化拖拽状态
var isDragging = false;
var offset = { x: 0, y: 0 };
// 绑定 mousedown 事件
draggableNode.addEventListener("mousedown", function(event) {
// 设置拖拽状态为 true
isDragging = true;
// 计算鼠标相对于节点的偏移量
offset.x = event.clientX - draggableNode.offsetLeft;
offset.y = event.clientY - draggableNode.offsetTop;
});
// 绑定 mousemove 事件
document.addEventListener("mousemove", function(event) {
// 如果处于拖拽状态
if (isDragging) {
// 计算节点的新位置
var left = event.clientX - offset.x;
var top = event.clientY - offset.y;
// 更新节点的位置
draggableNode.style.left = left + "px";
draggableNode.style.top = top + "px";
}
});
// 绑定 mouseup 事件
document.addEventListener("mouseup", function() {
// 设置拖拽状态为 false
isDragging = false;
});
@前端进阶之旅: 代码已经复制到剪贴板
在上面的代码中,首先获取需要拖拽的节点 draggableNode,然后初始化拖拽状态和偏移量。在 mousedown 事件中,设置拖拽状态为 true,并计算鼠标相对于节点的偏移量。在 mousemove 事件中,如果处于拖拽状态,根据鼠标位置和偏移量计算节点的新位置,并更新节点的 left 和 top 样式。最后,在 mouseup 事件中,设置拖拽状态为 false,表示拖拽结束。
需要注意的是,上述代码只实现了简单的拖拽功能,如果需要考虑边界情况、拖拽限制等,还需要进行适当的处理。
73 Javascript全局函数和全局变量
全局变量
Infinity代表正的无穷大的数值。NaN指示某个值是不是数字值。undefined指示未定义的值。Date表示日期和时间的对象。Math包含了数学相关的函数和常量。JSON用于解析和序列化 JSON 数据的对象。console用于在控制台输出信息的对象。document表示当前 HTML 文档的对象。window表示浏览器窗口的对象。
全局函数
decodeURI()解码某个编码的URI。decodeURIComponent()解码一个编码的URI组件。encodeURI()把字符串编码为 URI。encodeURIComponent()把字符串编码为URI组件。escape()对字符串进行编码。eval()计算JavaScript字符串,并把它作为脚本代码来执行。isFinite()检查某个值是否为有穷大的数。isNaN()检查某个值是否是数字。Number()把对象的值转换为数字。parseInt()解析一个字符串并返回一个整数。String()把对象的值转换为字符串。unescape()对由escape()编码的字符串进行解码setTimeout()在指定的延迟时间后执行一次函数。setInterval()每隔指定的时间间隔重复执行函数。clearTimeout()取消使用setTimeout()创建的延迟执行。clearInterval()取消使用setInterval()创建的重复执行。alert()在浏览器中显示一个警告框。confirm()在浏览器中显示一个确认框。prompt()在浏览器中显示一个提示框,接收用户输入
74 使用js实现一个持续的动画效果
定时器思路
var e = document.getElementById('e')
var flag = true;
var left = 0;
setInterval(() => {
left == 0 ? flag = true : left == 100 ? flag = false : ''
flag ? e.style.left = ` ${left++}px` : e.style.left = ` ${left--}px`
}, 1000 / 60)
@前端进阶之旅: 代码已经复制到剪贴板
requestAnimationFrame
//兼容性处理
window.requestAnimFrame = (function(){
return window.requestAnimationFrame ||
window.webkitRequestAnimationFrame ||
window.mozRequestAnimationFrame ||
function(callback){
window.setTimeout(callback, 1000 / 60);
};
})();
var e = document.getElementById("e");
var flag = true;
var left = 0;
function render() {
left == 0 ? flag = true : left == 100 ? flag = false : '';
flag ? e.style.left = ` ${left++}px` :
e.style.left = ` ${left--}px`;
}
(function animloop() {
render();
requestAnimFrame(animloop);
})();
@前端进阶之旅: 代码已经复制到剪贴板
使用css实现一个持续的动画效果
animation:mymove 5s infinite;
@keyframes mymove {
from {top:0px;}
to {top:200px;}
}
@前端进阶之旅: 代码已经复制到剪贴板
animation-name规定需要绑定到选择器的keyframe名称。animation-duration规定完成动画所花费的时间,以秒或毫秒计。animation-timing-function规定动画的速度曲线。animation-delay规定在动画开始之前的延迟。animation-iteration-count规定动画应该播放的次数。animation-direction规定是否应该轮流反向播放动画
75 封装一个函数,参数是定时器的时间,.then执行回调函数
function sleep (time) {
return new Promise((resolve) => setTimeout(resolve, time));
}
@前端进阶之旅: 代码已经复制到剪贴板
// 测试
sleep(3000).then(() => {
console.log('定时器结束,执行回调函数');
});
@前端进阶之旅: 代码已经复制到剪贴板
76 怎么判断两个对象相等?
obj={
a:1,
b:2
}
obj2={
a:1,
b:2
}
obj3={
a:1,
b:'2'
}
@前端进阶之旅: 代码已经复制到剪贴板
- 使用
JSON.stringify():将对象转换为字符串,然后进行比较。这种方式适用于对象中的属性值都是基本数据类型,并且属性的顺序对比较结果无影响。
JSON.stringify(obj) === JSON.stringify(obj2); // true
JSON.stringify(obj) === JSON.stringify(obj3); // false
@前端进阶之旅: 代码已经复制到剪贴板
- 使用循环遍历:逐个比较对象的属性值。这种方式适用于对象中的属性值类型复杂,包括嵌套对象或数组。
function deepEqual(obj1, obj2) {
// 比较基本数据类型的值
if (obj1 === obj2) {
return true;
}
// 比较对象的属性个数
if (Object.keys(obj1).length !== Object.keys(obj2).length) {
return false;
}
// 逐个比较对象的属性值
for (let key in obj1) {
if (!obj2.hasOwnProperty(key) || !deepEqual(obj1[key], obj2[key])) {
return false;
}
}
return true;
}
deepEqual(obj, obj2); // true
deepEqual(obj, obj3); // false
@前端进阶之旅: 代码已经复制到剪贴板
- 使用
lodash库的isEqual()方法:lodash是一个流行的 JavaScript 工具库,其中的isEqual()方法可以比较两个对象是否相等,包括深度比较。
首先,需要通过npm install lodash命令安装lodash库,然后在代码中引入isEqual()方法:
const _ = require('lodash');
_.isEqual(obj, obj2); // true
_.isEqual(obj, obj3); // false
@前端进阶之旅: 代码已经复制到剪贴板
加载中...
加载中...
加载中...
加载中...
81 深浅拷贝
浅拷贝
- 使用
Object.assign()方法
let obj1 = { a: 1, b: 2 };
let obj2 = Object.assign({}, obj1);
console.log(obj2); // { a: 1, b: 2 }
@前端进阶之旅: 代码已经复制到剪贴板
- 使用展开运算符
let obj1 = { a: 1, b: 2 };
let obj2 = { ...obj1 };
console.log(obj2); // { a: 1, b: 2 }
@前端进阶之旅: 代码已经复制到剪贴板
深拷贝
1. 使用递归实现深拷贝函数
function deepClone(obj) {
if (obj === null || typeof obj !== 'object') {
return obj;
}
let clone = Array.isArray(obj) ? [] : {};
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
clone[key] = deepClone(obj[key]);
}
}
return clone;
}
let obj1 = {
a: 1,
b: { c: 2 }
};
let obj2 = deepClone(obj1);
obj2.b.c = 3;
console.log(obj1.b.c); // 2
console.log(obj2.b.c); // 3
@前端进阶之旅: 代码已经复制到剪贴板
2. 使用第三方库 lodash 的 cloneDeep() 方法
const _ = require('lodash');
let obj1 = {
a: 1,
b: { c: 2 }
};
let obj2 = _.cloneDeep(obj1);
obj2.b.c = 3;
console.log(obj1.b.c); // 2
console.log(obj2.b.c); // 3
@前端进阶之旅: 代码已经复制到剪贴板
3. 使用 JSON.parse(JSON.stringify()) 实现深拷贝
let obj1 = {
a: 1,
b: { c: 2 }
};
let obj2 = JSON.parse(JSON.stringify(obj1));
obj2.b.c = 3;
console.log(obj1.b.c); // 2
console.log(obj2.b.c); // 3
@前端进阶之旅: 代码已经复制到剪贴板
该方法也是有局限性的
- 会忽略
undefined - 不能序列化函数
- 不能解决循环引用的对象
JSON.stringify() 方法在实现深拷贝时有一些局限性,包括:
- 无法处理函数:
JSON.stringify()方法在序列化对象时会忽略函数属性,因为函数不符合 JSON 格式的数据类型。经过序列化和反序列化后,函数属性会丢失。
let obj = {
name: 'poetry',
sayHello: function() {
console.log('Hello!');
}
};
let serializedObj = JSON.stringify(obj);
let clonedObj = JSON.parse(serializedObj);
console.log(clonedObj.name); // 'poetry'
console.log(typeof clonedObj.sayHello); // 'undefined'
@前端进阶之旅: 代码已经复制到剪贴板
- 无法处理循环引用:如果对象存在循环引用,即对象内部包含对自身的引用,
JSON.stringify()方法无法正确处理,会导致循环引用的属性被序列化为null。
let obj = {
name: 'poetry'
};
obj.self = obj;
let serializedObj = JSON.stringify(obj);
console.log(serializedObj); // {"name":"poetry","self":null}
@前端进阶之旅: 代码已经复制到剪贴板
- 无法处理特殊对象:
JSON.stringify()方法无法序列化某些特殊对象,如Date对象、正则表达式、Map、Set等,它们在序列化过程中会转换成空对象。
let obj = {
now: new Date(),
regex: /[a-z]+/,
set: new Set([1, 2, 3]),
map: new Map([[1, 'one'], [2, 'two']])
};
let serializedObj = JSON.stringify(obj);
console.log(serializedObj); // {"now":{},"regex":{},"set":{},"map":{}}
@前端进阶之旅: 代码已经复制到剪贴板
- 无法处理
undefined属性:JSON.stringify()方法在序列化对象时会忽略undefined属性,序列化后的结果不包含该属性。
let obj = {
name: 'poetry',
age: undefined
};
let serializedObj = JSON.stringify(obj);
console.log(serializedObj); // {"name":"poetry"}
@前端进阶之旅: 代码已经复制到剪贴板
因此,在使用
JSON.stringify()进行深拷贝时,需要注意上述局限性,并确保对象不包含函数、循环引用或特殊对象,并且不需要保留undefined属性。对于包含上述情况的对象,应使用其他方法实现深拷贝。
82 防抖/节流
1. 防抖
防抖函数原理:把触发非常频繁的事件合并成一次去执行 在指定时间内只执行一次回调函数,如果在指定的时间内又触发了该事件,则回调函数的执行时间会基于此刻重新开始计算


防抖动和节流本质是不一样的。防抖动是将多次执行变为最后一次执行,节流是将多次执行变成每隔一段时间执行
eg. 像百度搜索,就应该用防抖,当我连续不断输入时,不会发送请求;当我一段时间内不输入了,才会发送一次请求;如果小于这段时间继续输入的话,时间会重新计算,也不会发送请求。
手写简化版:
// func是用户传入需要防抖的函数
// wait是等待时间
const debounce = (func, wait = 50) => {
// 缓存一个定时器id
let timer = 0
// 这里返回的函数是每次用户实际调用的防抖函数
// 如果已经设定过定时器了就清空上一次的定时器
// 开始一个新的定时器,延迟执行用户传入的方法
return function(...args) {
if (timer) clearTimeout(timer)
timer = setTimeout(() => {
func.apply(this, args)
}, wait)
}
}
@前端进阶之旅: 代码已经复制到剪贴板
适用场景:
- 文本输入的验证,连续输入文字后发送 AJAX 请求进行验证,验证一次就好
- 按钮提交场景:防止多次提交按钮,只执行最后提交的一次
- 服务端验证场景:表单验证需要服务端配合,只执行一段连续的输入事件的最后一次,还有搜索联想词功能类似
2. 节流
节流函数原理:指频繁触发事件时,只会在指定的时间段内执行事件回调,即触发事件间隔大于等于指定的时间才会执行回调函数。总结起来就是:事件,按照一段时间的间隔来进行触发。

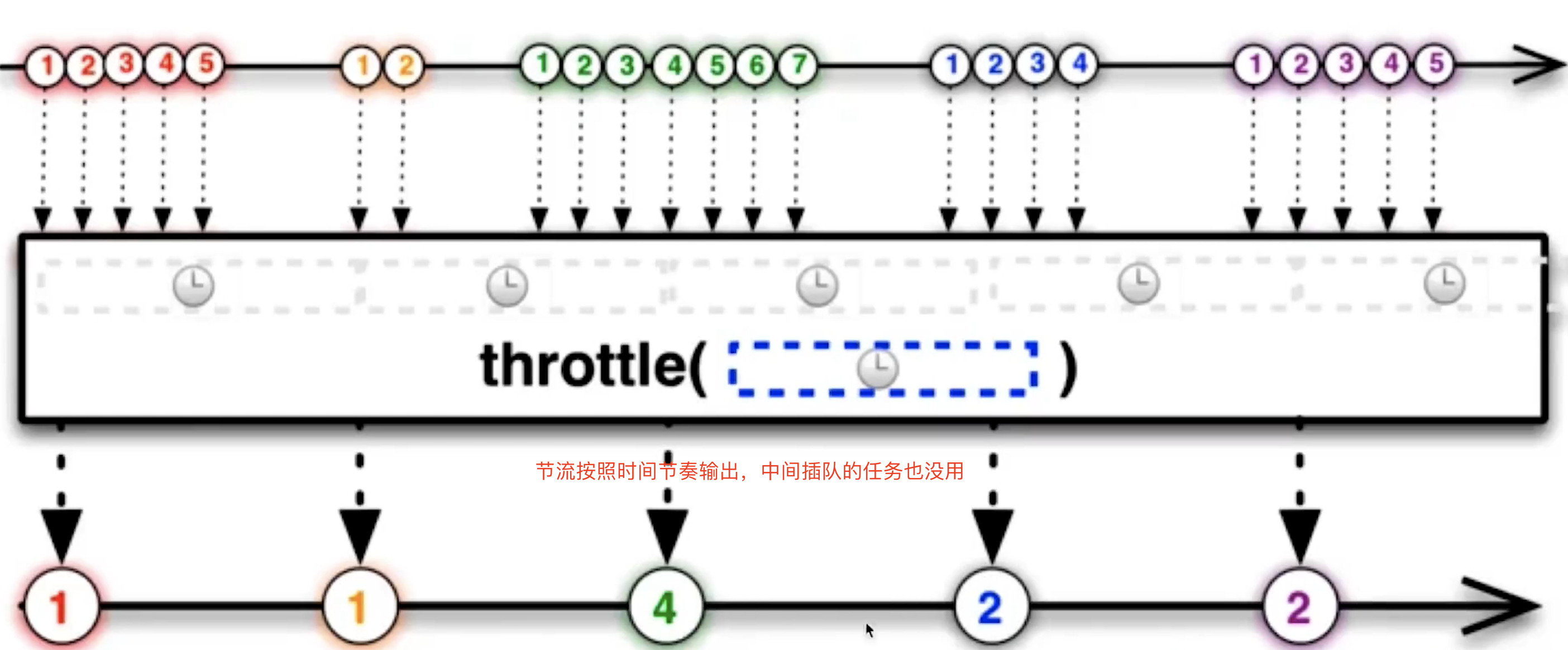
像dom的拖拽,如果用消抖的话,就会出现卡顿的感觉,因为只在停止的时候执行了一次,这个时候就应该用节流,在一定时间内多次执行,会流畅很多
手写简版
使用时间戳的节流函数会在第一次触发事件时立即执行,以后每过 wait 秒之后才执行一次,并且最后一次触发事件不会被执行
时间戳方式:
// func是用户传入需要防抖的函数
// wait是等待时间
const throttle = (func, wait = 50) => {
// 上一次执行该函数的时间
let lastTime = 0
return function(...args) {
// 当前时间
let now = +new Date()
// 将当前时间和上一次执行函数时间对比
// 如果差值大于设置的等待时间就执行函数
if (now - lastTime > wait) {
lastTime = now
func.apply(this, args)
}
}
}
setInterval(
throttle(() => {
console.log(1)
}, 500),
1
)
@前端进阶之旅: 代码已经复制到剪贴板
定时器方式:
使用定时器的节流函数在第一次触发时不会执行,而是在 delay 秒之后才执行,当最后一次停止触发后,还会再执行一次函数
function throttle(func, delay){
var timer = 0;
return function(){
var context = this;
var args = arguments;
if(timer) return // 当前有任务了,直接返回
timer = setTimeout(function(){
func.apply(context, args);
timer = 0;
},delay);
}
}
@前端进阶之旅: 代码已经复制到剪贴板
适用场景:
- 拖拽场景:固定时间内只执行一次,防止超高频次触发位置变动。
DOM元素的拖拽功能实现(mousemove) - 缩放场景:监控浏览器
resize - 滚动场景:监听滚动
scroll事件判断是否到页面底部自动加载更多 - 动画场景:避免短时间内多次触发动画引起性能问题
总结
- 函数防抖:
限制执行次数,多次密集的触发只执行一次- 将几次操作合并为一次操作进行。原理是维护一个计时器,规定在
delay时间后触发函数,但是在delay时间内再次触发的话,就会取消之前的计时器而重新设置。这样一来,只有最后一次操作能被触发。
- 将几次操作合并为一次操作进行。原理是维护一个计时器,规定在
- 函数节流:
限制执行的频率,按照一定的时间间隔有节奏的执行- 使得一定时间内只触发一次函数。原理是通过判断是否到达一定时间来触发函数。
83 谈谈变量提升?
- 变量提升是 JavaScript 中的一种行为,它指的是在代码执行过程中,变量和函数的声明会在其所在作用域的顶部被提升到执行环境中的过程。这意味着可以在变量或函数声明之前使用它们,而不会引发错误。
- 在 JavaScript 中,使用 var 声明变量时会发生变量提升。具体来说,变量声明会在代码执行前的编译阶段被解析并添加到执行环境中,但是变量的赋值操作会保留在原来的位置。这就导致了以下的行为:
当执行 JS 代码时,会生成执行环境,只要代码不是写在函数中的,就是在全局执行环境中,函数中的代码会产生函数执行环境,只此两种执行环境
1. 变量声明会被提升,但赋值操作不会被提升:
console.log(a); // undefined
var a = 10;
@前端进阶之旅: 代码已经复制到剪贴板
上述代码在执行时会被解析为:
var a;
console.log(a); // undefined
a = 10;
@前端进阶之旅: 代码已经复制到剪贴板
变量提升
这是因为函数和变量提升的原因。通常提升的解释是说将声明的代码移动到了顶部,这其实没有什么错误,便于大家理解。但是更准确的解释应该是:在生成执行环境时,会有两个阶段。第一个阶段是创建的阶段,JS 解释器会找出需要提升的变量和函数,并且给他们提前在内存中开辟好空间,函数的话会将整个函数存入内存中,变量只声明并且赋值为 undefined,所以在第二个阶段,也就是代码执行阶段,我们可以直接提前使用
2. 函数优先于变量提升
在提升的过程中,相同的函数会覆盖上一个函数,并且函数优先于变量提升
b() // call b second
function b() {
console.log('call b fist')
}
function b() {
console.log('call b second')
}
var b = 'Hello world'
@前端进阶之旅: 代码已经复制到剪贴板
var会产生很多错误,所以在ES6中引入了let。let不能在声明前使用,但是这并不是常说的let不会提升,let提升了,在第一阶段内存也已经为他开辟好了空间,但是因为这个声明的特性导致了并不能在声明前使用
总结
- 变量提升是 JavaScript 的一种行为,将变量和函数声明提升到作用域的顶部。
- 使用
var声明的变量会被提升,但赋值操作保留在原来的位置。 - 在提升的过程中,相同的函数会覆盖上一个函数,并且函数优先于变量提升
- 使用
let和const声明的变量也存在变量提升,但在声明前访问会引发暂时性死区错误。
84 什么是单线程,和异步的关系
在 JavaScript 中,单线程指的是 JavaScript 引擎在执行代码时只有一个主线程,也就是说一次只能执行一条指令。这意味着 JavaScript 代码是按照顺序执行的,前一段代码执行完成后才会执行下一段代码。
- 异步是一种编程模型,用于处理非阻塞的操作。在 JavaScript 中,异步编程可以通过回调函数、
Promise、async/await等方式来实现。异步操作不会阻塞主线程的执行,从而提高了程序的响应性能和用户体验。 - 异步的关系与单线程密切相关,因为 JavaScript 是单线程的,如果所有的操作都是同步的,那么一旦遇到一个耗时的操作,比如网络请求或文件读取,整个程序都会被阻塞,用户界面也会停止响应,导致用户体验差。
- 通过使用异步编程模型,可以将耗时的操作委托给其他线程或进程来处理,使得主线程可以继续执行其他任务,提高了程序的并发性和响应性。当异步操作完成后,通过回调函数或 Promise 的方式通知主线程,主线程再执行相应的回调逻辑。
总结一下:
JavaScript是单线程的,只有一个主线程用于执行代码。- 异步编程是一种处理非阻塞操作的方式,提高程序的响应性能和用户体验。
- 异步操作可以将耗时的任务委托给其他线程或进程处理,主线程继续执行其他任务。
- 异步操作完成后通过回调函数或
Promise的方式通知主线程。
85 前端面试之hybrid
Hybrid(混合应用)是指结合了原生应用和Web技术开发的应用程序。它通常在移动应用开发中使用,允许开发人员使用Web技术(如HTML、CSS和JavaScript)来构建跨平台的移动应用,并在原生应用中嵌入Web视图。
以下是我对Hybrid的理解:
- 跨平台开发:Hybrid应用具有跨平台的优势,通过使用Web技术开发一次,可以在多个平台上运行,如iOS和Android。这样可以节省开发时间和成本,并且能够更快地推出产品。
- 原生功能访问:Hybrid应用可以利用原生应用提供的功能和特性,如相机、地理定位、推送通知等。通过使用桥接技术,可以在Web视图中调用原生代码,实现对原生功能的访问和调用。
- Web技术栈:Hybrid应用使用Web技术栈进行开发,包括HTML、CSS和JavaScript。开发人员可以使用熟悉的Web开发工具和框架来构建应用程序,并且可以利用丰富的Web生态系统中的第三方库和工具。
- 在线更新:Hybrid应用可以通过Web进行在线更新,不需要用户手动更新应用程序。这使得开发人员能够快速修复错误、添加新功能,并将这些变更推送给用户,提供更好的用户体验。
- 性能权衡:与原生应用相比,Hybrid应用在性能方面可能存在一些权衡。由于在Web视图中运行,Hybrid应用的性能可能受到一些限制,特别是在处理复杂的图形和动画效果时。然而,随着Web技术的不断发展,这些性能限制正在逐渐减小。
总的来说,Hybrid应用是一种将Web技术与原生应用相结合的开发模式,提供了跨平台开发、访问原生功能、在线更新等优势。它在移动应用开发中具有一定的灵活性和便利性,可以满足开发人员快速开发和发布应用程序的需求。
以下是一个简单的示例代码,展示了如何使用Hybrid开发框架(例如Ionic)创建一个基本的Hybrid应用:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Hybrid App</title>
<!-- 引入Ionic框架 -->
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/ionic/3.9.2/css/ionic.min.css">
<script src="https://cdnjs.cloudflare.com/ajax/libs/ionic/3.9.2/js/ionic.bundle.min.js"></script>
</head>
<body>
<!-- Ionic提供的UI组件 -->
<ion-header>
<ion-navbar>
<ion-title>Hybrid App</ion-title>
</ion-navbar>
</ion-header>
<ion-content padding>
<h2>Welcome to Hybrid App!</h2>
<p>This is a hybrid application developed using Ionic framework.</p>
</ion-content>
<!-- 应用的脚本代码 -->
<script>
// 在Ionic的Angular控制器中编写业务逻辑
angular.module('starter', ['ionic'])
.controller('AppController', function($scope) {
$scope.message = "Hello, Hybrid App!";
});
// 启动Ionic应用
ionic.Platform.ready(function() {
angular.bootstrap(document, ['starter']);
});
</script>
</body>
</html>
@前端进阶之旅: 代码已经复制到剪贴板
上述示例中使用了Ionic框架,通过引入Ionic的CSS和JavaScript库,我们可以使用Ionic提供的UI组件和工具来构建Hybrid应用。在应用的脚本代码中,使用AngularJS来编写业务逻辑,控制器中定义了一个message变量,可以在视图中显示。最后,通过ionic.Platform.ready来启动Ionic应用。
请注意,这只是一个简单的示例,实际的Hybrid应用可能包含更多的功能和复杂性。不同的Hybrid开发框架可能有不同的用法和特性,具体的开发代码和结构会根据所选框架而有所不同。
86 前端面试之组件化
87 前端面试之MVVM浅析
88 实现效果,点击容器内的图标,图标边框变成border 1px solid red,点击空白处重置
const box = document.getElementById('box');
function isIcon(target) {
return target.className.includes('icon');
}
box.onClick = function(e) {
e.stopPropagation();
const target = e.target;
if (isIcon(target)) {
target.style.border = '1px solid red';
}
}
const doc = document;
doc.onclick = function(e) {
const children = box.children;
for(let i; i < children.length; i++) {
if (isIcon(children[i])) {
children[i].style.border = 'none';
}
}
}
@前端进阶之旅: 代码已经复制到剪贴板
89 请简单实现双向数据绑定MVVM
<input id="input"/>
<script>
const data = {};
const input = document.getElementById('input');
Object.defineProperty(data, 'text', {
get() {
return this.value;
},
set(value) {
input.value = value;
this.value = value;
}
});
input.addEventListener('change', function(e) {
data.text = e.target.value;
});
</script>
@前端进阶之旅: 代码已经复制到剪贴板
当你修改输入框的值时,
data.text会更新,而当你设置data.text的值时,输入框的值也会更新。这实现了简单的双向数据绑定。请注意,这只是一个基础示例,实际的MVVM框架会更复杂且功能更强大
90 实现Storage,使得该对象为单例,并对localStorage进行封装设置值setItem(key,value)和getItem(key)
var instance = null;
class Storage {
static getInstance() {
if (!instance) {
instance = new Storage();
}
return instance;
}
setItem(key, value) {
localStorage.setItem(key, value);
}
getItem(key) {
return localStorage.getItem(key);
}
}
@前端进阶之旅: 代码已经复制到剪贴板
现在,你可以使用Storage.getInstance()来获取Storage的单例对象,并使用setItem和getItem方法来设置和获取localStorage中的值。
// 使用示例
const storage = Storage.getInstance();
storage.setItem('name', 'poetry');
const name = storage.getItem('name');
console.log(name); // 输出: poetry
@前端进阶之旅: 代码已经复制到剪贴板
91 谈谈你对Event Loop的理解
前端面试中关于事件循环(Event Loop)的考点主要包括以下内容:
- 事件循环的基本原理:介绍 JavaScript 的单线程特性,事件循环的概念和工作原理,以及任务队列(Task Queue)的概念。
- 宏任务和微任务:区分宏任务(Macrotask)和微任务(Microtask)的概念,理解它们在事件循环中的执行顺序。
- 常见的宏任务和微任务:了解常见的宏任务和微任务的类型,如
setTimeout、setInterval、Promise、MutationObserver等。 - 异步操作的执行顺序:理解异步操作的执行顺序,如何在事件循环中处理异步代码,微任务优先于宏任务执行等。
- 宏任务中的异步操作:了解在宏任务中的异步操作(例如
setTimeout)是如何被添加到任务队列中的,以及它们的执行时机。 - 浏览器中的事件循环和 Node.js 中的事件循环:了解浏览器环境和 Node.js 环境下事件循环的差异,如
setImmediate的区别等。
了解和掌握事件循环的原理和机制对于理解 JavaScript 异步编程非常重要。在面试中,常常会通过让求职者解释事件循环的执行顺序、分析代码的输出结果等方式来考察他们对事件循环的理解。
首先,
js是单线程的,主要的任务是处理用户的交互,而用户的交互无非就是响应DOM的增删改,使用事件队列的形式,一次事件循环只处理一个事件响应,使得脚本执行相对连续,所以有了事件队列,用来储存待执行的事件,那么事件队列的事件从哪里被push进来的呢。那就是另外一个线程叫事件触发线程做的事情了,他的作用主要是在定时触发器线程、异步HTTP请求线程满足特定条件下的回调函数push到事件队列中,等待js引擎空闲的时候去执行,当然js引擎执行过程中有优先级之分,首先js引擎在一次事件循环中,会先执行js线程的主任务,然后会去查找是否有微任务microtask(promise),如果有那就优先执行微任务,如果没有,在去查找宏任务macrotask(setTimeout、setInterval)进行执行
众所周知
JS是门非阻塞单线程语言,因为在最初JS就是为了和浏览器交互而诞生的。如果JS是门多线程的语言话,我们在多个线程中处理DOM就可能会发生问题(一个线程中新加节点,另一个线程中删除节点)
JS在执行的过程中会产生执行环境,这些执行环境会被顺序的加入到执行栈中。如果遇到异步的代码,会被挂起并加入到Task(有多种task) 队列中。一旦执行栈为空,EventLoop就会从Task队列中拿出需要执行的代码并放入执行栈中执行,所以本质上来说JS中的异步还是同步行为

console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
console.log('script end');
@前端进阶之旅: 代码已经复制到剪贴板
不同的任务源会被分配到不同的
Task队列中,任务源可以分为 微任务(microtask) 和 宏任务(macrotask)。在ES6规范中,microtask称为jobs,macrotask称为task
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
new Promise((resolve) => {
console.log('Promise')
resolve()
}).then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
// script start => Promise => script end => promise1 => promise2 => setTimeout
@前端进阶之旅: 代码已经复制到剪贴板
以上代码虽然
setTimeout写在Promise之前,但是因为Promise属于微任务而setTimeout属于宏任务
微任务
process.nextTickpromiseObject.observeMutationObserver
宏任务
scriptsetTimeoutsetIntervalsetImmediateI/OUI rendering
宏任务中包括了
script,浏览器会先执行一个宏任务,接下来有异步代码的话就先执行微任务
所以正确的一次 Event loop 顺序是这样的
- 执行同步代码,这属于宏任务
- 执行栈为空,查询是否有微任务需要执行
- 执行所有微任务
- 必要的话渲染 UI
- 然后开始下一轮
Event loop,执行宏任务中的异步代码
通过上述的
Event loop顺序可知,如果宏任务中的异步代码有大量的计算并且需要操作DOM的话,为了更快的响应界面响应,我们可以把操作DOM放入微任务中
setTimeout(function () {
console.log("1");
}, 0);
async function async1() {
console.log("2");
const data = await async2();
console.log("3");
return data;
}
async function async2() {
return new Promise((resolve) => {
console.log("4");
resolve("async2的结果");
}).then((data) => {
console.log("5");
return data;
});
}
async1().then((data) => {
console.log("6");
console.log(data);
});
new Promise(function (resolve) {
console.log("7");
// resolve()
}).then(function () {
console.log("8");
});
@前端进阶之旅: 代码已经复制到剪贴板
输出结果:
247536async2的结果1
92 JavaScript 对象生命周期的理解
JavaScript 对象的生命周期可以概括为以下几个阶段:
- 创建阶段:当使用
new关键字或对象字面量语法创建一个对象时,JavaScript 引擎会为该对象分配内存,并将其初始化为一个空对象。 - 使用阶段:在对象创建后,可以对其进行属性的读取、修改和方法的调用等操作。对象被使用时,它可能会被传递给其他函数或存储在变量中,以供后续操作使用。
- 引用阶段:在对象的使用过程中,其他变量或函数可能会引用该对象,形成对该对象的引用关系。这些引用关系可以是直接的,也可以是通过其他对象的属性或方法间接引用的。
- 回收阶段:当一个对象不再被引用时,或者所有引用都被循环引用时,垃圾回收机制会将其标记为可回收,并在适当的时候回收该对象所占用的内存。垃圾回收器定期扫描内存中的对象,检查它们的引用情况,并释放那些不再被引用的对象。
需要注意的是,JavaScript 使用自动垃圾回收机制来管理内存,开发者不需要显式地释放对象占用的内存。垃圾回收器会自动跟踪对象的引用关系,并在适当的时候回收无用的对象。开发者可以通过将对象的引用置为 null 来显式地解除对对象的引用,以帮助垃圾回收器更早地回收对象。
在浏览器环境中,垃圾回收器通常使用标记-清除算法来判断对象是否可回收。当一个对象不再可达时,即没有任何引用指向该对象,垃圾回收器会将其标记为可回收,并在垃圾回收的过程中将其释放。一些现代的浏览器还使用了更高级的垃圾回收算法,如分代回收和增量标记等,以提高垃圾回收的效率和性能。
总结来说,JavaScript 对象的生命周期包括创建、使用和回收三个阶段。开发者无需显式地管理对象的内存,而是通过使用对象和及时解除对象的引用来帮助垃圾回收器自动回收不再使用的对象。
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
99 说几条写JavaScript的基本规范
以下是一些常见的JavaScript编码规范:
- 使用一致的缩进:推荐使用四个空格进行缩进,而不是制表符。
- 使用一致的代码风格:在代码中使用一致的花括号(大括号)风格,可以是"K&R"风格(花括号放在行尾)或"Allman"风格(花括号独占一行)。
- 使用分号结束语句:在每条语句的末尾使用分号结束,这有助于避免意外的错误。
- 声明变量和函数:在使用之前,先声明变量和函数,避免隐式的全局变量。
- 命名约定:使用有意义且符合约定的变量和函数命名,采用驼峰命名法,首字母小写,构造函数使用大写字母开头,常量全大写。
- 使用严格模式:在脚本或函数的开头使用严格模式(‘use strict’),可以帮助捕获潜在的错误并使代码更加安全。
- 编写清晰的注释:使用注释来解释代码的用途、思路或重要细节,有助于他人理解代码。
- 格式化对象和数组:使用花括号
{}来声明对象,使用方括号[]来声明数组,并且按照一定的格式排列其中的元素,提高可读性。 - 使用单引号或双引号:可以选择使用单引号或双引号来表示字符串,但要保持一致性。
- 避免使用全局变量:尽量避免使用全局变量,使用模块化的方式组织代码,减少命名冲突和意外的副作用。
这些规范有助于提高代码的可读性、可维护性和一致性,使团队协作更加顺畅,并降低代码出错的风险。在编写JavaScript代码时,遵循一致的编码规范是一个良好的实践。
100 如何编写高性能的JavaScript
以下是一些编写高性能JavaScript的技巧:
- 使用严格模式:在JavaScript代码中使用严格模式,可以帮助检测潜在的错误,并提高代码性能。
- 将脚本放在底部:将JavaScript脚本放在HTML页面的底部,这样可以避免阻塞页面的渲染,提高页面加载速度。
- 打包和压缩代码:将JavaScript脚本进行打包和压缩,减少网络请求和文件大小,提高加载速度。
- 非阻塞下载:使用异步加载的方式下载JavaScript脚本,通过将脚本放在
<script>标签的async或defer属性中,避免阻塞页面的渲染。 - 减少全局变量的使用:尽量避免过多使用全局变量,使用局部变量来保存数据,减少作用域链的查找时间。
- 优化循环和迭代:在循环和迭代过程中,尽量减少重复的计算和操作,将需要重复使用的值存储在局部变量中,避免重复访问对象成员。
- 缓存DOM访问:在访问DOM节点时,尽量将访问结果缓存起来,避免重复查询DOM树,提高代码执行效率。
- 避免使用eval()和Function()构造器:这些方法会动态编译和执行代码,对性能有一定的影响,尽量避免使用它们。
- 使用直接量创建对象和数组:在创建对象和数组时,尽量使用直接量的方式,避免使用构造函数,这样可以减少额外的函数调用和内存分配。
- 最小化重绘和回流:重绘(repaint)和回流(reflow)是页面渲染的过程,它们会消耗大量的计算资源,尽量避免频繁的重绘和回流,可以通过合并操作、使用CSS动画等方式来优化。 当涉及到编写高性能的JavaScript代码时,还有一些其他的技巧可以考虑:
- 减少对象成员嵌套:在访问对象的成员时,尽量减少多层嵌套,这样可以提高访问速度。例如,将
obj1.obj2.prop改为obj1Prop。 - 避免频繁的字符串操作:字符串操作比较耗费性能,尤其是在循环中频繁拼接字符串。可以使用数组或模板字符串来优化字符串操作。
- 使用事件委托:对于需要监听多个子元素事件的情况,可以将事件监听器添加到它们的父元素上,通过事件冒泡机制来处理事件。这样可以减少事件监听器的数量,提高性能。
- 避免频繁的重绘:如果需要对DOM进行多次修改,最好将这些修改操作放在一起,而不是分散在多个地方,这样可以减少重绘次数。
- 使用局部作用域:将代码封装在函数或模块中,利用局部作用域来限制变量的作用范围,避免命名冲突和全局变量污染。
- 使用合适的数据结构和算法:在处理大量数据或复杂逻辑时,选择合适的数据结构和算法可以提高代码的效率。了解不同数据结构和算法的特点,选择最佳的方案。
- 节流和防抖:对于一些频繁触发的事件(如滚动、调整窗口大小等),可以使用节流和防抖的技术来限制事件的触发频率,减少不必要的计算和操作。
- 使用性能分析工具:利用浏览器提供的性能分析工具(如Chrome的开发者工具)来检测和分析代码的性能瓶颈,找到需要优化的地方。
- 避免使用过时的方法和特性:某些方法和特性可能已经过时或存在性能问题,尽量避免使用它们,使用最新的标准和API来编写代码。
- 定期进行代码优化和重构:不断优化和重构代码,去除冗余和低效的部分,使代码保持简洁、高效和易于维护。
综合使用这些技巧,可以显著提高JavaScript代码的性能和执行效率。但需要注意的是,优化代码时应该根据具体情况进行评估和测试,避免过度优化导致代码可读性和可维护性的降低。
101 描述浏览器的渲染过程,DOM树和渲染树的区别
浏览器的渲染过程:
- 解析 HTML 构建 DOM(文档对象模型)树:浏览器将接收到的 HTML 文档解析成一个树状结构,该结构被称为 DOM 树。DOM 树表示了 HTML 文档的结构和内容。
- 解析 CSS 构建 CSSOM(CSS 对象模型)树:浏览器将接收到的 CSS 文件解析成一个树状结构,该结构被称为 CSSOM 树。CSSOM 树表示了 CSS 样式规则的层级和规则。
- 合并 DOM 树和 CSSOM 树生成渲染树(Render Tree):浏览器将 DOM 树和 CSSOM 树合并,生成一个渲染树(Render Tree)。渲染树只包含需要显示在页面上的节点,隐藏的节点(如 head)和不可见的节点(如 display: none)不包含在渲染树中。
- 布局(Layout):渲染树中的每个节点都有对应的布局信息,浏览器根据这些布局信息计算节点在屏幕中的位置和大小,这个过程称为布局或回流(reflow)。
- 绘制(Painting):浏览器根据渲染树的布局信息和样式信息,将节点绘制到屏幕上,这个过程称为绘制或重绘(repaint)。
DOM 树和渲染树的区别:
- DOM 树(文档对象模型树)是由 HTML 文档解析而来,它反映了文档的结构和内容,包括 HTML 标签、文本节点和注释等。DOM 树中的每个节点都有其对应的 CSS 样式规则。
- 渲染树(Render Tree)是由 DOM 树和 CSSOM 树合并而成,它是用于显示在浏览器中的树状结构。渲染树只包含需要显示在页面上的节点,不包含隐藏的节点和不可见的节点。渲染树中的每个节点都有其对应的布局信息和样式信息,用于计算节点在屏幕中的位置和大小,并将节点绘制到屏幕上。
总结:DOM 树表示了 HTML 文档的结构和内容,而渲染树是为了将文档在浏览器中显示而构建的树结构。渲染树只包含需要显示的节点,并且每个节点都有对应的布局和样式信息,用于计算和绘制节点在屏幕上的位置和外观。
102 script 的位置是否会影响首屏显示时间
script的位置对首屏显示时间有影响。虽然浏览器在解析 HTML 生成 DOM 过程中,js文件的下载是并行的,不需要 DOM 处理到script节点,但是脚本的执行会阻塞页面的解析和渲染。- 当浏览器遇到
script标签时,会暂停解析 HTML,开始下载并执行脚本。只有脚本执行完毕后,浏览器才会继续解析和渲染页面。 - 如果
script标签放在<head>标签中,那么脚本的下载和执行会先于页面的渲染,这样会延迟首屏显示的开始时间。 - 为了提高首屏显示时间,一般建议将
script标签放在<body>标签底部,在大部分内容都已经显示出来后再加载和执行脚本,这样可以让页面尽快呈现给用户,提升用户体验。 - 另外,可以使用异步加载的方式(如将
script标签添加async属性)或延迟加载的方式(如将script标签添加defer属性),来减少脚本对页面加载的阻塞影响。这样可以在不阻塞页面渲染的情况下加载和执行脚本,加快首屏显示的完成时间。
103 介绍 DOM 的发展
DOM:文档对象模型(Document Object Model),定义了访问HTML和XML文档的标准,与编程语言及平台无关DOM Level 0:提供了查询和操作Web文档的内容API。未形成标准,实现混乱。如:document.forms['login']DOM Level 1:W3C提出标准化的DOM,简化了对文档中任意部分的访问和操作。如:JavaScript中的Document对象DOM Level 2:原来DOM基础上扩充了鼠标事件等细分模块,增加了对CSS的支持。如:getComputedStyle(elem, pseudo)DOM Level 3:增加了XPath模块和加载与保存(Load and Save)模块。如:XPathEvaluatorDOM Level 4:继续扩展了 DOM 标准,引入了一些新的接口和功能,如MutationObserver用于监听 DOM 变动、Shadow DOM用于创建独立的 DOM 子树等
104 介绍DOM0,DOM2,DOM3事件处理方式区别
- DOM0级事件处理方式:通过直接给事件属性赋值的方式进行事件处理,例如
element.onclick = func;。这种方式只能为同一个事件属性赋一个处理函数,且无法进行事件捕获阶段的处理。取消事件处理需要将事件属性赋值为nullbtn.onclick = func;btn.onclick = null;
- DOM2级事件处理方式:引入了
addEventListener和removeEventListener方法来注册和移除事件处理函数。通过使用该方式,可以为同一个事件属性添加多个处理函数,且可以在事件的捕获阶段或冒泡阶段进行处理。使用addEventListener注册事件处理函数,使用removeEventListener移除事件处理函数btn.addEventListener('click', func, false);btn.removeEventListener('click', func, false);btn.attachEvent("onclick", func);btn.detachEvent("onclick", func);
- DOM3级事件处理方式:引入了新的事件类型和接口,提供更多的事件处理选项。可以使用自定义的事件类型,并通过
eventUtil等自定义的工具对象来添加和移除事件处理函数。DOM3级事件处理方式还引入了事件的命名空间概念,允许对特定命名空间的事件进行处理eventUtil.addListener(input, "textInput", func);eventUtil是自定义对象,textInput是DOM3级事件
在事件处理过程中,事件会经历捕获阶段、目标阶段和冒泡阶段。捕获阶段从文档根节点开始,向下传递到触发事件的目标元素,然后进入目标阶段,最后冒泡阶段从目标元素向上冒泡到文档根节点。DOM2和DOM3级事件处理方式都支持捕获和冒泡阶段的处理,可以通过第三个参数 useCapture 来控制事件是在捕获阶段还是冒泡阶段触发。
需要注意的是,DOM2和DOM3级事件处理方式的兼容性较好,而DOM0级事件处理方式在现代的开发中很少使用,推荐使用DOM2级或DOM3级事件处理方式。
105 区分什么是“客户区坐标”、“页面坐标”、“屏幕坐标”
- 客户区坐标:鼠标指针在可视区中的水平坐标(
clientX)和垂直坐标(clientY) - 页面坐标:鼠标指针在页面布局中的水平坐标(
pageX)和垂直坐标(pageY) - 屏幕坐标:设备物理屏幕的水平坐标(
screenX)和垂直坐标(screenY)
<!DOCTYPE html>
<html>
<head>
<style>
body {
margin: 0;
height: 2000px;
}
#box {
width: 200px;
height: 200px;
background-color: red;
position: absolute;
left: 100px;
top: 100px;
}
</style>
</head>
<body>
<div id="box"></div>
<script>
document.addEventListener('mousemove', function(event) {
console.log('客户区坐标:', event.clientX, event.clientY);
console.log('页面坐标:', event.pageX, event.pageY);
console.log('屏幕坐标:', event.screenX, event.screenY);
});
</script>
</body>
</html>
@前端进阶之旅: 代码已经复制到剪贴板
如何获得一个DOM元素的绝对位置?
elem.offsetLeft:返回元素相对于其定位父级左侧的距离elem.offsetTop:返回元素相对于其定位父级顶部的距离elem.getBoundingClientRect():返回一个DOMRect对象,包含一组描述边框的只读属性,单位像素
<!DOCTYPE html>
<html>
<head>
<style>
body {
margin: 0;
padding: 0;
}
#container {
width: 500px;
height: 500px;
position: relative;
border: 1px solid black;
}
#box {
width: 100px;
height: 100px;
background-color: red;
position: absolute;
left: 200px;
top: 200px;
}
</style>
</head>
<body>
<div id="container">
<div id="box"></div>
</div>
<script>
var box = document.getElementById('box');
var offsetLeft = box.offsetLeft;
var offsetTop = box.offsetTop;
console.log('offsetLeft:', offsetLeft);
console.log('offsetTop:', offsetTop);
var rect = box.getBoundingClientRect();
console.log('rect:', rect);
console.log('left:', rect.left);
console.log('top:', rect.top);
</script>
</body>
</html>
@前端进阶之旅: 代码已经复制到剪贴板
106 Javascript垃圾回收方法
正常情况下,现代的 JavaScript 引擎会使用标记清除(mark and sweep)算法作为主要的垃圾回收方法。引用计数(reference counting)在某些老旧的 JavaScript 引擎中可能会被使用。
标记清除(mark and sweep)是 JavaScript 中最常见的垃圾回收算法,其工作原理如下:
- 垃圾回收器会在运行时给存储在内存中的所有变量加上标记。
- 垃圾回收器会从根对象开始,递归遍历所有的引用,标记它们为“进入环境”。
- 在遍历完成后,垃圾回收器会对未被标记的变量进行清除,即将其回收内存空间。
- 被清除的内存空间将被重新分配给后续的变量使用。
function foo() {
var x = { name: 'poetry' };
var y = { name: 'Jane' };
// 循环引用,x 引用了 y,y 引用了 x
x.ref = y;
y.ref = x;
// x 和 y 不再被使用,将被标记为垃圾
x = null;
y = null;
// 垃圾回收器在适当的时机会清理循环引用的对象
}
// 调用函数触发垃圾回收
foo();
@前端进阶之旅: 代码已经复制到剪贴板
引用计数(reference counting)是一种简单的垃圾回收算法,其工作原理如下:
- 对于每个对象,引擎会维护一个引用计数器,用于记录当前有多少个引用指向该对象。
- 当一个引用指向对象时,引用计数器加一;当一个引用不再指向对象时,引用计数器减一。
- 当引用计数器为零时,说明该对象没有被引用,可以将其回收内存空间。
- 引用计数算法容易出现循环引用的问题,即两个或多个对象互相引用,但没有被其他对象引用,导致引用计数器无法归零,造成内存泄漏。
值得注意的是,现代的 JavaScript 引擎往往会采用更高级的垃圾回收算法,如基于分代的垃圾回收和增量标记等,以提高垃圾回收的效率和性能。以上所述的标记清除和引用计数仅是简单的介绍,实际的垃圾回收算法比较复杂,并涉及到更多的优化和细节。
// 引用计数无法处理循环引用问题,这里只作演示
function foo() {
var x = { name: 'poetry' };
var y = { name: 'Jane' };
// x 和 y 引用计数均为 1
var refCountX = 1;
var refCountY = 1;
// 循环引用,x 引用了 y,y 引用了 x
x.ref = y;
y.ref = x;
// x 和 y 不再被使用,引用计数减一
refCountX--;
refCountY--;
// 当引用计数为零时,垃圾回收器可以清理对象
if (refCountX === 0) {
// 清理 x 对象的内存
x = null;
}
if (refCountY === 0) {
// 清理 y 对象的内存
y = null;
}
}
// 调用函数触发垃圾回收
foo();
@前端进阶之旅: 代码已经复制到剪贴板
请注意,上述示例中的引用计数示例仅为演示目的,并未解决循环引用导致的内存泄漏问题。在实际开发中,为了避免内存泄漏,需要使用更高级的垃圾回收算法和技术,或者手动解除循环引用。
107 请解释一下 JavaScript 的同源策略
同源策略(Same-Origin Policy)是浏览器中一种重要的安全机制,用于限制来自不同源(
协议、域名、端口)的脚本对当前文档的访问权限。同源策略的作用是保护用户的信息安全,防止恶意网站获取敏感数据或进行跨站攻击。
同源策略限制了以下行为:
- 脚本访问跨源文档的 DOM:通过脚本在页面中嵌入的 iframe 元素加载的跨源文档无法通过脚本访问其 DOM,除非目标文档明确允许。
- 脚本读取跨源文档的内容:通过脚本在页面中嵌入的 iframe 元素加载的跨源文档无法通过脚本读取其内容,包括读取属性、执行方法等。
- 脚本发送跨源 AJAX 请求:脚本无法直接发送跨源的 AJAX 请求,只能向同源的服务器发送请求。
Cookie、LocalStorage和IndexDB的限制:跨源的脚本无法访问其他源的Cookie、LocalStorage或IndexDB数据。
同源策略的存在使得浏览器可以更好地保护用户的隐私和安全。然而,也有一些场景需要进行跨域访问,例如使用 JSONP、CORS、代理服务器等方式来实现跨域请求。
需要注意的是,同源策略仅在浏览器中执行,不会限制服务器之间的通信,服务器可以自由地进行跨域访问。
108 如何删除一个cookie
删除一个 Cookie 可以通过以下几种方式实现:
1. 将 Cookie 的过期时间设置为过去的时间:
var date = new Date();
date.setDate(date.getDate() - 1);
document.cookie = "cookieName=; expires=" + date.toUTCString();
@前端进阶之旅: 代码已经复制到剪贴板
将 cookieName 替换为要删除的 Cookie 的名称。
2. 使用 expires 参数设置过期时间:
document.cookie = "cookieName=; expires=Thu, 01 Jan 1970 00:00:00 UTC";
@前端进阶之旅: 代码已经复制到剪贴板
同样,将 cookieName 替换为要删除的 Cookie 的名称。
3. 使用 max-age 参数设置过期时间:
document.cookie = "cookieName=; max-age=0";
@前端进阶之旅: 代码已经复制到剪贴板
同样,将 cookieName 替换为要删除的 Cookie 的名称。
请注意,删除 Cookie 时需要确保 path 和 domain 参数与要删除的 Cookie 的设置一致,以确保正确删除指定的 Cookie
109 页面编码和被请求的资源编码如果不一致如何处理
如果页面编码和被请求的资源编码不一致,可以采取以下处理方式:
- 后端响应头设置
charset:在服务器端返回资源(例如 HTML 页面、CSS 文件、JavaScript 文件)时,在响应头中设置正确的字符编码,确保与页面编码一致。例如,在 HTTP 头部中添加以下内容:
Content-Type: text/html; charset=utf-8
@前端进阶之旅: 代码已经复制到剪贴板
这样可以告诉浏览器使用 UTF-8 编码解析返回的资源。
- 前端页面
<meta>设置charset:在 HTML 页面的<head>部分添加<meta>标签,并设置正确的字符编码,确保与被请求的资源编码一致。例如:
<meta charset="utf-8">
@前端进阶之旅: 代码已经复制到剪贴板
这样可以告诉浏览器使用 UTF-8 编码解析当前页面。
通过上述方式设置正确的字符编码,可以确保页面和被请求的资源在解析和显示时使用一致的编码,避免乱码等问题。需要注意的是,确保页面和资源的编码设置一致,并且字符编码在各个环节中正确传递和解析。
110 把<script>放在</body>之前和之后有什么区别?浏览器会如何解析它们?
将<script>放在</body>之前和之后的区别主要是在符合HTML标准的语法规则和浏览器的容错机制上,具体如下:
- 符合HTML标:按照HTML标准规定,
<script>标签应该放在<body>标签内,通常是放在</body>之前。将<script>放在</body>之后是不符合HTML标准的,属于语法错误。但是,现代浏览器通常会自动容错并解析这样的语法,不会出现明显的错误。 - 浏览器解析:浏览器会解析并执行
<script>标签中的JavaScript代码。无论<script>放在</body>之前还是之后,浏览器都会执行其中的代码。浏览器的容错机制会忽略<script>之前的</body>,视作<script>仍然在<body>内部。因此,从功能和效果上来说,两者没有区别。 - 服务器输出优化:在一些情况下,省略
</body>和</html>闭合标签可以减少服务器输出的内容,因为浏览器会自动补全这些标签。对于大型网站或需要优化响应速度的场景,这种优化可以略微减少传输的字节数。
需要注意的是,虽然现代浏览器对放置<script>标签的位置比较宽容,但为了遵循HTML标准和保持代码的可读性和可维护性,推荐将<script>标签放在</body>之前,符合语义和结构的要求。
111 JavaScript 中,调用函数有哪几种方式
在JavaScript中,调用函数有以下几种方式:
- 方法调用模式:将函数作为对象的方法调用,使用点运算符来调用函数。
obj.method(arg1, arg2);
@前端进阶之旅: 代码已经复制到剪贴板
- 函数调用模式:直接调用函数,没有明确的接收者对象。
func(arg1, arg2);
@前端进阶之旅: 代码已经复制到剪贴板
- 构造器调用模式:使用
new关键字调用函数作为构造器来创建对象实例。
new Func(arg1, arg2);
@前端进阶之旅: 代码已经复制到剪贴板
call/apply调用模式:使用call或apply方法来调用函数,并指定函数内部的this值,以及参数列表。
func.call(obj, arg1, arg2);
func.apply(obj, [arg1, arg2]);
@前端进阶之旅: 代码已经复制到剪贴板
bind调用模式:使用bind方法创建一个新函数,并指定新函数的this值,然后调用新函数。
var newFunc = func.bind(obj);
newFunc(arg1, arg2);
@前端进阶之旅: 代码已经复制到剪贴板
这些不同的调用方式提供了灵活性和适用性,可以根据不同的场景选择合适的方式来调用函数。
112 列举一下JavaScript数组和对象有哪些原生方法?
数组方法:
arr.concat(arr1, arr2, arrn):连接多个数组并返回新数组。arr.copyWithin(target, start, end):将数组的一部分复制到同一数组中的另一个位置。arr.entries():返回一个包含数组键值对的迭代器对象。arr.every(callbackFn, thisArg):测试数组中的所有元素是否都通过了指定函数的测试。arr.fill(value, start, end):用静态值填充数组的一部分。arr.filter(callbackFn, thisArg):创建一个新数组,其中包含通过指定函数筛选的所有元素。arr.find(callbackFn, thisArg):返回数组中第一个满足测试函数的元素的值。arr.findIndex(callbackFn, thisArg):返回数组中第一个满足测试函数的元素的索引。arr.flat(depth):将多维数组展平为一维数组。arr.flatMap(callbackFn, thisArg):首先使用映射函数映射每个元素,然后将结果展平为一维数组。arr.forEach(callbackFn, thisArg):对数组中的每个元素执行指定函数。arr.includes(searchElement, fromIndex):判断数组中是否包含指定元素。arr.indexOf(searchElement, fromIndex):返回指定元素在数组中首次出现的索引。arr.join(separator):将数组元素连接为一个字符串,并使用指定的分隔符。arr.keys():返回一个包含数组键的迭代器对象。arr.lastIndexOf(searchElement, fromIndex):返回指定元素在数组中最后一次出现的索引。arr.map(callbackFn, thisArg):创建一个新数组,其中包含通过指定函数对每个元素进行处理后的结果。arr.pop():移除并返回数组的最后一个元素。arr.push(element1, element2, ..., elementN):向数组末尾添加一个或多个元素,并返回新的长度。arr.reduce(callbackFn, initialValue):对数组中的所有元素执行指定的累积函数,返回累积结果。arr.reduceRight(callbackFn, initialValue):对数组中的所有元素执行指定的累积函数(从右到左),返回累积结果。arr.reverse():反转数组中元素的顺序。arr.shift():移除并返回数组的第一个元素。arr.slice(start, end):从数组中提取指定范围的元素,并返回一个新数组。arr.some(callbackFn, thisArg):测试数组中的至少一个元素是否通过了指定函数的测试。arr.sort(compareFunction):对数组元素进行排序,可以传入自定义的比较函数。arr.splice(start, deleteCount, item1, item2, ...):从数组中添加/删除元素,并返回被删除的元素。arr.toLocaleString():将数组中的元素转换为字符串,并返回该字符串。arr.toString():将数组中的元素转换为字符串,并返回该字符串。arr.unshift(element1, element2, ..., elementN):向数组开头添加一个或多个元素,并返回新的长度。arr.values():返回一个包含数组值的迭代器对象。
对象方法:
Object.assign(target, ...sources):将一个或多个源对象的属性复制到目标对象,并返回目标对象。Object.create(proto, [propertiesObject]):使用指定的原型对象和属性创建一个新对象。Object.defineProperties(obj, props):定义一个或多个对象的新属性或修改现有属性的配置。Object.defineProperty(obj, prop, descriptor):定义一个新属性或修改现有属性的配置。Object.entries(obj):返回一个包含对象自身可枚举属性的键值对数组。Object.freeze(obj):冻结对象,使其属性不可修改。Object.fromEntries(entries):将键值对列表转换为对象。Object.getOwnPropertyDescriptor(obj, prop):返回对象属性的描述符。Object.getOwnPropertyDescriptors(obj):返回对象所有属性的描述符。Object.getOwnPropertyNames(obj):返回一个数组,包含对象自身的所有属性名称。Object.getOwnPropertySymbols(obj):返回一个数组,包含对象自身的所有Symbol属性。Object.getPrototypeOf(obj):返回指定对象的原型。Object.is(value1, value2):判断两个值是否相同。Object.isExtensible(obj):判断对象是否可扩展。Object.isFrozen(obj):判断对象是否已被冻结。Object.isSealed(obj):判断对象是否已被密封。Object.keys(obj):返回一个数组,包含对象自身的所有可枚举属性名称。Object.preventExtensions(obj):阻止对象扩展,使其不可添加新属性。Object.seal(obj):将对象密封,使其属性不可添加、删除或配置。Object.setPrototypeOf(obj, prototype):设置对象的原型。Object.values(obj):返回一个包含对象自身可枚举属性的值的数组。
这些方法可以帮助我们在JavaScript中更方便地操作和处理数组和对象的数据。
113 Array.slice() 与 Array.splice() 的区别?
slice()方法返回一个新数组,包含从原数组中指定的开始位置到结束位置(不包括结束位置)的元素,不会修改原数组。splice()方法通过删除或替换现有元素或者添加新元素来修改原数组。它会返回被删除的元素组成的数组。
const fruits = ['apple', 'banana', 'orange', 'mango', 'kiwi'];
// 从索引 1 开始删除 2 个元素,并插入 'grape' 和 'pear'
const deletedFruits = fruits.splice(1, 2, 'grape', 'pear');
console.log(deletedFruits); // 输出: ['banana', 'orange']
console.log(fruits); // 输出: ['apple', 'grape', 'pear', 'mango', 'kiwi']
@前端进阶之旅: 代码已经复制到剪贴板
const fruits = ['apple', 'banana', 'orange'];
// 在索引 1 的位置插入 'grape' 和 'kiwi'
fruits.splice(1, 0, 'grape', 'kiwi');
console.log(fruits); // 输出: ['apple', 'grape', 'kiwi', 'banana', 'orange']
@前端进阶之旅: 代码已经复制到剪贴板
主要区别如下:
slice()是纯粹的读取操作,不会对原数组进行修改,而splice()是对数组进行操作,会修改原数组。slice()的参数是起始位置和结束位置,返回选定的元素组成的新数组。splice()的参数是起始位置、删除的元素个数以及可选的插入元素,返回被删除的元素组成的新数组。slice()的结束位置是不包括在选取范围内的,而splice()中的删除元素个数是包括在操作范围内的。slice()不会改变原数组的长度,而splice()可以改变原数组的长度。
总的来说,slice() 是用来提取数组中的一部分元素,不改变原数组,而 splice() 是用来操作数组,可以删除、替换或插入元素,会改变原数组。
const fruits = ['apple', 'banana', 'orange', 'mango', 'kiwi'];
// 从索引 1 开始(包括索引 1),到索引 3 结束(不包括索引 3)
const slicedFruits = fruits.slice(1, 3);
console.log(slicedFruits); // 输出: ['banana', 'orange']
console.log(fruits); // 输出: ['apple', 'banana', 'orange', 'mango', 'kiwi']
@前端进阶之旅: 代码已经复制到剪贴板
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
122 常用设计模式有哪些并举例使用场景
- 工厂模式:
- 使用场景:当需要根据不同的参数创建不同类型的对象时,可以使用工厂模式。例如,根据用户的选择创建不同类型的支付方式对象。
- 优点:封装了对象的创建过程,客户端只需关注传入参数即可获取所需对象,降低了耦合度。
- 缺点:增加了代码的复杂性,需要额外编写工厂方法。
class PaymentFactory {
createPayment(type) {
switch (type) {
case 'credit':
return new CreditPayment();
case 'debit':
return new DebitPayment();
default:
throw new Error('Invalid payment type');
}
}
}
const paymentFactory = new PaymentFactory();
const creditPayment = paymentFactory.createPayment('credit');
const debitPayment = paymentFactory.createPayment('debit');
@前端进阶之旅: 代码已经复制到剪贴板
- 单例模式:
- 使用场景:当整个系统中只需要一个实例时,可以使用单例模式。例如,全局的系统配置对象。
- 优点:确保只有一个实例存在,提供了全局访问点,避免了重复创建实例。
- 缺点:对扩展不友好,单例的实例化和使用耦合在一起。
class SystemConfig {
constructor() {
// Initialize system configuration
}
static getInstance() {
if (!SystemConfig.instance) {
SystemConfig.instance = new SystemConfig();
}
return SystemConfig.instance;
}
}
const config = SystemConfig.getInstance();
@前端进阶之旅: 代码已经复制到剪贴板
- 发布-订阅模式:
- 使用场景:当存在多个对象之间需要进行解耦的消息通信时,可以使用发布-订阅模式。例如,实现一个事件总线用于组件间的通信。
- 优点:解耦了对象之间的通信,订阅者只需关注自己感兴趣的事件,发布者不需要关心具体的订阅者。
- 缺点:容易造成内存泄漏,需要手动取消订阅,否则订阅者会一直存在。
const EventBus = {
events: {},
subscribe(event, callback) {
if (!this.events[event]) {
this.events[event] = [];
}
this.events[event].push(callback);
},
publish(event, data) {
if (this.events[event]) {
this.events[event].forEach(callback => callback(data));
}
},
unsubscribe(event, callback) {
if (this.events[event]) {
this.events[event] = this.events[event].filter(cb => cb !== callback);
}
}
};
// 订阅事件
EventBus.subscribe('userLoggedIn', handleUserLoggedIn);
// 发布事件
EventBus.publish('userLoggedIn', { username: 'poetry' });
// 取消订阅事件
EventBus.unsubscribe('userLoggedIn', handleUserLoggedIn);
@前端进阶之旅: 代码已经复制到剪贴板
- 观察者模式:
- 使用场景:当一个对象的状态发生变化时,需要通知其他依赖该对象的对象进行相应操作时,可以使用观察者模式。例如,实现一个数据的双向绑定功能。
- 优点:解耦了对象之间的关系,被观察者和观察者之间松耦合,可以动态添加和移除观察者。
- 缺点:增加了对象之间的相互依赖关系,可能导致系统复杂度增加。
class Observable {
constructor() {
this.observers = [];
}
addObserver(observer) {
this.observers.push(observer);
}
removeObserver(observer) {
this.observers = this.observers.filter(obs => obs !== observer);
}
notify(data) {
this.observers.forEach(observer => observer.update(data));
}
}
class Observer {
update(data) {
// Perform necessary actions with the data
}
}
const observable = new Observable();
const observer1 = new Observer();
const observer2 = new Observer();
observable.addObserver(observer1);
observable.addObserver(observer2);
// Notify observers
observable.notify({ message: 'Data updated' });
// Remove observer
observable.removeObserver(observer2);
@前端进阶之旅: 代码已经复制到剪贴板
- 装饰模式:
- 使用场景:当需要在不修改原始对象的情况下,动态地给对象添加额外的功能时,可以使用装饰模式。例如,给一个基本的组件添加日志记录或性能监测的功能。
- 优点:遵循开放封闭原则,不需要修改原始对象的结构,可以灵活地添加或移除功能。
- 缺点:增加了类的数量,可能导致类的层次复杂。
class Component {
operation() {
// Perform the component's operation
}
}
class Decorator {
constructor(component) {
this.component = component;
}
operation() {
// Add additional functionality
this.component.operation();
}
}
// Create an instance of the component
const component = new Component();
// Create a decorated component
const decoratedComponent = new Decorator(component);
// Call the operation on the decorated component
decoratedComponent.operation();
@前端进阶之旅: 代码已经复制到剪贴板
- 策略模式:
- 使用场景:当需要根据不同的情况选择不同的算法或策略时,可以使用策略模式。例如,根据用户选择的不同排序方式对数据进行排序。
- 优点:简化了条件语句的复杂度,将算法封装成独立的策略类,方便扩展和维护。
- 缺点:增加了类的数量,可能导致类的层次复杂。
class SortingStrategy {
sort(data) {
// Perform the sorting algorithm
}
}
class BubbleSortStrategy extends SortingStrategy {
sort(data) {
// Implement bubble sort algorithm
console.log('Bubble sort applied');
// Perform bubble sort algorithm
}
}
class QuickSortStrategy extends SortingStrategy {
sort(data) {
console.log('Quick sort applied');
// Perform quick sort algorithm
}
}
class Sorter {
constructor(strategy) {
this.strategy = strategy;
}
setStrategy(strategy) {
this.strategy = strategy;
}
sort(data) {
this.strategy.sort(data);
}
}
// Create sorting strategies
const bubbleSort = new BubbleSortStrategy();
const quickSort = new QuickSortStrategy();
// Create sorter and set initial strategy
const sorter = new Sorter(bubbleSort);
// Sort using current strategy
sorter.sort(data);
// Change strategy
sorter.setStrategy(quickSort);
// Sort using new strategy
sorter.sort(data);
@前端进阶之旅: 代码已经复制到剪贴板
总结
- 工厂模式 - 传入参数即可创建实例
- 虚拟 DOM 根据参数的不同返回基础标签的
Vnode和组件Vnode
- 虚拟 DOM 根据参数的不同返回基础标签的
- 单例模式 - 整个程序有且仅有一个实例
vuex和vue-router的插件注册方法install判断如果系统存在实例就直接返回掉
- 发布-订阅模式 (
vue事件机制) - 观察者模式 (响应式数据原理)
- 装饰模式: (
@装饰器的用法) - 策略模式 策略模式指对象有某个行为,但是在不同的场景中,该行为有不同的实现方案-比如选项的合并策略
122 原型链判断
请写出下面的答案
Object.prototype.__proto__;
Function.prototype.__proto__;
Object.__proto__;
Object instanceof Function;
Function instanceof Object;
Function.prototype === Function.__proto__;
@前端进阶之旅: 代码已经复制到剪贴板
答案
Object.prototype.__proto__; //null
Function.prototype.__proto__; //Object.prototype
Object.__proto__; //Function.prototype
Object instanceof Function; //true
Function instanceof Object; //true
Function.prototype === Function.__proto__; //true
@前端进阶之旅: 代码已经复制到剪贴板
这道题目深入考察了原型链相关知识点 尤其是
Function和Object的之间的关系
123 RAF 和 RIC 是什么
requestAnimationFrame: 告诉浏览器在下次重绘之前执行传入的回调函数(通常是操纵 dom,更新动画的函数);由于是每帧执行一次,那结果就是每秒的执行次数与浏览器屏幕刷新次数一样,通常是每秒60次。requestIdleCallback:: 会在浏览器空闲时间执行回调,也就是允许开发人员在主事件循环中执行低优先级任务,而不影响一些延迟关键事件。如果有多个回调,会按照先进先出原则执行,但是当传入了timeout,为了避免超时,有可能会打乱这个顺序
下面是 requestAnimationFrame 和 requestIdleCallback 的示例代码:
requestAnimationFrame
当使用 requestAnimationFrame 实现动画时,通常需要更新 DOM 元素的属性来创建平滑的动画效果。以下是一个使用 requestAnimationFrame 的简单示例代码:
function animate() {
const element = document.getElementById('myElement');
const position = parseInt(element.style.left) || 0;
const speed = 2;
// 更新元素位置
element.style.left = position + speed + 'px';
// 检查是否到达目标位置
if (position < 200) {
// 请求下一帧动画
requestAnimationFrame(animate);
}
}
// 开始执行动画
requestAnimationFrame(animate);
@前端进阶之旅: 代码已经复制到剪贴板
在上面的代码中,animate 函数用于执行动画操作。在每一帧动画中,我们通过获取元素的当前位置,增加一个速度值,然后更新元素的位置。在这个例子中,我们通过改变 left 属性来实现水平移动的动画效果。
在每一帧动画结束后,我们检查是否到达了目标位置(这里假设目标位置为左侧 200px 的位置),如果没有到达目标位置,我们再次请求下一帧动画,从而创建连续的动画效果。
通过使用 requestAnimationFrame,可以实现流畅的动画效果,并且能够与浏览器的重绘周期同步,避免了过度绘制的问题。这样可以提供更好的性能和用户体验。
requestIdleCallback
function processIdleTasks(deadline) {
while ((deadline.timeRemaining() > 0 || deadline.didTimeout) && tasks.length > 0) {
// 执行低优先级任务
const task = tasks.shift();
task();
}
if (tasks.length > 0) {
// 如果还有任务未完成,继续请求下一次 idle callback
requestIdleCallback(processIdleTasks);
}
}
// 添加低优先级任务
function addTask(task) {
tasks.push(task);
// 如果当前没有请求进行中,则请求下一次 idle callback
if (tasks.length === 1) {
requestIdleCallback(processIdleTasks);
}
}
// 低优先级任务列表
const tasks = [];
// 添加低优先级任务
addTask(function() {
console.log('Task 1');
});
addTask(function() {
console.log('Task 2');
});
addTask(function() {
console.log('Task 3');
});
@前端进阶之旅: 代码已经复制到剪贴板
在上面的代码中,requestIdleCallback 用于执行低优先级任务。首先定义了一个 processIdleTasks 函数,它会在浏览器空闲时间内执行任务。在函数内部,通过 deadline.timeRemaining() 方法判断是否还有空闲时间可用,并且任务队列不为空时,循环执行低优先级任务。如果还有未完成的任务,会继续请求下一次 idle callback。
然后,通过 addTask 函数向低优先级任务列表中添加任务。当添加任务时,如果当前没有请求进行中,则请求下一次 idle callback 来执行任务。
通过使用 requestIdleCallback,可以在浏览器空闲时间内执行低优先级任务,而不会影响一些延迟关键事件的执行。这有助于提高应用程序的性能和响应能力。
124 js自定义事件
三要素:
document.createEvent()event.initEvent()element.dispatchEvent()
在 JavaScript 中,可以使用以下三个要素来创建和触发自定义事件:
document.createEvent(): 这个方法用于创建一个新的事件对象。可以使用不同的方法根据需要创建不同类型的事件对象,例如createEvent('Event')、createEvent('CustomEvent')等。这个方法已经过时,推荐使用更现代的方式创建事件对象,如下文所示。Event构造函数:这是现代的方式来创建事件对象。可以使用new Event(eventName)创建一个新的事件对象,其中eventName是自定义事件的名称。event.initEvent(): 对于使用document.createEvent()创建的事件对象,可以调用initEvent(eventName, bubbles, cancelable)方法进行初始化。其中eventName是事件名称,bubbles是一个布尔值,表示事件是否冒泡,cancelable是一个布尔值,表示事件是否可以被取消。element.dispatchEvent(): 这个方法用于触发自定义事件。可以将创建好的事件对象通过调用dispatchEvent(event)方法分派到指定的 DOM 元素上,从而触发相应的事件处理程序。
下面是一个示例,演示如何使用这三个要素来创建和触发自定义事件:
// 创建自定义事件对象
const event = new Event('customEvent');
// 初始化事件对象(可选)
event.initEvent('customEvent', true, true);
// 获取要触发事件的元素
const element = document.getElementById('myElement');
// 触发自定义事件
element.dispatchEvent(event);
@前端进阶之旅: 代码已经复制到剪贴板
在上述示例中,首先使用 Event 构造函数创建了一个名为 'customEvent' 的自定义事件对象。然后,可以选择使用 initEvent() 方法对事件对象进行初始化,指定事件名称、冒泡和取消属性。
最后,通过 getElementById() 方法获取要触发事件的元素,并调用 dispatchEvent() 方法将自定义事件对象分派到该元素上,从而触发自定义事件。
请注意,这里使用的是现代的事件创建和触发方法,而不是使用过时的 createEvent() 方法。这是因为现代的方法更加简单直观,并且具有更好的性能。
125 前端性能定位、优化指标以及计算方法
前端性能优化 已经是老生常谈的一项技术了 很多人说起性能优化方案的时候头头是道 但是真正的对于性能分析定位和性能指标这块却一知半解 所以这道题虽然和性能相关 但是考察点在于平常项目如何进行性能定位和分析
- 我们可以从 前端性能监控-埋点以及
window.performance相关的api去回答- 也可以从性能分析工具
Performance和Lighthouse- 还可以从性能指标
LCPFCPFIDCLS等去着手
下面是关于前端性能定位、优化指标以及计算方法的一些信息:
- 前端性能监控和埋点:通过在关键点上埋点,可以监控网页的加载时间、资源请求、错误等关键性能指标。常用的前端性能监控工具包括自定义的日志记录、第三方服务(如Google Analytics、Sentry等)和开源工具(如Fundebug、Tongji.js等)。此外,
window.performanceAPI提供了性能数据,可以通过它获取更详细的性能指标,如页面加载时间、资源加载时间等。 - 性能分析工具:使用性能分析工具可以深入分析网站的性能瓶颈,并提供有针对性的优化建议。其中两个常用的工具是:
- Performance:现代浏览器提供的内置性能分析工具,可通过浏览器开发者工具访问。它提供了时间轴记录、CPU、内存和网络分析等功能,帮助开发者找到性能瓶颈并进行优化。
- Lighthouse:由Google开发的开源工具,可用于自动化测试网页性能,并提供综合的性能报告。它评估网页在多个方面的性能表现,并给出相应的优化建议。
- 性能指标:性能指标是用于衡量网站性能的关键指标,常用的指标包括:
- LCP(Largest Contentful Paint):标识页面上最大的可见内容加载完成的时间,衡量用户可见内容的加载速度。
- FCP(First Contentful Paint):表示页面上第一个内容元素(如文字、图片)呈现的时间,标识页面加载的起点。
- FID(First Input Delay):测量从用户首次与页面交互(点击链接、按钮等)到浏览器实际响应该交互的时间。
- CLS(Cumulative Layout Shift):测量页面上元素布局的稳定性,即元素在页面加载过程中发生的意外移动的累积量。
- TTFB(Time To First Byte):表示从发起请求到接收到第一个字节的时间,衡量服务器响应速度。
- TTI(Time To Interactive):表示页面变得可交互的时间,即用户可以进行操作和与页面进行交互的时间点。
- TBT(Total Blocking Time):衡量页面在加载过程中存在的阻塞时间总和,即浏览器忙于处理 JavaScript 执行而导致无法响应用户输入的时间。
这些指标可以通过性能分析工具或浏览器开发者工具来获得。优化这些指标有助于提升页面加载速度、响应性和用户体验。
以下是这些指标的计算方法和示例代码:
1. LCP(Largest Contentful Paint):
- 计算方法:监测到页面上的最大可见元素(如图片、视频等)加载完成的时间点。
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
if (entry.entryType === 'largest-contentful-paint') {
console.log('LCP:', entry.renderTime || entry.loadTime);
}
}
});
observer.observe({ type: 'largest-contentful-paint', buffered: true });
@前端进阶之旅: 代码已经复制到剪贴板
2. FCP(First Contentful Paint):
- 计算方法:测量页面上第一个内容元素(如文字、图片)呈现的时间。
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
if (entry.entryType === 'paint' && entry.name === 'first-contentful-paint') {
console.log('FCP:', entry.startTime);
}
}
});
observer.observe({ type: 'paint', buffered: true });
@前端进阶之旅: 代码已经复制到剪贴板
3. FID(First Input Delay):
- 计算方法:
- 测量用户首次与页面交互(点击链接、按钮等)到浏览器实际响应该交互的时间。
- 计算两个时间点之间的差值,即为
FID。
document.addEventListener('DOMContentLoaded', () => {
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
if (entry.entryType === 'first-input' && entry.startTime < 5000) {
console.log('FID:', entry.processingStart - entry.startTime);
}
}
});
observer.observe({ type: 'first-input', buffered: true });
});
@前端进阶之旅: 代码已经复制到剪贴板
4. CLS(Cumulative Layout Shift):
- 计算方法:监测到页面上元素布局发生变化时,记录布局变化的量。将所有布局变化的量累积起来,即为 CLS。
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
if (entry.entryType === 'layout-shift') {
console.log('CLS:', entry.value);
}
}
});
observer.observe({ type: 'layout-shift', buffered: true });
@前端进阶之旅: 代码已经复制到剪贴板
5. TTFB(Time To First Byte):
- 计算方法:
- 记录发起请求的时间点。
- 监测到接收到第一个字节的时间点。
- 计算两个时间点之间的差值,即为 TTFB。
const startTime = performance.now();
fetch('https://example.com')
.then((response) => {
const endTime = performance.now();
const duration = endTime - startTime;
console.log('TTFB:', duration);
return response;
});
@前端进阶之旅: 代码已经复制到剪贴板
6. TTI(Time To Interactive):
- 计算方法:测量页面变得可交互的时间,即用户可以进行操作和与页面进行交互的时间点。
- 监测到页面上的关键元素加载完成的时间点。
- 监测到所有关键脚本的执行完成的时间点。
- 监测到用户首次与页面交互的时间点。
- 计算这些时间点之间的最大值,即为 TTI。
function calculateTTI() {
const longTasks = performance.getEntriesByType('longtask');
const blockingTime = longTasks.reduce((total, task) => total + task.duration, 0);
console.log('TTI:', blockingTime);
}
window.addEventListener('load', () => {
setTimeout(calculateTTI, 5000);
});
@前端进阶之旅: 代码已经复制到剪贴板
7. TBT(Total Blocking Time):
- 计算方法:衡量页面在加载过程中存在的阻塞时间总和,即浏览器忙于处理 JavaScript 执行而导致无法响应用户输入的时间。
- 监测到页面加载过程中 JavaScript 阻塞用户输入的时间段。
- 将所有阻塞时间段的持续时间累积起来,即为 TBT。
function calculateTBT() {
const longTasks = performance.getEntriesByType('longtask');
const blockingTime = longTasks.reduce((total, task) => total + task.duration, 0);
console.log('TBT:', blockingTime);
}
window.addEventListener('load', () => {
setTimeout(calculateTBT, 5000);
});
@前端进阶之旅: 代码已经复制到剪贴板
上述示例代码可以在页面中嵌入并运行,通过浏览器的开发者工具或控制台查看相应的性能指标输出。注意,这些示例代码只是基本的计算方法,实际使用时可能需要根据具体的情况进行调整和扩展。此外,为了准确测量性能指标,建议在真实用户环境中进行测试和监测。
使用 web-vitals 库可以更方便地获取和处理性能指标。下面是使用 web-vitals 库的示例代码:
import { getCLS, getFID, getLCP, getFCP, getTTFB } from 'web-vitals';
// CLS (Cumulative Layout Shift)
getCLS(console.log);
// FID (First Input Delay)
getFID(console.log);
// LCP (Largest Contentful Paint)
getLCP(console.log);
// FCP (First Contentful Paint)
getFCP(console.log);
// TTFB (Time To First Byte)
getTTFB(console.log);
@前端进阶之旅: 代码已经复制到剪贴板
上述代码使用了 getCLS、getFID、getLCP、getFCP 和 getTTFB 函数来获取对应的性能指标,并将结果通过回调函数打印到控制台。
要使用 web-vitals 库,需要先安装该库并在项目中引入。可以使用 npm 或 yarn 进行安装:
npm install web-vitals
@前端进阶之旅: 代码已经复制到剪贴板
然后,在项目中引入 web-vitals:
import { getCLS, getFID, getLCP, getFCP, getTTFB } from 'web-vitals';
@前端进阶之旅: 代码已经复制到剪贴板
接下来,可以通过调用相应的函数来获取性能指标,并在回调函数中处理指标的结果。示例中使用 console.log 打印结果,但你可以根据需要进行其他的处理操作。
请注意,以上示例代码仅展示了如何使用 web-vitals 来获取指标,实际应用中可能需要根据具体情况进行处理和使用其他工具或方法来进行更全面的性能分析和优化。
126 谈谈你对函数是一等公民的理解
JavaScript 中的函数被称为一等公民(First-class Citizens),这意味着函数在语言中被视为普通的值,可以像其他数据类型(例如数字、字符串、对象)一样被传递、赋值、存储和返回。
以下是对 JavaScript 函数作为一等公民的几个重要特性和理解:
- 可以赋值给变量:函数可以像其他数据类型一样赋值给变量。你可以将函数定义存储在变量中,并在需要时将其作为值传递给其他函数或存储在数据结构中。
- 可以作为参数传递:函数可以作为参数传递给其他函数。这使得函数能够接受其他函数作为输入,并根据需要执行或处理。
- 可以作为返回值:函数可以作为另一个函数的返回值。你可以在一个函数内部定义并返回另一个函数,这使得函数能够灵活地生成和返回其他函数。
- 可以存储在数据结构中:函数可以存储在数组、对象或其他数据结构中。这使得你可以在需要时使用函数,并根据需求对其进行组合、迭代或操作。
- 可以通过字面量或表达式定义:函数可以通过函数字面量(函数表达式)或函数声明来定义。这为我们提供了灵活性,可以根据需要选择不同的方式来定义函数。
- 可以通过闭包捕获状态:由于 JavaScript 中的函数形成了闭包,函数可以访问其所在作用域中的变量。这意味着函数可以捕获并保持对外部变量的引用,即使在函数外部不可访问的情况下也可以使用。
这些特性使得 JavaScript 中的函数非常强大和灵活。函数作为一等公民使得我们可以使用函数式编程的思想和技术,如高阶函数、函数组合、柯里化等,以更加优雅和灵活地编写代码。
四、jQuery相关
1 你觉得jQuery源码有哪些写的好的地方
jQuery源码采用模块化的设计,将不同功能的代码模块化,并通过jQuery.fn扩展原型链,使得可以灵活地使用各种功能和方法。这样的设计使得代码结构清晰,易于维护和扩展。jQuery源码中考虑了跨浏览器兼容性,通过封装和处理不同浏览器的差异,使得开发者可以方便地编写跨浏览器兼容的代码。jQuery源码中使用了许多优化技巧,如缓存变量、使用局部作用域、使用原生DOM操作等,以提高性能和执行效率。jQuery源码注重代码的可读性和可维护性,采用了语义化的命名和良好的代码风格,使得代码易于理解和维护。jQuery源码提供了丰富的插件系统,使得开发者可以根据自己的需求扩展和定制jQuery的功能,且插件之间可以互相独立运行,提高了代码的可扩展性和重用性。
这些优点使得jQuery成为一个广泛使用的JavaScript库,并且为众多开发者提供了便利和效率。
以下是一个简单的示例,展示了jQuery源码中的一些写法和优点:
(function( window, undefined ) {
// 在匿名函数中封装代码,避免全局污染
var jQuery = function( selector, context ) {
// jQuery的构造函数
// 创建并返回一个jQuery对象,通过jQuery.fn扩展原型链
return new jQuery.fn.init( selector, context );
};
// 将jQuery原型指向jQuery.fn,方便使用jQuery.fn的方法
jQuery.fn = jQuery.prototype = {
// jQuery的原型对象
constructor: jQuery,
// 扩展的方法和属性
init: function( selector, context ) {
// 初始化函数
// ...
return this;
},
// 更多方法...
};
// 在jQuery原型上扩展方法
jQuery.fn.extend({
// 扩展的方法
// ...
});
// 将jQuery暴露到全局作用域
window.jQuery = window.$ = jQuery;
})( window );
@前端进阶之旅: 代码已经复制到剪贴板
这段代码展示了jQuery源码中的一些优点,包括使用匿名函数封装代码、通过原型链扩展方法、使用局部变量和缓存、考虑跨浏览器兼容性等。这些设计和写法使得jQuery成为一个功能强大、性能优秀、易于使用和扩展的JavaScript库。
2 jQuery 的实现原理
jQuery的实现原理可以总结如下:
- 使用立即调用表达式(IIFE):jQuery的源码被包裹在一个匿名的立即调用函数表达式中
(function() { /* jQuery code */ })();,这样可以创建一个独立的函数作用域,避免变量污染全局命名空间。 - 创建一个全局变量:通过
window.jQuery = window.$ = jQuery;将 jQuery 对象赋值给window对象的属性,从而使得 jQuery 和$在全局作用域下可访问,方便其他代码使用。 - 构造函数和原型链:jQuery 使用
function jQuery() { /* constructor code */ }定义了一个构造函数,使用jQuery.prototype扩展了原型链,从而在构造函数的基础上拥有了一系列方法和属性。 - DOM 操作和选择器:jQuery 封装了一系列 DOM 操作和选择器的方法,使得开发者可以通过简洁的语法来操作和遍历 DOM 元素。
- 链式调用:jQuery 的方法通常返回 jQuery 对象本身,使得可以通过链式调用的方式进行连续的操作和修改。
- 事件处理:jQuery 提供了强大的事件处理机制,可以方便地绑定和解绑事件,并提供了一系列事件处理方法。
- AJAX 请求:jQuery 提供了简化的 AJAX 方法,使得进行异步数据请求变得更加便捷。
- 动画效果:jQuery 内置了一些常用的动画效果,如淡入淡出、滑动等,可以通过简单的方法调用来实现动画效果。
总的来说,jQuery的实现原理是通过封装和扩展原生JavaScript功能,提供了便捷的DOM操作、事件处理、动画效果、AJAX请求等功能,使得开发者可以更快速、高效地开发和操作网页应用。
3 jQuery.fn 的 init 方法返回的 this 指的是什么对象
jQuery.fn的init方法返回的this指的是jQuery对象本身。当用户使用jQuery()或$()初始化jQuery对象时,实际上是调用了init方法,而这个方法返回的就是一个jQuery对象,也就是this。通过返回this,jQuery实现了链式调用的特性,可以连续对同一个 jQuery 对象进行操作和调用方法。例如:
var $div = $('div'); // 初始化一个 jQuery 对象
$div.addClass('highlight') // 对该 jQuery 对象调用 addClass 方法
.css('color', 'red') // 继续调用 css 方法
.text('Hello, World!'); // 继续调用 text 方法
// 上述操作可以链式调用,连续对同一个 jQuery 对象进行多个方法的操作
@前端进阶之旅: 代码已经复制到剪贴板
在这个例子中,$div 是一个 jQuery 对象,通过调用 addClass、css 和 text 方法,并在每次方法调用后返回 this,实现了链式调用的效果。这样的链式调用可以简化代码,提高可读性和开发效率。
4 jQuery.extend 与 jQuery.fn.extend 的区别
jQuery.extend() 和 jQuery.fn.extend() 是 jQuery 提供的两个方法用于扩展功能。
jQuery.extend(object):这个方法用于向 jQuery 添加静态方法,也称为工具方法。通过传入一个对象,可以将对象中的方法和属性添加到 jQuery 对象上,从而可以通过$.method()的形式来调用这些静态方法。例如,$.min()和$.max()是通过$.extend()添加的静态方法,可以直接通过$.min()和$.max()来调用。jQuery.extend([deep,] target, object1 [, objectN]):这个方法用于扩展目标对象(target),将一个或多个对象的属性和方法合并到目标对象中。它可以实现对象的深度拷贝,还可以控制是否进行递归合并。第一个参数deep是可选的,用于控制是否进行深度拷贝,默认为浅拷贝。目标对象将被修改,同时返回目标对象。这个方法主要用于对象的合并和扩展。jQuery.fn.extend(json):这个方法用于向 jQuery 原型(jQuery.fn)添加成员函数,也称为实例方法。通过传入一个对象,可以将对象中的方法添加到 jQuery 原型上,从而可以通过$(selector).method()的形式来调用这些实例方法。例如,$.fn.alertValue()是通过$.fn.extend()添加的实例方法,可以通过$("#email").alertValue()来调用。
综上所述,$.extend() 用于添加静态方法和进行对象的合并,而 $.fn.extend() 用于添加实例方法。它们都是为了扩展 jQuery 的功能,提供更多的方法和功能供开发者使用。
当使用
$.extend()方法时,可以通过以下示例来理解其用法:
// 添加静态方法
$.extend({
min: function(a, b) {
return a < b ? a : b;
},
max: function(a, b) {
return a > b ? a : b;
}
});
console.log($.min(2, 3)); // 输出: 2
console.log($.max(4, 5)); // 输出: 5
// 合并对象
var settings = { validate: false, limit: 5 };
var options = { validate: true, name: "bar" };
$.extend(settings, options);
console.log(settings); // 输出: { validate: true, limit: 5, name: "bar" }
@前端进阶之旅: 代码已经复制到剪贴板
当使用 $.fn.extend() 方法时,可以通过以下示例来理解其用法:
// 添加实例方法
$.fn.extend({
alertValue: function() {
$(this).click(function() {
alert($(this).val());
});
}
});
$("#email").alertValue(); // 点击元素时,弹出其值
@前端进阶之旅: 代码已经复制到剪贴板
在上述示例中,$.extend() 用于添加静态方法 min() 和 max(),可以通过 $.min() 和 $.max() 来调用。另外,$.extend() 也用于将 options 对象的属性合并到 settings 对象中,实现对象的合并。
而 $.fn.extend() 用于添加实例方法 alertValue(),通过选取具有 id 为 "email" 的元素,并调用 .alertValue() 方法,当点击该元素时会弹出其值。
5 jQuery 的属性拷贝(extend)的实现原理是什么,如何实现深拷贝
jQuery 的属性拷贝(extend)实现原理如下:
- 浅拷贝:当使用
$.extend(target, obj1, obj2, ...)进行属性拷贝时,它会将obj1、obj2等对象的属性复制到target对象中。如果属性值是对象或数组,那么复制的是对象或数组的引用,即浅拷贝。这意味着修改复制后的对象中的引用类型属性时,原始对象和拷贝后的对象会同时受到影响。 - 深拷贝:如果需要进行深拷贝,即复制对象及其引用类型属性的值而不是引用,可以通过使用
$.extend(true, target, obj1, obj2, ...)来实现。这样,在拷贝过程中,会递归遍历对象的属性,对引用类型属性进行深度拷贝。
以下是一个示例,展示浅拷贝和深拷贝的区别:
var obj1 = {
name: "poetry",
age: 30,
hobbies: ["reading", "playing"],
address: {
city: "New York",
country: "USA"
}
};
// 浅拷贝
var shallowCopy = $.extend({}, obj1);
shallowCopy.name = "Jane";
shallowCopy.hobbies.push("swimming");
shallowCopy.address.city = "San Francisco";
console.log(obj1); // 原始对象受到影响
console.log(shallowCopy);
// 深拷贝
var deepCopy = $.extend(true, {}, obj1);
deepCopy.name = "Mike";
deepCopy.hobbies.push("traveling");
deepCopy.address.city = "Chicago";
console.log(obj1); // 原始对象不受影响
console.log(deepCopy);
@前端进阶之旅: 代码已经复制到剪贴板
在上述示例中,浅拷贝的结果是 shallowCopy,它复制了 obj1 的属性,包括引用类型的数组 hobbies 和对象 address。当修改 shallowCopy 的属性值时,原始对象 obj1 也会受到影响。
而深拷贝的结果是 deepCopy,它同样复制了 obj1 的属性,但是在拷贝过程中,对于引用类型的属性值进行了深度拷贝。因此,修改 deepCopy 的属性值不会影响到原始对象 obj1。
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
9 Bootstrap如何设置响应式表格?
要创建响应式的表格,可以将表格包裹在具有 table-responsive 类的父元素中。这样可以使表格在小屏幕设备上水平滚动,并保持适当的显示。
下面是设置响应式表格的示例代码:
<div class="table-responsive">
<table class="table">
<!-- 表格内容 -->
</table>
</div>
@前端进阶之旅: 代码已经复制到剪贴板
通过将表格包裹在具有 table-responsive 类的 <div> 元素中,即可实现响应式的表格。当表格在小屏幕设备上无法适应屏幕宽度时,用户可以通过水平滚动来查看表格的内容。
请注意,响应式表格需要使用 table 类来设置基本的表格样式。可以根据需要添加其他 Bootstrap 提供的表格类,如表格样式类(table-striped、table-bordered 等)和表格颜色类(table-primary、table-success 等)等。
10 使用Bootstrap创建垂直表单的基本步骤?
使用 Bootstrap 创建垂直表单的基本步骤如下:
- 创建一个
<form>元素,并添加role="form"属性,用于标识该表单的角色。
<form role="form">
<!-- 表单内容 -->
</form>
@前端进阶之旅: 代码已经复制到剪贴板
- 将每个表单项(标签和控件)放置在一个带有
class="form-group"的<div>元素中,这样可以获得最佳的间距和样式。
<form role="form">
<div class="form-group">
<!-- 表单项 -->
</div>
</form>
@前端进阶之旅: 代码已经复制到剪贴板
- 将文本输入框
<input>、文本域<textarea>和下拉菜单<select>元素添加class="form-control"类,以应用 Bootstrap 提供的样式和布局。
<form role="form">
<div class="form-group">
<label for="name">姓名:</label>
<input type="text" class="form-control" id="name" placeholder="请输入姓名">
</div>
<div class="form-group">
<label for="email">邮箱:</label>
<input type="email" class="form-control" id="email" placeholder="请输入邮箱">
</div>
<div class="form-group">
<label for="message">留言:</label>
<textarea class="form-control" id="message" placeholder="请输入留言内容"></textarea>
</div>
</form>
@前端进阶之旅: 代码已经复制到剪贴板
通过以上步骤,你可以使用 Bootstrap 创建一个简单的垂直表单。你可以根据需要添加更多的表单项,并根据 Bootstrap 提供的文档进行样式和布局的调整。
11 使用Bootstrap创建水平表单的基本步骤?
使用 Bootstrap 创建水平表单的基本步骤如下:
- 创建一个
<form>元素,并添加class="form-horizontal"类,以便应用水平表单的样式。
<form class="form-horizontal">
<!-- 表单内容 -->
</form>
@前端进阶之旅: 代码已经复制到剪贴板
- 将每个表单项(标签和控件)放置在一个带有
class="form-group"的<div>元素中,以获得最佳的间距和样式。
<form class="form-horizontal">
<div class="form-group">
<!-- 表单项 -->
</div>
</form>
@前端进阶之旅: 代码已经复制到剪贴板
- 在标签元素中添加
class="control-label"类,以标识其为表单项的标签。
<form class="form-horizontal">
<div class="form-group">
<label for="name" class="control-label">姓名:</label>
<div class="col-sm-8">
<input type="text" class="form-control" id="name" placeholder="请输入姓名">
</div>
</div>
<div class="form-group">
<label for="email" class="control-label">邮箱:</label>
<div class="col-sm-8">
<input type="email" class="form-control" id="email" placeholder="请输入邮箱">
</div>
</div>
</form>
@前端进阶之旅: 代码已经复制到剪贴板
通过以上步骤,你可以使用 Bootstrap 创建一个简单的水平表单。你可以根据需要添加更多的表单项,并根据 Bootstrap 提供的文档进行样式和布局的调整。
12 使用Bootstrap如何创建表单控件的帮助文本?
要在 Bootstrap 中创建表单控件的帮助文本,可以按照以下步骤进行操作:
- 将帮助文本放置在与表单控件相关联的
<div>或<form-group>元素内。
<div class="form-group">
<label for="exampleInputName">姓名</label>
<input type="text" class="form-control" id="exampleInputName">
<!-- 帮助文本 -->
</div>
@前端进阶之旅: 代码已经复制到剪贴板
- 在帮助文本的标签(通常是
<span>或<p>)中添加class="help-block"。
<div class="form-group">
<label for="exampleInputName">姓名</label>
<input type="text" class="form-control" id="exampleInputName">
<span class="help-block">这里是帮助文本</span>
</div>
@前端进阶之旅: 代码已经复制到剪贴板
通过以上步骤,你可以在 Bootstrap 的表单控件中添加帮助文本。帮助文本将根据 Bootstrap 的样式进行显示,并提供相关的提示或指导信息。你可以根据需要自定义帮助文本的样式。
13 使用Bootstrap激活或禁用按钮要如何操作?
要在 Bootstrap 中激活或禁用按钮,可以按照以下步骤进行操作:
- 激活按钮:给按钮添加
.active的class。
<button type="button" class="btn btn-primary active">激活按钮</button>
@前端进阶之旅: 代码已经复制到剪贴板
- 禁用按钮:给按钮添加
disabled="disabled"的属性。
<button type="button" class="btn btn-primary" disabled="disabled">禁用按钮</button>
@前端进阶之旅: 代码已经复制到剪贴板
通过以上步骤,你可以在 Bootstrap 中激活或禁用按钮。激活按钮将应用活动状态的样式,禁用按钮将禁用按钮的交互性并应用禁用状态的样式。
14 Bootstrap有哪些关于img的class?
在 Bootstrap 中,有以下关于 <img> 元素的类(class)可用:
.img-rounded:为图片添加圆角效果
<img src="image.jpg" class="img-rounded" alt="圆角图片">
@前端进阶之旅: 代码已经复制到剪贴板
.img-circle:将图片呈现为圆形。
<img src="image.jpg" class="img-circle" alt="圆形图片">
@前端进阶之旅: 代码已经复制到剪贴板
.img-thumbnail:为图片添加缩略图样式。
<img src="image.jpg" class="img-thumbnail" alt="缩略图">
@前端进阶之旅: 代码已经复制到剪贴板
.img-responsive:使图片具有响应式特性,可以根据父元素的大小自动调整图片的尺寸。
<img src="image.jpg" class="img-responsive" alt="响应式图片">
@前端进阶之旅: 代码已经复制到剪贴板
通过使用这些类,可以为图片添加不同的样式和功能,以满足项目的需求。
15 Bootstrap中有关元素浮动及清除浮动的class?
在 Bootstrap 中,有以下关于元素浮动及清除浮动的类(class)可用:
.pull-left:将元素浮动到左边。
<div class="pull-left">左浮动元素</div>
@前端进阶之旅: 代码已经复制到剪贴板
.pull-right:将元素浮动到右边。
<div class="pull-right">右浮动元素</div>
@前端进阶之旅: 代码已经复制到剪贴板
.clearfix:清除浮动,用于解决浮动元素导致的父元素高度塌陷的问题。一般在包含浮动元素的父元素上应用此类。
<div class="clearfix">
<div class="pull-left">左浮动元素</div>
<div class="pull-right">右浮动元素</div>
</div>
@前端进阶之旅: 代码已经复制到剪贴板
通过使用这些类,可以实现元素的浮动和清除浮动的效果,使布局更加灵活和符合设计要求。
16 除了屏幕阅读器外,其他设备上隐藏元素的class?
除了屏幕阅读器外,可以使用 .sr-only 类来隐藏元素,这个类可以在其他设备上隐藏元素,但在屏幕阅读器中仍然可见。这对于提供辅助功能和可访问性非常有用。
例如,可以将 .sr-only 类应用于某个元素,以隐藏其内容:
<span class="sr-only">这段文本在其他设备上隐藏</span>
@前端进阶之旅: 代码已经复制到剪贴板
这样,在常规的可视设备上,这段文本是隐藏的,而在屏幕阅读器中,用户仍然可以访问和阅读这段文本的内容。
17 Bootstrap如何制作下拉菜单?
- 将下拉菜单包裹在
class="dropdown"的<div>中; - 在触发下拉菜单的按钮中添加:
class="btn dropdown-toggle" id="dropdownMenu1" data-toggle="dropdown" - 在包裹下拉菜单的ul中添加:
class="dropdown-menu" role="menu" aria-labelledby="dropdownMenu1" - 在下拉菜单的列表项中添加:
role="presentation"。其中,下拉菜单的标题要添加class="dropdown-header",选项部分要添加tabindex="-1"。
正确,您提供的步骤是制作下拉菜单的基本步骤。下面是一个示例代码:
<div class="dropdown">
<button class="btn dropdown-toggle" id="dropdownMenu1" data-toggle="dropdown" aria-haspopup="true" aria-expanded="false">
下拉菜单
<span class="caret"></span>
</button>
<ul class="dropdown-menu" role="menu" aria-labelledby="dropdownMenu1">
<li role="presentation"><a role="menuitem" tabindex="-1" href="#">选项1</a></li>
<li role="presentation"><a role="menuitem" tabindex="-1" href="#">选项2</a></li>
<li role="presentation"><a role="menuitem" tabindex="-1" href="#">选项3</a></li>
<li role="presentation" class="divider"></li>
<li role="presentation" class="dropdown-header">标题</li>
<li role="presentation"><a role="menuitem" tabindex="-1" href="#">选项4</a></li>
</ul>
</div>
@前端进阶之旅: 代码已经复制到剪贴板
这是一个简单的下拉菜单示例,当点击按钮时,下拉菜单会展开显示选项。您可以根据自己的需求修改按钮文本、菜单项内容和样式。
18 Bootstrap如何制作按钮组?以及水平按钮组和垂直按钮组的优先级?
制作按钮组的基本步骤如下:
- 使用
class="btn-group"的<div>包裹按钮组。这将把一组按钮组合在一起。
<div class="btn-group" role="group" aria-label="按钮组">
<button type="button" class="btn btn-primary">按钮1</button>
<button type="button" class="btn btn-primary">按钮2</button>
<button type="button" class="btn btn-primary">按钮3</button>
</div>
@前端进阶之旅: 代码已经复制到剪贴板
- 如果想要创建垂直按钮组,可以使用
class="btn-group-vertical"。
<div class="btn-group-vertical" role="group" aria-label="垂直按钮组">
<button type="button" class="btn btn-primary">按钮1</button>
<button type="button" class="btn btn-primary">按钮2</button>
<button type="button" class="btn btn-primary">按钮3</button>
</div>
@前端进阶之旅: 代码已经复制到剪贴板
需要注意的是,btn-group的优先级高于btn-group-vertical的优先级。因此,如果使用了btn-group的<div>包裹按钮组,并且同时使用了btn-group-vertical的<div>,则以btn-group的样式为准,按钮组将水平显示。
19 Bootstrap如何设置按钮的下拉菜单?
要设置按钮的下拉菜单,可以将按钮和下拉菜单放置在一个.btn-group中。下面是示例代码:
<div class="btn-group">
<button type="button" class="btn btn-primary">按钮</button>
<button type="button" class="btn btn-primary dropdown-toggle" data-toggle="dropdown" aria-haspopup="true" aria-expanded="false">
<span class="caret"></span>
<span class="sr-only">下拉菜单</span>
</button>
<ul class="dropdown-menu">
<li><a href="#">菜单项1</a></li>
<li><a href="#">菜单项2</a></li>
<li><a href="#">菜单项3</a></li>
</ul>
</div>
@前端进阶之旅: 代码已经复制到剪贴板
在上面的代码中,.btn-group包含了一个按钮和一个带有.dropdown-toggle类的下拉菜单触发器按钮。通过添加.dropdown-toggle类和相关的data-toggle属性,可以实现按钮点击时展示下拉菜单。下拉菜单则是使用.dropdown-menu类定义的。
加载中...
加载中...
加载中...
23 Bootstrap中显示标签的class?
在Bootstrap中,可以使用class="label"来显示标签样式。以下是一个示例代码:
<span class="label">Default</span>
@前端进阶之旅: 代码已经复制到剪贴板
上述代码将创建一个默认样式的标签,你可以根据需要添加更多的class来自定义标签的样式。例如,你可以使用class="label label-primary"来创建一个带有主要颜色的标签。
<span class="label label-primary">Primary</span>
@前端进阶之旅: 代码已经复制到剪贴板
通过添加不同的class,你可以改变标签的颜色、背景色和其他样式,以适应你的设计需求。
24 Bootstrap中如何制作徽章?
在Bootstrap中,可以使用class="badge"来创建徽章。徽章用于在元素上显示一些提示信息或计数。
以下是一个示例代码:
<span class="badge">26</span>
@前端进阶之旅: 代码已经复制到剪贴板
上述代码将创建一个默认样式的徽章,并在徽章上显示数字"26"。你可以根据需要调整徽章的样式,例如改变背景颜色、文本颜色等。
<span class="badge badge-primary">26</span>
@前端进阶之旅: 代码已经复制到剪贴板
通过添加不同的class,你可以改变徽章的外观,使其适应你的设计需求。
25 Bootstrap中超大屏幕的作用是什么?
在Bootstrap中,class="jumbotron"用于创建超大屏幕(Jumbotron)组件。超大屏幕常用于页面的顶部,用于突出显示重要的信息或引导用户的注意力。
超大屏幕组件具有以下特点:
- 标题的字体大小较大,以引起用户的注意。
- 提供更多的外边距,使内容在页面上更突出。
- 可以容纳大量的文本或其他内容,如标题、副标题、按钮等。
- 可以通过自定义样式来改变背景颜色、文本样式等。
以下是一个示例代码:
<div class="jumbotron">
<h1 class="display-4">Welcome to our website!</h1>
<p class="lead">We provide high-quality products and excellent services.</p>
<a class="btn btn-primary btn-lg" href="#" role="button">Learn more</a>
</div>
@前端进阶之旅: 代码已经复制到剪贴板
上述代码将创建一个超大屏幕组件,其中包含一个标题、副标题和一个按钮。你可以根据需要自定义超大屏幕的内容和样式,使其符合你的设计需求。
六、微信小程序相关
1 微信小程序有几个文件
微信小程序主要包含以下几个文件:
.wxml(WeiXin Markup Language):用于描述小程序的页面结构,类似于 HTML。在这个文件中,可以使用小程序提供的组件和自定义的组件,以及使用数据绑定和逻辑控制语句来构建页面的结构。.wxss(WeiXin Style Sheets):是一套样式语言,用于描述.wxml文件中组件的样式。类似于 CSS,可以设置元素的样式、布局、动画效果等。.js:小程序的逻辑处理文件,包含了页面的逻辑代码。可以在这个文件中定义页面的事件处理函数、数据的处理和操作等。通过 JavaScript 的逻辑控制,可以实现小程序的交互功能。app.json:小程序的全局配置文件,必须存在于小程序项目中。在这个文件中,可以进行页面的注册,设置小程序的窗口样式,配置底部导航栏(tabBar),以及设置网络请求等。app.js:小程序的全局 JavaScript 文件,用于监听和处理小程序的生命周期函数、声明全局变量等。可以在这个文件中编写全局的逻辑代码。app.wxss:小程序的全局样式文件,用于设置小程序全局的样式。可以在这个文件中定义小程序的全局样式,如页面的背景色、字体样式、导航栏样式等。
以上是微信小程序中常见的文件类型,每个文件都有其特定的作用和功能,通过不同类型的文件协同工作,可以构建出完整的微信小程序应用。
2 微信小程序怎样跟事件传值
在微信小程序中,可以通过以下方式实现事件传值:
- 使用
data-*属性:给 HTML 元素添加自定义的data-*属性来传递需要的值。例如,可以在某个元素上添加data-id属性来传递对应的 ID 值。在事件处理函数中,可以通过event.currentTarget.dataset来获取这些属性值。
<view data-id="123" bindtap="handleTap">点击我</view>
@前端进阶之旅: 代码已经复制到剪贴板
Page({
handleTap(event) {
const id = event.currentTarget.dataset.id;
console.log(id); // 输出:123
}
})
@前端进阶之旅: 代码已经复制到剪贴板
- 使用自定义属性:在小程序中可以给 HTML 元素添加自定义属性,然后在事件处理函数中通过
event.currentTarget.dataset或event.currentTarget.id来获取这些属性值。
<view id="my-element" data-id="123" bindtap="handleTap">点击我</view>
@前端进阶之旅: 代码已经复制到剪贴板
Page({
handleTap(event) {
const id = event.currentTarget.dataset.id;
const elementId = event.currentTarget.id;
console.log(id); // 输出:123
console.log(elementId); // 输出:my-element
}
})
@前端进阶之旅: 代码已经复制到剪贴板
- 使用
event.detail:对于一些特定的事件,例如表单的提交事件bindsubmit,可以通过event.detail来获取额外的参数值。
<form bindsubmit="handleSubmit">
<input name="username" placeholder="请输入用户名" />
<input name="password" type="password" placeholder="请输入密码" />
<button type="submit">提交</button>
</form>
@前端进阶之旅: 代码已经复制到剪贴板
Page({
handleSubmit(event) {
const { username, password } = event.detail.value;
console.log(username, password); // 输出:输入的用户名和密码
}
})
@前端进阶之旅: 代码已经复制到剪贴板
通过以上方法,可以在微信小程序中实现事件传值,并在事件处理函数中获取传递的值,以实现更灵活的交互和数据处理。
3 小程序的 wxss 和 css 有哪些不一样的地方?
小程序的 WXSS(WeiXin Style Sheets)和 CSS(Cascading Style Sheets)在语法和功能上有一些不同之处:
- 图片引入方式:在 WXSS 中,图片引入需要使用外链地址,即通过网络地址加载图片,而不能使用相对路径或本地文件路径。
/* WXSS */
.image {
background-image: url("https://example.com/image.jpg");
}
@前端进阶之旅: 代码已经复制到剪贴板
- 缺少
body元素:小程序中没有body元素,样式可以直接写在页面的组件选择器上。
<!-- WXML -->
<view class="container">
<text class="text">Hello, Mini Program!</text>
</view>
@前端进阶之旅: 代码已经复制到剪贴板
/* WXSS */
.container {
background-color: #f5f5f5;
}
.text {
color: #333;
font-size: 14px;
}
@前端进阶之旅: 代码已经复制到剪贴板
- 样式导入方式:小程序中的样式文件可以使用
@import导入其他样式文件。
/* WXSS */
@import "common.wxss";
.container {
/* styles */
}
@前端进阶之旅: 代码已经复制到剪贴板
- 不支持部分 CSS 属性和选择器:小程序的 WXSS 并不完全支持所有的 CSS 属性和选择器,例如不支持浮动(
float)和定位(position)属性,也不支持伪类选择器(:hover、:before等)和部分伪元素选择器。
/* WXSS */
.container {
/* 不支持的属性 */
/* 不支持的伪类选择器 */
}
@前端进阶之旅: 代码已经复制到剪贴板
需要注意的是,虽然 WXSS 和 CSS 在一些语法和功能上存在差异,但在基本的样式定义和样式属性上,它们仍然具有相似性,并可以使用类似的语法和规则进行样式的定义和控制。
4 小程序关联微信公众号如何确定用户的唯一性
在小程序中,如果要确定用户的唯一性并与微信公众号关联,可以使用以下步骤:
- 在小程序中调用
wx.login方法获取用户的临时登录凭证code。 - 将获取到的
code发送到后端服务器。 - 后端服务器通过
code调用微信开放平台的接口,如https://api.weixin.qq.com/sns/jscode2session,获取用户的openid和session_key。 - 后端服务器将
openid返回给小程序前端,并存储在客户端。 - 在小程序中调用
wx.getUserInfo方法获取用户信息,包括encryptedData和iv。 - 将获取到的
encryptedData和iv发送到后端服务器。 - 后端服务器使用用户的
session_key对encryptedData进行解密,获取用户的unionId。 - 将用户的
unionId与用户的其他信息一起存储在后端服务器,用于唯一标识用户并与微信公众号关联。
需要注意的是,获取用户的 unionId 需要满足以下条件:
- 小程序需要通过微信开放平台的方式进行接入,而不是独立的小程序账号。
- 小程序和微信公众号需要在同一个微信开放平台账号下,且已经完成了关联。
- 用户在小程序和微信公众号之间需要存在关联关系,例如用户曾经在微信公众号中授权过。
通过以上步骤,可以确定用户的唯一性并与微信公众号进行关联。后续的操作中,可以根据用户的 unionId 进行个性化的业务逻辑处理。
5 微信小程序与vue区别
微信小程序和Vue在一些方面确实存在一些差异,以下是它们之间的一些区别:
- 生命周期:微信小程序的生命周期相对简单,包括
onLoad、onShow、onReady、onHide、onUnload等几个基本生命周期函数。而Vue拥有更为丰富的生命周期钩子函数,例如created、mounted、updated、destroyed等。 - 数据绑定语法:微信小程序使用
{{}}来进行数据绑定,而Vue使用简洁的v-bind和v-model指令来实现数据绑定。 - 元素显示和隐藏:在微信小程序中,可以使用
wx-if和hidden来控制元素的显示和隐藏;而在Vue中,可以使用v-if和v-show来实现相同的功能。 - 事件处理:微信小程序中使用
bindtap或catchtap来绑定事件处理函数,而Vue使用v-on或@来绑定事件处理函数。 - 数据双向绑定:在Vue中,可以通过使用
v-model指令实现表单元素与数据的双向绑定,而微信小程序需要手动获取表单元素的值并将其赋给对应的数据变量。
除了上述的区别之外,微信小程序和Vue在一些基本概念和思想上也存在差异,例如组件化开发的方式、数据状态管理的实现方式等。然而,它们都可以用于构建具有交互性和可复用性的前端应用程序,并且都有着广泛的应用和社区支持。
七、webpack相关
1 优化 webpack 打包体积的思路
优化 webpack 打包体积的思路包括:
- 提取第三方库或通过引用外部文件的方式引入第三方库:将第三方库单独打包,并通过 CDN 引入,减少打包体积。
- 使用代码压缩插件:例如
UglifyJsPlugin,可以压缩 JavaScript 代码,减小文件体积。 - 启用服务器端的 Gzip 压缩:通过服务器端配置 Gzip 压缩,减少传输体积。
- 按需加载资源文件:使用
require.ensure或动态导入(import())的方式按需加载资源文件,避免一次性加载所有资源,优化加载速度和体积。 - 优化 devtool 中的 source-map:选择合适的 devtool 配置,确保在开发阶段能够提供足够的错误追踪信息,但不会增加过多的打包体积。
- 剥离 CSS 文件:将 CSS 文件单独打包,通过
<link>标签引入,利用浏览器的并行加载能力。 - 去除不必要的插件:检查 webpack 配置中的插件,移除不必要的插件或根据环境区分开发环境和生产环境的配置,避免将开发环境的调试工具打包到生产环境中。
除了上述优化思路,还可以考虑以下几点:
- 使用 Tree Shaking:通过配置 webpack,将未使用的代码在打包过程中消除,减少打包体积。
- 使用模块化引入:合理使用 ES6 模块化语法或其他模块化方案,按需引入模块,避免不必要的全局引入。
- 按需加载第三方库:对于较大的第三方库,可以考虑按需加载,而不是一次性全部引入。
- 优化图片资源:压缩图片,使用适当的图片格式,尽量减小图片体积。
- 优化字体文件:如果使用了大量的字体文件,可以考虑只引入需要的字体文件,避免全部引入。
- 使用缓存:通过配置合适的缓存策略,利用浏览器缓存机制,减少重复加载资源。
综合以上优化思路,可以有效减小 webpack 打包生成的文件体积,提升应用性能和加载速度。需要根据具体项目情况和需求,选择合适的优化策略和配置。
2 优化 webpack 打包效率的方法
- 使用增量构建和热更新:在开发环境下,使用增量构建和热更新功能,只重新构建修改过的模块,减少整体构建时间。
- 避免无意义的工作:在开发环境中,避免执行无意义的工作,如提取 CSS、计算文件
hash等,以减少构建时间。 - 配置合适的 devtool:选择适当的 devtool 配置,提供足够的调试信息,但不会对构建性能产生太大影响。
- 选择合适的 loader:根据需要加载的资源类型选择高效的 loader,避免不必要的解析和处理过程。
- 启用 loader 缓存:对于耗时较长的 loader,如
babel-loader,可以启用缓存功能,避免重复处理同一文件。 - 采用引入方式引入第三方库:对于第三方库,可以通过直接引入的方式(如 CDN 引入)来减少打包时间。
- 提取公共代码:通过配置 webpack 的 SplitChunks 插件,提取公共代码,避免重复打包相同的代码,提高打包效率。
- 优化构建时的搜索路径:指定需要构建的目录和不需要构建的目录,减少搜索范围,加快构建速度。
- 模块化引入需要的部分:使用按需引入的方式,只引入需要的模块或组件,避免加载不必要的代码,提高构建效率。
通过以上优化措施,可以有效提升 webpack 的打包效率,减少开发和构建时间,提升开发效率和用户体验。根据具体项目需求和场景,选择适合的优化方法进行配置和调整。
3 编写Loader
编写一个名为 reverse-txt-loader 的 Loader,实现对文本内容进行反转处理的功能。
// reverse-txt-loader.js
module.exports = function (source) {
// 对源代码进行处理,这里是将字符串反转
const reversedSource = source.split('').reverse().join('');
// 返回处理后的 JavaScript 代码作为模块输出
return `module.exports = '${reversedSource}';`;
};
@前端进阶之旅: 代码已经复制到剪贴板
上述代码定义了一个函数,该函数接收一个参数 source,即原始的文本内容。在函数内部,我们将源代码进行反转处理,并将处理后的结果拼接成一个字符串,再通过 module.exports 输出为一个 JavaScript 模块。
要使用这个 Loader,需要在 webpack 配置中指定该 Loader 的路径:
// webpack.config.js
module.exports = {
// ...
module: {
rules: [
{
test: /\.txt$/,
use: [
{
loader: './path/reverse-txt-loader'
}
]
}
]
}
// ...
};
@前端进阶之旅: 代码已经复制到剪贴板
上述配置将该 Loader 应用于所有以 .txt 结尾的文件。在构建过程中,当遇到需要加载的 .txt 文件时,会调用 reverse-txt-loader 对文件内容进行反转处理,并将处理后的结果作为模块的输出。
请注意,在实际使用中,需要根据实际路径修改 loader 配置的路径,并将该 Loader 安装在项目中。
4 编写plugin
编写一个自定义的 Webpack 插件需要创建一个 JavaScript 类,并在类中实现指定的生命周期方法。下面是一个简单的示例,展示如何编写一个自定义的 Webpack 插件:
class MyPlugin {
constructor(options) {
// 在构造函数中可以接收插件的配置参数
this.options = options;
}
// Webpack 在安装插件时会自动调用 apply 方法,并将 compiler 对象传递进来
apply(compiler) {
// 在适当的生命周期钩子中挂载插件的功能
// 示例:在 emit 生命周期钩子中添加自定义的功能
compiler.hooks.emit.tap('MyPlugin', (compilation) => {
// compilation 对象包含了当前构建过程的各种信息
// 可以在这里执行一些自定义的操作
// 示例:向输出的文件中添加自定义的注释
const comment = this.options.comment || 'Custom comment';
for (const asset in compilation.assets) {
if (compilation.assets.hasOwnProperty(asset)) {
compilation.assets[asset].source = () => {
return `/* ${comment} */\n` + compilation.assets[asset].source();
};
}
}
});
}
}
@前端进阶之旅: 代码已经复制到剪贴板
以上是一个简单的插件示例,它在构建过程中的 emit 生命周期钩子中向输出的文件添加了自定义的注释。你可以根据实际需求在其他生命周期钩子中实现不同的功能。
要使用该插件,在 webpack 的配置文件中进行如下配置:
const MyPlugin = require('./path/to/MyPlugin');
module.exports = {
// ...
plugins: [
new MyPlugin({
comment: 'Custom comment',
}),
],
};
@前端进阶之旅: 代码已经复制到剪贴板
这样,当你运行 webpack 构建时,该插件就会被应用,并执行指定的功能。
需要注意的是,Webpack 的插件机制非常灵活,可以根据实际需求编写各种各样的插件。插件可以监听多个生命周期钩子,并在每个生命周期钩子中实现自定义的功能。详细的插件开发文档可以参考 Webpack 官方文档。
5 说一下webpack的一些plugin,怎么使用webpack对项目进行优化
Webpack 提供了许多插件(Plugins)来帮助优化项目构建和性能。下面列举一些常用的插件以及它们的作用:
构建优化插件:
ContextReplacementPlugin:用于限制某些模块的上下文,可以减少编译体积。IgnorePlugin:用于忽略特定的模块,减少打包体积。babel-plugin-import:用于按需加载和使用模块,减少打包体积。babel-plugin-transform-runtime:将代码中的公共部分提取到一个单独的模块中,减少打包体积。happypack、thread-loader:实现并行编译,加快构建速度。uglifyjs-webpack-plugin:通过并行压缩和缓存来加快代码压缩的速度。
性能优化插件:
Tree-shaking:通过静态分析代码,去除未使用的代码,减少打包体积。Scope Hoisting:将模块之间的关系进行静态分析,减少打包后的模块数量,提升代码执行速度。webpack-md5-plugin:根据文件内容生成 hash,实现缓存的更新机制。splitChunksPlugin:根据配置将代码拆分成多个块,实现按需加载和并行加载的效果。import()、require.ensure:动态导入模块,实现按需加载,提升页面加载速度。
除了使用这些插件,还可以通过配置 webpack 的其他参数来进一步优化项目,例如:
- 配置
devtool:选择合适的 Source Map 类型,既满足调试需求又不影响构建速度。 - 配置
output:使用chunkhash或contenthash生成文件名,实现长期缓存。 - 使用
cache-loader、hard-source-webpack-plugin、uglifyjs-webpack-plugin等插件开启缓存,加速再次构建。 - 使用
DllWebpackPlugin和DllReferencePlugin预编译公共模块,减少重复构建时间。
综合使用这些插件和优化策略,可以显著提升 webpack 项目的构建效率和性能。但是需要根据具体的项目需求和场景选择合适的插件和优化方法。
6 webpack Plugin 和 Loader 的区别
Loader用于对模块源码进行转换,将非 JavaScript 模块转换为 JavaScript 模块,或对模块进行预处理。它描述了webpack如何处理不同类型的文件,比如将 Sass 文件转换为 CSS 文件,或将ES6代码转换为ES5代码。Loader是针对单个文件的转换操作,通过配置rules来匹配文件并指定相应的LoaderPlugin用于扩展 webpack 的功能,解决Loader无法解决的问题。Plugin可以监听webpack构建过程中的事件,并在特定的时机执行相应的操作。它可以在打包优化、资源管理、环境变量注入等方面提供额外的功能。Plugin 的功能范围更广泛,可以修改webpack的内部行为,从而实现更复杂的构建需求。
总的来说,Loader 是用于处理模块源码的转换工具,而 Plugin 则是用于扩展 webpack 的功能,通过监听 webpack 构建过程中的事件来执行相应的操作。它们各自的作用和功能不同,但都可以用于优化和定制 webpack 的构建过程。在配置 webpack 时,我们可以通过配置 Loader 和 Plugin 来满足不同的需求,并实现对模块的转换和构建过程的定制化
7 tree shaking 的原理是什么
Tree shaking 的原理主要是基于静态分析的方式来实现无用代码的消除,从而减小最终打包生成的文件体积。它的工作原理可以简要概括如下:
- 采用
ES6 Module语法:Tree shaking只对ES6 Module语法进行静态分析和优化。ES6 Module的特点是可以进行静态分析,这意味着在编译阶段就能够确定模块之间的依赖关系。 - 静态分析模块依赖:在编译过程中,通过静态分析可以确定每个模块的依赖关系,以及模块中导出的函数、变量等信息。
- 标记未被引用的代码:在静态分析的过程中,会标记出那些未被其他模块引用的函数、变量和代码块。
- 消除未被引用的代码:在构建过程中,根据静态分析得到的标记信息,可以对未被引用的代码进行消除。这样,在最终生成的打包文件中,未被引用的代码将不会包含在内。
总结来说,Tree shaking 的核心思想是通过静态分析模块依赖关系,并标记和消除未被引用的代码。这样可以大大减小打包后的文件体积,提升应用的性能和加载速度。需要注意的是,Tree shaking 只对 ES6 Module 语法起作用,而对于 CommonJS 等其他模块系统则无法进行静态分析和优化。
8 common.js 和 es6 中模块引入的区别
CommonJS 是一种模块规范,最初被应用于 Nodejs,成为 Nodejs 的模块规范。运行在浏览器端的 JavaScript 由于也缺少类似的规范,在 ES6 出来之前,前端也实现了一套相同的模块规范 (例如:
AMD),用来对前端模块进行管理。自 ES6 起,引入了一套新的ES6 Module规范,在语言标准的层面上实现了模块功能,而且实现得相当简单,有望成为浏览器和服务器通用的模块解决方案。但目前浏览器对ES6 Module兼容还不太好,我们平时在Webpack中使用的export和import,会经过Babel转换为CommonJS规范
CommonJS 和 ES6 Module 在模块引入的方式和特性上有一些区别,主要包括以下几个方面:
- 输出方式:
CommonJS输出的是一个值的拷贝,而ES6 Module输出的是值的引用。在CommonJS中,模块导出的值是被复制的,即使导出模块后修改了模块内部的值,也不会影响导入模块的值。而在ES6 Module中,模块导出的值是引用关系,如果导出模块后修改了模块内部的值,会影响到导入模块的值 - 加载时机:
CommonJS模块是运行时加载,也就是在代码执行到导入模块的位置时才会加载模块并执行。而ES6 Module是编译时输出接口,也就是在代码编译阶段就会确定模块的依赖关系,并在运行前静态地解析模块的导入和导出 - 导出方式:
CommonJS采用的是module.exports导出,可以导出任意类型的值。ES6 Module采用的是export导出,只能导出具名的变量、函数、类等,而不能直接导出任意值 - 导入方式:
CommonJS使用require()来导入模块,可以使用动态语法,允许在条件语句中使用。ES6 Module使用import来导入模块,它是静态语法,只能写在模块的顶层,不能写在条件语句中 - this 指向:
CommonJS模块中的this指向当前模块的exports对象,而不是全局对象。ES6 Module中的this默认是undefined,在模块中直接使用this会报错
总的来说,
CommonJS主要用于服务器端的模块化开发,运行时加载,更适合动态加载模块,而ES6 Module是在语言层面上实现的模块化方案,静态编译,更适合在构建时进行模块依赖的静态分析和优化。在前端开发中,通常使用打包工具(如webpack)将ES6 Module转换为CommonJS或其他模块规范,以实现在浏览器环境中的兼容性。
9 babel原理
Babel 是一个 JavaScript 编译器。他把最新版的 javascript 编译成当下可以执行的版本,简言之,利用 babel 就可以让我们在当前的项目中随意的使用这些新最新的 es6,甚至 es7 的语法
ES6、7代码输入 ->babylon进行解析 -> 得到AST(抽象语法树)->plugin用babel-traverse对AST树进行遍历转译 ->得到新的AST树->用babel-generator通过AST树生成ES5代码
它的工作流程包括解析(parse)、转换(transform)和生成(generate)三个主要步骤
- 解析(parse):Babel 使用解析器(如
Babylon)将输入的 JavaScript 代码解析成抽象语法树(AST)。解析器将代码分析成语法结构,并生成对应的 AST,表示代码的抽象语法结构。这个阶段包括词法分析和语法分析。词法分析将源代码转换为一个个标记(tokens)的流,而语法分析则将这个标记流转换为 AST 的形式。 - 转换(transform):在转换阶段,Babel 使用插件(plugins)对 AST 进行遍历和转换。插件可以对 AST 进行增删改查的操作,可以根据需求对语法进行转换、代码优化等。Babel 的插件系统非常灵活,可以根据需要自定义插件或使用现有插件来进行代码转换。
- 生成(generate):在生成阶段,Babel 使用生成器(如
babel-generator)将经过转换的 AST 转换回字符串形式的 JavaScript 代码。生成器会深度优先遍历 AST,并根据 AST 的节点类型生成对应的代码字符串,最终将代码字符串输出。
通过以上三个步骤,Babel 实现了将最新版本的 JavaScript 代码转换为向后兼容的代码,使得开发者可以在当前环境中使用较新的 JavaScript 特性和语法。同时,Babel 还提供了一些常用的插件和预设(presets),以便开发者快速配置和使用常见的转换规则,如转换 ES6、ES7 语法、处理模块化、转换 JSX 等。
总的来说,Babel 的原理是通过解析、转换和生成的过程,将新版本的 JavaScript 代码转换为兼容旧环境的代码,使开发者能够在当前环境中使用较新的 JavaScript 特性和语法。
八、框架相关
1 Vue 响应式原理
整体思路是数据劫持+观察者模式
对象内部通过
defineReactive方法,使用Object.defineProperty将属性进行劫持(只会劫持已经存在的属性),数组则是通过重写数组方法来实现。当页面使用对应属性时,每个属性都拥有自己的dep属性,存放他所依赖的watcher(依赖收集),当属性变化后会通知自己对应的watcher去更新(派发更新)。
class Observer {
// 观测值
constructor(value) {
this.walk(value);
}
walk(data) {
// 对象上的所有属性依次进行观测
let keys = Object.keys(data);
for (let i = 0; i < keys.length; i++) {
let key = keys[i];
let value = data[key];
defineReactive(data, key, value);
}
}
}
// Object.defineProperty数据劫持核心 兼容性在ie9以及以上
function defineReactive(data, key, value) {
observe(value); // 递归关键
// --如果value还是一个对象会继续走一遍odefineReactive 层层遍历一直到value不是对象才停止
// 思考?如果Vue数据嵌套层级过深 >>性能会受影响
Object.defineProperty(data, key, {
get() {
console.log("获取值");
//需要做依赖收集过程 这里代码没写出来
return value;
},
set(newValue) {
if (newValue === value) return;
console.log("设置值");
//需要做派发更新过程 这里代码没写出来
value = newValue;
},
});
}
export function observe(value) {
// 如果传过来的是对象或者数组 进行属性劫持
if (
Object.prototype.toString.call(value) === "[object Object]" ||
Array.isArray(value)
) {
return new Observer(value);
}
}
@前端进阶之旅: 代码已经复制到剪贴板
2 Vue nextTick 原理
nextTick中的回调是在下次DOM更新循环结束之后执行的延迟回调。在修改数据之后立即使用这个方法,获取更新后的DOM。主要思路就是采用微任务优先的方式调用异步方法去执行nextTick包装的方法
let callbacks = [];
let pending = false;
function flushCallbacks() {
pending = false; //把标志还原为false
// 依次执行回调
for (let i = 0; i < callbacks.length; i++) {
callbacks[i]();
}
}
let timerFunc; //定义异步方法 采用优雅降级
if (typeof Promise !== "undefined") {
// 如果支持promise
const p = Promise.resolve();
timerFunc = () => {
p.then(flushCallbacks);
};
} else if (typeof MutationObserver !== "undefined") {
// MutationObserver 主要是监听dom变化 也是一个异步方法
let counter = 1;
const observer = new MutationObserver(flushCallbacks);
const textNode = document.createTextNode(String(counter));
observer.observe(textNode, {
characterData: true,
});
timerFunc = () => {
counter = (counter + 1) % 2;
textNode.data = String(counter);
};
} else if (typeof setImmediate !== "undefined") {
// 如果前面都不支持 判断setImmediate
timerFunc = () => {
setImmediate(flushCallbacks);
};
} else {
// 最后降级采用setTimeout
timerFunc = () => {
setTimeout(flushCallbacks, 0);
};
}
export function nextTick(cb) {
// 除了渲染watcher 还有用户自己手动调用的nextTick 一起被收集到数组
callbacks.push(cb);
if (!pending) {
// 如果多次调用nextTick 只会执行一次异步 等异步队列清空之后再把标志变为false
pending = true;
timerFunc();
}
}
@前端进阶之旅: 代码已经复制到剪贴板
3 Vue diff 原理

4 路由原理 history 和 hash 两种路由方式的特点
hash 模式
location.hash的值实际就是URL中#后面的东西 它的特点在于:hash虽然出现URL中,但不会被包含在HTTP请求中,对后端完全没有影响,因此改变 hash 不会重新加载页面- 可以为 hash 的改变添加监听事件
window.addEventListener("hashchange", funcRef, false);
@前端进阶之旅: 代码已经复制到剪贴板
- 每一次改变
hash(window.location.hash),都会在浏览器的访问历史中增加一个记录利用hash的以上特点,就可以来实现前端路由“更新视图但不重新请求页面”的功能了。 - 特点:兼容性好但是不美观
history 模式
利用了
HTML5 History Interface中新增的pushState()和replaceState()方法
- 这两个方法应用于浏览器的历史记录站,在当前已有的
back、forward、go的基础之上,它们提供了对历史记录进行修改的功能。这两个方法有个共同的特点:当调用他们修改浏览器历史记录栈后,虽然当前URL改变了,但浏览器不会刷新页面,这就为单页应用前端路由“更新视图但不重新请求页面”提供了基础 - 特点:虽然美观,但是刷新会出现
404需要后端进行配置
九、编程题相关
1 写一个通用的事件侦听器函数
// event(事件)工具集,来源:github.com/markyun
markyun.Event = {
// 视能力分别使用dom0||dom2||IE方式 来绑定事件
// 参数: 操作的元素,事件名称 ,事件处理程序
addEvent : function(element, type, handler) {
if (element.addEventListener) {
//事件类型、需要执行的函数、是否捕捉
element.addEventListener(type, handler, false);
} else if (element.attachEvent) {
element.attachEvent('on' + type, function() {
handler.call(element);
});
} else {
element['on' + type] = handler;
}
},
// 移除事件
removeEvent : function(element, type, handler) {
if (element.removeEventListener) {
element.removeEventListener(type, handler, false);
} else if (element.datachEvent) {
element.detachEvent('on' + type, handler);
} else {
element['on' + type] = null;
}
},
// 阻止事件 (主要是事件冒泡,因为IE不支持事件捕获)
stopPropagation : function(ev) {
if (ev.stopPropagation) {
ev.stopPropagation();
} else {
ev.cancelBubble = true;
}
},
// 取消事件的默认行为
preventDefault : function(event) {
if (event.preventDefault) {
event.preventDefault();
} else {
event.returnValue = false;
}
},
// 获取事件目标
getTarget : function(event) {
return event.target || event.srcElement;
}
@前端进阶之旅: 代码已经复制到剪贴板
2 如何判断一个对象是否为数组
function isArray(arg) {
return Array.isArray(arg) || (typeof arg === 'object' && Object.prototype.toString.call(arg) === '[object Array]');
}
@前端进阶之旅: 代码已经复制到剪贴板
首先使用 Array.isArray 方法判断 arg 是否为数组。如果是数组,则直接返回 true。否则,执行后面的类型判断逻辑。
这样,你可以使用 isArray 函数来判断一个对象是否为数组。例如:
console.log(isArray([])); // true
console.log(isArray({})); // false
console.log(isArray('')); // false
@前端进阶之旅: 代码已经复制到剪贴板
3 冒泡排序
它通过比较相邻的两个数,如果后一个数比前一个数小,则交换它们的位置。重复这个过程,直到所有的数都按照从小到大的顺序排列。
代码中使用了两层嵌套的循环。外层循环控制比较的轮数,内层循环用于比较相邻的两个数并交换位置。
下面代码添加了一个标志位来判断是否发生了交换,如果某一轮比较中没有发生交换,说明数组已经有序,可以提前结束循环。
var arr = [3, 1, 4, 6, 5, 7, 2];
function bubbleSort(arr) {
var len = arr.length;
for (var i = 0; i < len - 1; i++) {
var swapped = false; // 标志位,判断是否发生交换
for (var j = 0; j < len - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
var temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
swapped = true; // 发生了交换
}
}
if (!swapped) {
break; // 没有发生交换,提前结束循环
}
}
return arr;
}
console.log(bubbleSort(arr));
@前端进阶之旅: 代码已经复制到剪贴板
我们在内层循环中添加了一个标志位 swapped,初始值为 false。如果发生了交换,将 swapped 设置为 true。在每一轮外层循环结束后,检查 swapped 的值,如果为 false,说明数组已经有序,提前结束循环。
这样可以避免在已经排序完成的数组上进行不必要的比较,提高了冒泡排序的效率。
运行结果应为 [1, 2, 3, 4, 5, 6, 7]。
4 快速排序
采用二分法,取出中间数,数组每次和中间数比较,小的放到左边,大的放到右边
快速排序的思想很简单,整个排序过程只需要三步:
- 在数据集之中,找一个基准点
- 建立两个数组,分别存储左边和右边的数组
- 利用递归进行下次比较
- 快速排序的时间复杂度为
O(nlogn),是一种高效的排序算法
var arr = [3, 1, 4, 6, 5, 7, 2];
function quickSort(arr) {
if(arr.length == 0) {
return []; // 返回空数组
}
var cIndex = Math.floor(arr.length / 2);
var c = arr.splice(cIndex, 1);
var l = [];
var r = [];
for (var i = 0; i < arr.length; i++) {
if(arr[i] < c) {
l.push(arr[i]);
} else {
r.push(arr[i]);
}
}
return quickSort(l).concat(c, quickSort(r));
}
console.log(quickSort(arr));
@前端进阶之旅: 代码已经复制到剪贴板
5 编写一个方法 求一个字符串的字节长度
- 假设:一个英文字符占用一个字节,一个中文字符占用两个字节
function GetBytes(str){
var len = str.length;
var bytes = len;
for(var i=0; i<len; i++){
if (str.charCodeAt(i) > 255) bytes++;
}
return bytes;
}
alert(GetBytes("你好,as"));
@前端进阶之旅: 代码已经复制到剪贴板
6 bind的用法,以及如何实现bind的函数和需要注意的点
bind的作用与call和apply相同,区别是call和apply是立即调用函数,而bind是返回了一个函数,需要调用的时候再执行。
一个简单的bind函数实现如下
Function.prototype.bind = function(ctx) {
var fn = this;
return function() {
fn.apply(ctx, arguments);
};
};
@前端进阶之旅: 代码已经复制到剪贴板
bind方法用于创建一个新函数,并将其中的this值绑定到指定的对象。与call和apply不同,bind方法不会立即调用函数,而是返回一个绑定了指定this值的新函数,供以后调用。
它将原函数保存在fn变量中,然后返回了一个匿名函数。当新函数被调用时,它会使用fn.apply来设置函数的上下文(this值)为传入的ctx对象,并将参数通过arguments对象传递进去。
需要注意的是,bind方法还可以接受额外的参数,这些参数会在调用新函数时作为参数传递进去。修改代码,使其支持传递额外参数的实现如下:
Function.prototype.bind = function(ctx) {
var fn = this;
var args = Array.prototype.slice.call(arguments, 1); // 获取额外参数
return function() {
var combinedArgs = args.concat(Array.prototype.slice.call(arguments)); // 合并额外参数和新函数调用时的参数
fn.apply(ctx, combinedArgs);
};
};
@前端进阶之旅: 代码已经复制到剪贴板
另外,需要注意的是,使用原型链修改内置对象的方法可能会与其他代码发生冲突或不兼容。因此,在实际开发中,最好避免修改内置对象的原型方法,以免引起意想不到的问题。
7 实现一个函数clone
可以对
JavaScript中的5种主要的数据类型,包括Number、String、Object、Array、Boolean)进行值复
- 考察点1:对于基本数据类型和引用数据类型在内存中存放的是值还是指针这一区别是否清楚
- 考察点2:是否知道如何判断一个变量是什么类型的
- 考察点3:递归算法的设计
// 方法一:
Object.prototype.clone = function(){
var o = this.constructor === Array ? [] : {};
for(var e in this){
o[e] = typeof this[e] === "object" ? this[e].clone() : this[e];
}
return o;
}
@前端进阶之旅: 代码已经复制到剪贴板
//方法二:
/**
* 克隆一个对象
* @param Obj
* @returns
*/
function clone(Obj) {
var buf;
if (Obj instanceof Array) {
buf = []; //创建一个空的数组
var i = Obj.length;
while (i--) {
buf[i] = clone(Obj[i]);
}
return buf;
}else if (Obj instanceof Object){
buf = {}; //创建一个空对象
for (var k in Obj) { //为这个对象添加新的属性
buf[k] = clone(Obj[k]);
}
return buf;
}else{ //普通变量直接赋值
return Obj;
}
}
@前端进阶之旅: 代码已经复制到剪贴板
这里提供了两种方法来实现对象的克隆(clone)。
- 方法一使用了原型链的方式,在
Object.prototype上添加了一个名为clone的方法。该方法可以克隆一个对象,对于数组类型则创建一个空数组,对于对象类型则创建一个空对象,并递归地复制属性值。 - 方法二是一个独立的函数
clone,通过判断对象的类型来进行不同的处理。如果是数组类型,则创建一个空数组,并递归地克隆数组的每个元素;如果是对象类型,则创建一个空对象,并递归地克隆对象的每个属性;对于其他类型的变量,直接返回该变量。 - 这两种方法都使用了递归算法,通过遍历对象的属性,并根据属性的类型进行复制操作,从而实现对象的克隆。需要注意的是,在使用递归算法时,要注意处理循环引用的情况,以避免进入无限循环。
在实际开发中,可以根据需要选择适合的方法来实现对象的克隆。同时,还可以使用现代的深拷贝工具库,如lodash、underscore等,来实现更复杂的对象克隆操作。
8 下面这个ul,如何点击每一列的时候alert其index
考察闭包
<ul id=”test”>
<li>这是第一条</li>
<li>这是第二条</li>
<li>这是第三条</li>
</ul>
@前端进阶之旅: 代码已经复制到剪贴板
// 方法一:
var lis=document.getElementById('2223').getElementsByTagName('li');
for(var i=0;i<3;i++)
{
lis[i].index=i;
lis[i].onclick=function(){
alert(this.index);
}
//方法二:
var lis=document.getElementById('2223').getElementsByTagName('li');
for(var i=0;i<3;i++){
lis[i].index=i;
lis[i].onclick=(function(a){
return function() {
alert(a);
}
})(i);
}
@前端进阶之旅: 代码已经复制到剪贴板
9 定义一个log方法,让它可以代理console.log的方法
// 可行的方法一:
function log(msg) {
console.log(msg);
}
log("hello world!") // hello world!
@前端进阶之旅: 代码已经复制到剪贴板
如果要传入多个参数呢?显然上面的方法不能满足要求,所以更好的方法是:
function log(){
console.log.apply(console, arguments);
};
@前端进阶之旅: 代码已经复制到剪贴板
10 输出今天的日期
以
YYYY-MM-DD的方式,比如今天是2014年9月26日,则输出2014-09-26
var d = new Date();
// 获取年,getFullYear()返回4位的数字
var year = d.getFullYear();
// 获取月,月份比较特殊,0是1月,11是12月
var month = d.getMonth() + 1;
// 变成两位
month = month < 10 ? '0' + month : month;
// 获取日
var day = d.getDate();
day = day < 10 ? '0' + day : day;
alert(year + '-' + month + '-' + day);
@前端进阶之旅: 代码已经复制到剪贴板
除了上述代码中使用Date对象的方法外,还有其他方式可以获取今天的日期并输出。
一种常见的方式是使用toLocaleDateString()方法,该方法可以返回表示日期的字符串。可以通过传递适当的选项来指定所需的日期格式。
以下是使用toLocaleDateString()方法获取今天的日期的示例代码:
var today = new Date();
var options = { year: 'numeric', month: '2-digit', day: '2-digit' };
var formattedDate = today.toLocaleDateString('en-US', options);
console.log(formattedDate);
@前端进阶之旅: 代码已经复制到剪贴板
在上述代码中,首先创建一个Date对象表示今天的日期。
然后,定义一个选项对象options,其中指定了年份、月份和日期的格式。
最后,使用toLocaleDateString()方法将日期对象转换为指定格式的字符串,并将其赋值给formattedDate变量。
通过console.log()函数输出formattedDate,即可得到以YYYY-MM-DD的格式表示的今天的日期。
这种方法的优点是可以根据需求更灵活地定制日期的格式,适用于不同的地区和语言设置。
11 用js实现随机选取10–100之间的10个数字,存入一个数组,并排序
var iArray = [];
funtion getRandom(istart, iend){
var iChoice = istart - iend +1;
return Math.floor(Math.random() * iChoice + istart;
}
for(var i=0; i<10; i++){
iArray.push(getRandom(10,100));
}
iArray.sort();
@前端进阶之旅: 代码已经复制到剪贴板
12 写一段JS程序提取URL中的各个GET参数
有这样一个
URL:http://item.taobao.com/item.htm?a=1&b=2&c=&d=xxx&e,请写一段JS程序提取URL中的各个GET参数(参数名和参数个数不确定),将其按key-value形式返回到一个json结构中,如{a:'1', b:'2', c:'', d:'xxx', e:undefined}
function serilizeUrl(url) {
var result = {};
url = url.split("?")[1];
var map = url.split("&");
for(var i = 0, len = map.length; i < len; i++) {
result[map[i].split("=")[0]] = map[i].split("=")[1];
}
return result;
}
@前端进阶之旅: 代码已经复制到剪贴板
13 写一个function,清除字符串前后的空格
使用自带接口
trim(),考虑兼容性:
if (!String.prototype.trim) {
String.prototype.trim = function() {
return this.replace(/^\s+/, "").replace(/\s+$/,"");
}
}
@前端进阶之旅: 代码已经复制到剪贴板
// test the function
var str = " \t\n test string ".trim();
alert(str == "test string"); // alerts "true"
@前端进阶之旅: 代码已经复制到剪贴板
14 实现每隔一秒钟输出1,2,3…数字
for(var i=0;i<10;i++){
(function(j){
setTimeout(function(){
console.log(j+1)
},j*1000)
})(i)
}
@前端进阶之旅: 代码已经复制到剪贴板
在循环中,立即执行函数被用作一个闭包,用于保存每次循环中的i的值。这是为了避免在setTimeout函数中使用的回调函数在执行时捕获到的是循环结束后的i的值。
setTimeout函数用于设置一个定时器,它接受两个参数:回调函数和延迟时间(以毫秒为单位)。在每次循环中,通过将j*1000作为延迟时间,实现每隔一秒钟输出数字的效果。回调函数输出的数字为j+1,因为j从0开始。
通过这种方式,可以确保每隔一秒钟输出1, 2, 3...的数字。每个数字的输出时间间隔为一秒。
15 实现一个函数,判断输入是不是回文字符串
function run(input) {
if (typeof input !== 'string') return false;
return input.split('').reverse().join('') === input;
}
@前端进阶之旅: 代码已经复制到剪贴板
16 数组扁平化处理
实现一个
flatten方法,使得输入一个数组,该数组里面的元素也可以是数组,该方法会输出一个扁平化的数组
function flatten(arr){
return arr.reduce(function(prev,item){
return prev.concat(Array.isArray(item)?flatten(item):item);
},[]);
}
@前端进阶之旅: 代码已经复制到剪贴板
除了使用reduce方法,还可以使用递归和ES6的扩展运算符等方式来实现数组的扁平化处理。
- 递归方式:
function flatten(arr) {
var result = [];
arr.forEach(function(item) {
if (Array.isArray(item)) {
result = result.concat(flatten(item));
} else {
result.push(item);
}
});
return result;
}
@前端进阶之旅: 代码已经复制到剪贴板
- 使用ES6的扩展运算符:
function flatten(arr) {
while (arr.some(Array.isArray)) {
arr = [].concat(...arr);
}
return arr;
}
@前端进阶之旅: 代码已经复制到剪贴板
这些方法都可以将多层嵌套的数组扁平化成一个一维数组。使用递归方法时,通过遍历数组的每个元素,如果元素是数组,则递归调用扁平化函数;如果元素不是数组,则直接添加到结果数组中。使用ES6的扩展运算符时,通过不断地展开数组中的每个元素,直到所有元素都不再是数组为止。
17 实现一个函数clone,可以对JavaScript中的5种主要的数据类型(包括Number、String、Object、Array、Boolean)进行值复制
Object.prototype.clone = function(){
var o = this.constructor === Array ? [] : {};
for(var e in this){
o[e] = typeof this[e] === "object" ? this[e].clone() : this[e];
}
return o;
}
@前端进阶之旅: 代码已经复制到剪贴板
18 手写 promise.all 和 race(京东)
//静态方法
static all(promiseArr) {
let result = [];
//声明一个计数器 每一个promise返回就加一
let count = 0;
return new Mypromise((resolve, reject) => {
for (let i = 0; i < promiseArr.length; i++) {
//这里用 Promise.resolve包装一下 防止不是Promise类型传进来
Promise.resolve(promiseArr[i]).then(
(res) => {
//这里不能直接push数组 因为要控制顺序一一对应(感谢评论区指正)
result[i] = res;
count++;
//只有全部的promise执行成功之后才resolve出去
if (count === promiseArr.length) {
resolve(result);
}
},
(err) => {
reject(err);
}
);
}
});
}
//静态方法
static race(promiseArr) {
return new Mypromise((resolve, reject) => {
for (let i = 0; i < promiseArr.length; i++) {
Promise.resolve(promiseArr[i]).then(
(res) => {
//promise数组只要有任何一个promise 状态变更 就可以返回
resolve(res);
},
(err) => {
reject(err);
}
);
}
});
}
}
@前端进阶之旅: 代码已经复制到剪贴板
19 手写-实现一个寄生组合继承
function Parent(name) {
this.name = name;
this.say = () => {
console.log(111);
};
}
Parent.prototype.play = () => {
console.log(222);
};
function Children(name) {
Parent.call(this);
this.name = name;
}
Children.prototype = Object.create(Parent.prototype);
Children.prototype.constructor = Children;
let child = new Children("111");
console.log(child.name);
child.say();
child.play();
@前端进阶之旅: 代码已经复制到剪贴板
20 手写-new 操作符
function myNew(fn, ...args) {
let obj = Object.create(fn.prototype);
let res = fn.call(obj, ...args);
if (res && (typeof res === "object" || typeof res === "function")) {
return res;
}
return obj;
}
@前端进阶之旅: 代码已经复制到剪贴板
// 用法如下:
function Person(name, age) {
this.name = name;
this.age = age;
}
Person.prototype.say = function() {
console.log(this.age);
};
let p1 = myNew(Person, "lihua", 18);
console.log(p1.name);
console.log(p1);
p1.say();
@前端进阶之旅: 代码已经复制到剪贴板
21 手写-setTimeout 模拟实现 setInterval(阿里)
function mySetInterval(fn, time = 1000) {
let timer = null,
isClear = false;
function interval() {
if (isClear) {
isClear = false;
clearTimeout(timer);
return;
}
fn();
timer = setTimeout(interval, time);
}
timer = setTimeout(interval, time);
return () => {
isClear = true;
};
}
@前端进阶之旅: 代码已经复制到剪贴板
- 函数内部定义了一个timer变量和一个isClear变量,timer用于保存setTimeout的返回值,isClear用于标记是否需要清除定时器。
- interval函数是核心的定时执行函数,它会在每个时间间隔内执行一次回调函数fn。在每次执行回调函数之前,会检查isClear的值,如果为true,表示需要清除定时器,此时会调用clearTimeout清除定时器并直接返回。否则,会执行回调函数fn,然后通过setTimeout设置下一个定时执行。
- 在调用mySetInterval函数时,会立即执行一次interval函数,并通过setTimeout设置下一次的定时执行。同时,返回一个函数,调用该函数可以手动清除定时器。
- 需要注意的是,模拟实现的mySetInterval函数在执行回调函数时是通过setTimeout实现的,因此会存在一定的延迟。实际上,使用setInterval能更准确地控制时间间隔,因为setInterval会尽可能保持固定的间隔时间。而使用setTimeout实现的mySetInterval函数可能会存在一些累积的误差。
// 测试
let a = mySettimeout(() => {
console.log(111);
}, 1000)
let cancel = mySettimeout(() => {
console.log(222)
}, 1000)
cancel()
@前端进阶之旅: 代码已经复制到剪贴板
22 手写-发布订阅模式(字节)
class EventEmitter {
constructor() {
this.events = {};
}
// 实现订阅
on(type, callBack) {
if (!this.events[type]) {
this.events[type] = [callBack];
} else {
this.events[type].push(callBack);
}
}
// 删除订阅
off(type, callBack) {
if (!this.events[type]) return;
this.events[type] = this.events[type].filter((item) => {
return item !== callBack;
});
}
// 只执行一次订阅事件
once(type, callBack) {
function fn() {
callBack();
this.off(type, fn);
}
this.on(type, fn);
}
// 触发事件
emit(type, ...rest) {
this.events[type] &&
this.events[type].forEach((fn) => fn.apply(this, rest));
}
}
@前端进阶之旅: 代码已经复制到剪贴板
// 使用如下
const event = new EventEmitter();
const handle = (...rest) => {
console.log(rest);
};
event.on("click", handle);
event.emit("click", 1, 2, 3, 4);
event.off("click", handle);
event.emit("click", 1, 2);
event.once("dbClick", () => {
console.log(123456);
});
event.emit("dbClick");
event.emit("dbClick");
@前端进阶之旅: 代码已经复制到剪贴板
23 手写-防抖节流(京东)
// 防抖
function debounce(fn, delay = 300) {
//默认300毫秒
let timer;
return function () {
const args = arguments;
if (timer) {
clearTimeout(timer);
}
timer = setTimeout(() => {
fn.apply(this, args); // 改变this指向为调用debounce所指的对象
}, delay);
};
}
@前端进阶之旅: 代码已经复制到剪贴板
// 测试
window.addEventListener(
"scroll",
debounce(() => {
console.log(111);
}, 1000)
);
// 节流
// 设置一个标志
function throttle(fn, delay) {
let flag = true;
return () => {
if (!flag) return;
flag = false;
timer = setTimeout(() => {
fn();
flag = true;
}, delay);
};
}
window.addEventListener(
"scroll",
throttle(() => {
console.log(111);
}, 1000)
);
@前端进阶之旅: 代码已经复制到剪贴板
24 将虚拟 Dom 转化为真实 Dom(类似的递归题-必考)
{
tag: 'DIV',
attrs:{
id:'app'
},
children: [
{
tag: 'SPAN',
children: [
{ tag: 'A', children: [] }
]
},
{
tag: 'SPAN',
children: [
{ tag: 'A', children: [] },
{ tag: 'A', children: [] }
]
}
]
}
@前端进阶之旅: 代码已经复制到剪贴板
把上面的虚拟Dom转化成下方真实Dom
<div id="app">
<span>
<a></a>
</span>
<span>
<a></a>
<a></a>
</span>
</div>
@前端进阶之旅: 代码已经复制到剪贴板
答案
// 真正的渲染函数
function _render(vnode) {
// 如果是数字类型转化为字符串
if (typeof vnode === "number") {
vnode = String(vnode);
}
// 字符串类型直接就是文本节点
if (typeof vnode === "string") {
return document.createTextNode(vnode);
}
// 普通DOM
const dom = document.createElement(vnode.tag);
if (vnode.attrs) {
// 遍历属性
Object.keys(vnode.attrs).forEach((key) => {
const value = vnode.attrs[key];
dom.setAttribute(key, value);
});
}
// 子数组进行递归操作 这一步是关键
vnode.children.forEach((child) => dom.appendChild(_render(child)));
return dom;
}
@前端进阶之旅: 代码已经复制到剪贴板
25 手写-实现一个对象的 flatten 方法(阿里)
题目描述
const obj = {
a: {
b: 1,
c: 2,
d: {e: 5}
},
b: [1, 3, {a: 2, b: 3}],
c: 3
}
flatten(obj) // 结果返回如下
// {
// 'a.b': 1,
// 'a.c': 2,
// 'a.d.e': 5,
// 'b[0]': 1,
// 'b[1]': 3,
// 'b[2].a': 2,
// 'b[2].b': 3
// c: 3
// }
@前端进阶之旅: 代码已经复制到剪贴板
答案
function isObject(val) {
return typeof val === "object" && val !== null;
}
function flatten(obj) {
if (!isObject(obj)) {
return;
}
let res = {};
const dfs = (cur, prefix) => {
if (isObject(cur)) {
if (Array.isArray(cur)) {
cur.forEach((item, index) => {
dfs(item, `${prefix}[${index}]`);
});
} else {
for (let k in cur) {
dfs(cur[k], `${prefix}${prefix ? "." : ""}${k}`);
}
}
} else {
res[prefix] = cur;
}
};
dfs(obj, "");
return res;
}
flatten();
@前端进阶之旅: 代码已经复制到剪贴板
26 手写-判断括号字符串是否有效(小米)
题目描述
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
示例 1:
输入:s = "()"
输出:true
示例 2:
输入:s = "()[]{}"
输出:true
示例 3:
输入:s = "(]"
输出:false
@前端进阶之旅: 代码已经复制到剪贴板
答案
const isValid = function (s) {
if (s.length % 2 === 1) {
return false;
}
const regObj = {
"{": "}",
"(": ")",
"[": "]",
};
let stack = [];
for (let i = 0; i < s.length; i++) {
if (s[i] === "{" || s[i] === "(" || s[i] === "[") {
stack.push(s[i]);
} else {
const cur = stack.pop();
if (s[i] !== regObj[cur]) {
return false;
}
}
}
if (stack.length) {
return false;
}
return true;
};
@前端进阶之旅: 代码已经复制到剪贴板
27 手写-查找数组公共前缀(美团)
题目描述
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入:strs = ["flower","flow","flight"]
输出:"fl"
示例 2:
输入:strs = ["dog","racecar","car"]
输出:""
解释:输入不存在公共前缀。
@前端进阶之旅: 代码已经复制到剪贴板
答案
const longestCommonPrefix = function (strs) {
const str = strs[0];
let index = 0;
while (index < str.length) {
const strCur = str.slice(0, index + 1);
for (let i = 0; i < strs.length; i++) {
if (!strs[i] || !strs[i].startsWith(strCur)) {
return str.slice(0, index);
}
}
index++;
}
return str;
};
@前端进阶之旅: 代码已经复制到剪贴板
28 手写-字符串最长的不重复子串
题目描述
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
示例 4:
输入: s = ""
输出: 0
@前端进阶之旅: 代码已经复制到剪贴板
答案
const lengthOfLongestSubstring = function (s) {
if (s.length === 0) {
return 0;
}
let left = 0;
let right = 1;
let max = 0;
while (right <= s.length) {
let lr = s.slice(left, right);
const index = lr.indexOf(s[right]);
if (index > -1) {
left = index + left + 1;
} else {
lr = s.slice(left, right + 1);
max = Math.max(max, lr.length);
}
right++;
}
return max;
};
@前端进阶之旅: 代码已经复制到剪贴板
十、前端综合问题
1 谈谈你对重构的理解
重构是指在不改变外部行为的前提下,对代码、结构、布局或者设计进行优化和改进的过程。在前端开发中,重构通常指对网站或应用程序的前端部分进行优化和改造,以提升性能、可维护性和用户体验。
对于传统的网站来说,重构可以包括以下方面的优化:
- 结构优化:将使用表格布局的页面改为使用DIV+CSS布局,使页面结构更加语义化、清晰,并提高页面的可读性和维护性。
- 兼容性优化:将网站的前端代码和样式进行调整,使其能够兼容现代浏览器,并修复一些在旧版浏览器中存在的兼容性问题,提升用户体验和页面的可访问性。
- 移动优化:针对移动设备的特点和要求,对网站进行优化,如响应式设计或者针对移动设备的单独样式和布局,以提供更好的移动端用户体验。
- SEO优化:通过优化网站的HTML结构、标签使用、关键词等方面,提升网站在搜索引擎中的排名和可见性,从而增加网站的流量和曝光度。
重构的目标是改进现有代码和结构,使其更加高效、可维护和可扩展,同时保持网站的功能和外观不变。通过重构,可以提升网站的性能和用户体验,减少代码冗余,改善代码质量,并为后续的功能扩展和维护提供更好的基础。
2 什么样的前端代码是好的
好的前端代码具有以下特点:
- 可读性高:代码结构清晰,命名规范,注释清晰明了,易于理解和维护。
- 高复用性:代码组织良好,模块化设计,可通过复用组件、函数和样式来减少代码的冗余。
- 低耦合性:模块之间相互独立,减少模块之间的依赖,修改一个模块时不会对其他模块造成影响。
- 高性能:代码优化,减少不必要的计算和请求,合理使用缓存机制,提高页面加载速度和响应性能。
- 可维护性:代码结构清晰,逻辑简洁,易于调试和修改,便于团队协作和后续的功能迭代。
- 可靠性:代码经过严格的测试,处理各种异常情况,确保系统的稳定性和可靠性。
- 宽容性:能够适应不同浏览器和设备的差异,具有良好的兼容性,确保在各种环境下都能正常运行和展示。
- 安全性:防范常见的前端安全漏洞,保护用户信息和系统数据的安全。
此外,好的前端代码还应遵循设计模式的六大原则,包括单一职责原则、开放封闭原则、里氏替换原则、依赖倒置原则、接口隔离原则和迪米特法则,以提高代码的可扩展性、可维护性和可重用性。
综上所述,好的前端代码是可读性高、复用性强、低耦合性、高性能、可维护性和可靠性强的代码,同时符合设计模式的原则。
3 对前端工程师这个职位是怎么样理解的?它的前景会怎么样
前端工程师是负责开发和实现用户界面的程序员。他们在网站和应用程序开发过程中扮演着至关重要的角色,负责将设计师提供的视觉设计转化为具有交互性和响应性的前端界面。以下是我对前端工程师职位的理解:
- 实现界面交互:前端工程师通过编写HTML、CSS和JavaScript代码来实现用户界面的交互功能,包括按钮点击、表单提交、页面切换等。
- 提升用户体验:前端工程师致力于提供优秀的用户体验,通过优化页面加载速度、响应性能和用户界面设计,提升用户对产品的满意度和使用体验。
- 跨平台开发:随着Node.js的发展,前端工程师可以使用JavaScript开发跨平台的应用程序,如桌面应用、移动应用等,扩展了前端工程师的技术领域。
- 与团队合作:前端工程师需要与UI设计师、产品经理、后端工程师等团队成员密切合作,理解需求并与他们进行沟通,确保产品的需求能够得到有效地实现。
- 页面结构和重构:前端工程师负责设计和构建页面的结构,使其具备良好的可读性和可维护性。他们还会进行页面重构,以提高网站的性能和可访问性。
前端工程师的前景非常广阔。随着移动互联网和Web技术的快速发展,前端技术变得越来越重要。随着新的前端技术和框架的涌现,前端工程师需要不断学习和更新自己的技能,以适应行业的变化。同时,前端工程师对于提高用户体验和产品质量起着关键作用,因此在各个行业都有很高的需求。
随着移动应用、响应式设计和用户体验的重要性不断增加,前端工程师的职业前景将会持续看好。他们将继续在设计和开发过程中扮演重要角色,并为产品的成功做出贡献。
4 你觉得前端工程的价值体现在哪
前端工程的价值在于以下几个方面:
- 用户体验优化:前端工程师通过优化用户界面和交互设计,提供良好的用户体验,使用户能够轻松、高效地使用产品。他们关注用户界面的可用性、易用性和可访问性,确保用户能够舒适地与产品进行交互。
- 浏览器兼容性支持:不同的浏览器和设备有不同的特性和标准支持,前端工程师需要处理这些差异,确保产品在各种浏览器和设备上都能正常运行和呈现一致的用户体验。他们会进行浏览器兼容性测试和适配,以确保产品在不同环境下都能够良好运行。
- 性能优化:前端工程师负责优化前端代码和资源加载,以提高网页的加载速度和响应性能。他们会优化代码结构、压缩和合并文件、使用缓存机制等手段,从而减少页面加载时间,提高用户体验。
- 跨平台支持:随着移动设备和多平台应用的普及,前端工程师需要适应不同平台和设备的需求,开发跨平台应用或者响应式设计,使产品能够在不同平台上都具备良好的用户体验。
- 数据展示和接口支持:前端工程师负责展示后端数据,并通过与后端接口的交互实现数据的获取和处理。他们需要熟悉数据接口的调用和处理,确保数据的准确性和安全性,同时展示给用户的数据呈现清晰、易懂。
总之,前端工程的价值体现在提供良好的用户体验、保证产品在不同浏览器和平台上的兼容性、优化网页性能以及实现数据展示和接口支持等方面。他们为产品的成功和用户满意度做出了重要贡献。
5 平时如何管理你的项目
项目管理在前端开发中非常重要,以下是一些常见的项目管理实践:
- 确定项目全局约定:团队需要确定全局样式、编码规范、命名约定等,以保证代码的一致性和可维护性。
- 统一编码风格:团队成员需要遵循统一的编码风格,例如使用继承式的写法、单样式一行等,以提高代码的可读性和可理解性。
- 标注样式和模块:及时在代码中标注关键样式的编写人以及调用的地方,同时对页面进行标注,方便团队成员的理解和协作。
- 文件组织结构:将CSS和HTML文件分别放在不同的文件夹中,并统一命名规则,例如使用style.css作为CSS文件的命名。
- JS文件管理:将JS文件放在独立的文件夹中,并根据功能进行命名,使用英文翻译来描述其功能。
- 图片整合与优化:采用整合的方式使用图片,并使用适当的格式和优化策略,以减少文件大小和提升加载速度。
- 规范代码注释:对代码进行详细的注释,包括HTML、JS、CSS等,以提高代码的可读性和可维护性。
- 严格要求静态资源存放路径:规定静态资源的存放路径,遵循统一的文件夹结构,方便团队成员查找和管理资源文件。
- Git提交说明:在每次提交代码到版本控制系统时,要求团队成员填写清晰的提交说明,描述提交的内容和目的。
这些项目管理实践可以提高团队的协作效率、代码质量和项目可维护性,确保项目的顺利进行和成功交付。
6 组件封装
组件封装是前端开发中常用的技术手段,它的目的是为了实现代码的重用、提高开发效率和代码质量。在组件封装过程中,需要注意以下几个方面:
- 分析布局:首先需要对布局进行分析,确定组件的结构和样式。了解组件在不同场景下的表现形式和行为。
- 初步开发:根据布局的分析,开始进行组件的初步开发,包括HTML结构、CSS样式和基本的交互行为。
- 化繁为简:在初步开发的基础上,对组件进行优化和简化。去除冗余的代码,提取通用的样式和功能,确保组件的精简和高效。
- 组件抽象:在封装组件时,需要将组件的功能进行抽象,使其具有单一的职责和可复用性。将组件的各个部分分离,并提供适当的接口和配置项,使组件的使用更加灵活。
常用的操作包括:
- 使用合适的命名规范,保证组件的易读性和可维护性。
- 提供必要的文档和示例,方便其他开发人员使用和理解组件。
- 尽量降低组件与外部环境的耦合度,使其在不同的项目中都能够灵活使用。
- 考虑组件的可扩展性,使其能够适应未来的需求变化。
- 在开发过程中进行测试,确保组件的功能和性能达到预期。
通过良好的组件封装实践,可以提高代码的可维护性、可复用性和可测试性,加快开发速度,减少重复劳动,并提升整体的代码质量。
7 Web 前端开发的注意事项
在进行Web前端开发时,有一些注意事项可以帮助你提高开发效率和代码质量,以下是一些常见的注意事项:
- 特别设置meta标签viewport:通过设置viewport来适配不同设备的屏幕大小,确保网页在移动设备上有良好的显示效果。
- 使用百分比布局宽度:使用百分比来设置元素的宽度,结合
box-sizing: border-box;可以更好地适应不同屏幕大小。 - 使用rem作为计算单位:使用rem作为字体大小和元素尺寸的计算单位,rem相对于根节点html的字体大小,可以实现响应式的布局。
- 使用CSS3新特性:充分利用CSS3提供的新特性,如弹性盒模型、多列布局、媒体查询等,来简化布局和样式的编写,并提升用户体验。
- 多机型、多尺寸、多系统覆盖测试:在开发过程中,要充分考虑不同设备、不同屏幕尺寸和不同操作系统的兼容性,进行全面的测试,确保网页在各种环境下都能正常显示和工作。
此外,还有一些其他的注意事项:
- 优化网页性能:合理使用缓存、压缩资源、减少HTTP请求等方式来提升网页的加载速度和响应性能。
- 代码规范和可维护性:遵循一致的命名规范,使用合适的注释,拆分模块,保持代码的可读性和可维护性。
- 跨浏览器兼容性:测试和确保网页在主流浏览器(如Chrome、Firefox、Safari、Edge等)上都能正常运行。
- 安全性:注意防止常见的Web安全漏洞,如跨站脚本攻击(XSS)、跨站请求伪造(CSRF)等。
综上所述,注意这些事项可以帮助你开发出更高质量、更兼容性好的Web前端项目。
8 在设计 Web APP 时,应当遵循以下几点
在设计Web APP时,可以遵循以下几点来提升用户体验和页面效果:
- 简化不重要的动画/动效/图形文字样式:避免过度使用动画效果和视觉元素,保持页面简洁和清晰。只在必要的地方使用动画,确保其对用户体验有积极影响。
- 少用手势,避免与浏览器手势冲突:在设计交互时,尽量减少需要用户进行复杂手势操作的情况,避免与浏览器自带手势产生冲突。保持用户操作的简洁性和一致性。
- **减少页面内容和跳转次数:优化页面内容,保持简洁明了,尽量在当前页面展示所需的信息和功能,避免频繁的页面跳转。通过局部刷新、异步加载等技术手段来提升用户体验和页面加载速度。
- 增强Loading趣味性,增强页面主次关系:在加载过程中,可以设计有趣的加载动画或提示,提高用户的等待体验。同时,通过合适的页面布局和元素设计,突出页面的主要内容和功能,帮助用户更快地获取所需信息。
综上所述,遵循以上设计原则可以使Web APP在用户体验和页面效果方面更出色,提供更好的用户体验和用户参与感。
9 你怎么看待 Web App/hybrid App/Native App?(移动端前端 和 Web 前端区别?)
- Web App(HTML5):采用HTML5生存在浏览器中的应用,不需要下载安装
- 优点:开发成本低,迭代更新容易,不需用户升级,跨多个平台和终端
- 缺点:消息推送不够及时,支持图形和动画效果较差,功能使用限制(相机、GPS等)
- Hybrid App(混合开发):UI WebView,需要下载安装
- 优点:接近 Native App 的体验,部分支持离线功能
- 缺点:性能速度较慢,未知的部署时间,受限于技术尚不成熟
- Native App(原生开发):依托于操作系统,有很强的交互,需要用户下载安装使用
- 优点:用户体验完美,支持离线工作,可访问本地资源(通讯录,相册)
- 缺点:开发成本高(多系统),开发成本高(版本更新),需要应用商店的审核
移动端前端和Web前端在某些方面存在区别,如下所示:
- 开发环境和技术:移动端前端主要面向移动设备,需要熟悉移动端的开发环境和相关技术,如React Native、Flutter、Ionic等。而Web前端则主要面向浏览器,使用HTML、CSS、JavaScript等技术进行开发。
- 用户体验和交互:移动端前端需要更关注移动设备的特性和用户体验,例如触摸操作、手势识别、屏幕适配等,以提供更好的移动端交互体验。而Web前端则更注重页面的响应式设计和跨浏览器兼容性,以确保在不同浏览器和设备上的良好表现。
- 功能支持和限制:移动端前端开发可能会受到一些限制,如对设备资源的访问(相机、GPS等)、消息推送的限制等。而Web前端在功能上较为灵活,可以通过浏览器提供的API和插件来实现一些高级功能。
- 部署和更新:移动端前端需要通过应用商店进行发布和更新,需要经过审核和下载安装。而Web前端则可以直接通过URL访问,无需下载安装,便于部署和更新。
综上所述,移动端前端和Web前端在开发环境、用户体验、功能支持和部署等方面存在一些区别,开发者需要根据具体需求和平台选择合适的开发方式。同时,随着技术的不断发展,Hybrid App和Web App的出现使得移动端前端在一定程度上能够接近Native App的体验。
10 页面重构怎么操作
页面重构是对网站或应用程序进行优化和改进的过程,旨在提高页面性能、用户体验和代码可维护性。以下是页面重构的一般操作步骤:
- 分析和评估:首先,对现有页面进行全面的分析和评估。确定需要改进的方面,如页面加载速度、响应性能、代码结构等。
- 设计和规划:根据分析的结果,设计新的页面结构和布局,并规划重构的步骤和优化策略。确保重构后的页面能够提供更好的用户体验和性能。
- HTML重构:根据设计和规划,对HTML代码进行重构。优化标签的结构和语义化,使用合适的标签和属性,去除冗余代码和不必要的嵌套。
- CSS重构:对CSS样式进行重构,优化样式的选择器和属性的使用。遵循CSS规范,减少样式冗余,提高样式的复用性和可维护性。
- JavaScript重构:对JavaScript代码进行重构,优化代码的结构和逻辑。使用模块化开发和设计模式,减少全局变量的使用,提高代码的可读性和可维护性。
- 图片和资源优化:对页面中的图片和其他资源进行优化,压缩文件大小,提高加载速度。使用合适的图片格式,使用雪碧图或矢量图标减少HTTP请求。
- 响应式设计:考虑不同设备和屏幕尺寸的适配,使用响应式布局和媒体查询,确保页面在不同设备上具有良好的展示效果。
- 性能优化:优化页面的性能,包括减少HTTP请求,使用缓存机制,延迟加载和异步加载资源,合理使用CSS和JavaScript动画效果等。
- 测试和调试:在重构完成后,进行全面的测试和调试,确保页面在不同浏览器和设备上正常运行,并验证重构的效果和改进是否符合预期。
- 部署和上线:将重构后的页面部署到生产环境,并监控其性能和用户反馈。根据反馈和数据进行进一步的优化和改进。
页面重构是一个综合性的工作,需要综合考虑页面结构、样式、脚本和性能等方面的优化。通过合理的规划和操作,可以提升页面的质量、性能和用户体验。
十一、HR面相关
常见问题
- 自我介绍
- 自我介绍时,可以提及个人的背景、教育经历、工作经验和技能特长,突出与应聘职位相关的成就和能力。
- 面试完你还有什么问题要问的吗?
- 可以问一些之前提到的关于公司、部门、团队、项目以及职位的问题,以进一步了解潜在工作机会的细节和整体情况。
- 你有什么爱好?
- 可以提及个人的爱好和兴趣,例如读书、旅行、运动、音乐、社交活动等。这能够展示你的多元化和个人生活外的兴趣领域。
- 你最大的优点和缺点是什么?
- 在回答这个问题时,可以结合个人的实际情况,提及你在工作中表现出的优点,如团队合作、自我驱动、问题解决能力等,并且诚实地提及你认为的改进空间或缺点,并说明你在努力改进。
- 你为什么会选择这个行业、职位?
- 可以分享个人对该行业的兴趣和热爱,以及对相关技能和挑战的认可。强调个人与该行业、职位的契合度,以及追求个人发展和成长的动力。
- 你觉得你适合从事这个岗位吗?
- 回答时可以结合个人的技能、经验和特长,阐述为什么你认为自己是一个适合该岗位的人选,并举例说明相关的工作经历和成就。
- 你有什么职业规划?
- 可以分享个人在未来职业发展方面的目标和计划,例如短期和长期的职业规划、技能提升和学习的重点,以及希望在哪些方面取得进展和成就。
- 你对工资有什么要求?
- 在回答这个问题时,可以表达对市场薪资的了解,并根据个人的技能、经验和职位要求,提出一个合理的薪资范围,同时强调自己对工作内容和发展机会的重视。
- 如何看待前端开发?
- 可以表达对前端开发的重要性和价值的认识,以及对前端技术的兴趣和热情。可以提及前端在用户体验和界面设计方面的作用,以及前端与后端、设计团队的紧密合作,共同构建出优秀的产品和应用的重要性。
- 同时,可以强调前端开发的快速发展和不断演进的特点,需要不断学习和跟进最新的技术趋势和工具,以提供最佳的用户体验和响应式的界面设计。可以谈论自己对前端技术的持续学习和探索,并且强调自己愿意面对前端开发中的挑战和解决复杂问题的能力。
- 此外,可以提及前端开发在移动端和跨平台开发方面的重要性,以及在不同浏览器和设备上保持一致性的挑战。最重要的是,强调自己对前端开发的热情和对构建出优质用户体验的追求。
- 未来三到五年的规划是怎样的?
- 可以描述个人在未来三到五年内希望在职业发展方面达到的目标和计划。可以包括技术方面的深入学习、项目管理经验的积累、团队领导能力的提升等方面。
- 你的项目中技术难点是什么?遇到了什么问题?你是怎么解决的?
- 可以选择一个具体的项目经历,描述其中遇到的技术难点和问题,并详细说明你是如何面对挑战、寻找解决方案以及最终解决问题的经验和能力。
- 你们部门的开发流程是怎样的?
- 可以询问对方关于公司部门的开发流程、敏捷开发方法、版本控制工具等方面的情况,以了解公司在软件开发过程中的组织方式和团队协作模式。
- 你认为哪个项目做得最好?
- 可以选择一个你参与过或者熟悉的项目,介绍其中的亮点、成就和对团队和业务的贡献,突出个人在项目中的角色和贡献。
- 说下工作中你做过的一些性能优化处理。
- 可以提及个人在项目中对性能优化方面所做的工作,例如代码优化、资源压缩、缓存策略、异步加载等方法,以及通过性能测试和监控来评估和改进应用的性能。
- 最近在看哪些前端方面的书?
- 可以分享个人最近阅读的与前端开发相关的书籍,可以是关于新技术、前端框架、设计模式、性能优化等方面的书籍,以展示自己对前端领域的持续学习和进展。
- 平时是如何学习前端开发的?
- 可以描述个人平时学习前端开发的方法和途径,例如阅读技术博客、参与在线课程、实践项目、参加技术交流会议等,以展示自己的学习能力和对前端领域的持续关注。
- 你最有成就感的一件事
- 可以分享个人在工作或项目中取得的最有成就感的经历,强调个人的努力、贡献和团队合作所取得的成果,突出自己的成就和价值。
- 你为什么要离开前一家公司?
- 在回答这个问题时,可以提及离职的原因,例如寻求更好的职业发展机会、追求个人成长和挑战、寻找更适合自己的工作环境等。重点强调离职的决策是出于个人发展和职业目标的考虑。
- 你对加班的看法?
- 可以表达个人对加班的态度和看法。可以强调平衡工作和生活的重要性,同时指出愿意在关键时期适当加班以完成任务,但也强调重视工作效率和合理分配工作时间的重要性。
- 你希望通过这份工作获得什么?
- 可以说明个人对这份工作的期望和目标,例如获取更丰富的经验和技能、发展个人的专业能力、与优秀的团队合作、为公司的成功做出贡献等。重点强调自己对工作的积极态度和对职位的热情。
请注意,以上只是一些常见问题的示例回答,具体回答应根据个人实际情况进行调整和提炼,以展现个人的优势、能力和适应性。同时,回答问题时要真实、坦诚,与面试官进行积极互动,展现自己的价值和潜力。
前端常见面试流程

最后一个问题:面试官问,你想了解什么(面试一定要问这几个问题)
当面试官问到你有什么想了解的问题时,以下是一些问题可以提出:
- 关于部门和业务:
- 可以请面试官介绍一下该部门所负责的产品和业务领域,了解其在行业中的地位和竞争优势。
- 询问产品的用户规模和市场份额,以了解产品的受欢迎程度和发展潜力。
- 关于团队和角色:
- 询问部门的规模和组成,包括团队人数和各个角色的分布,以了解团队的规模和组织结构。
- 可以问一下团队中的协作方式和沟通流程,以了解团队的工作氛围和协作效率。
- 关于技术栈和项目:
- 可以请面试官介绍一下当前项目所使用的技术栈和开发工具,了解技术栈的现状和是否与自己的技术背景匹配。
- 询问有关技术团队的技术发展和创新方向,以了解团队在技术上的前瞻性和成长空间。
这些问题可以帮助你更好地了解潜在工作机会的方方面面,包括产品、团队和技术等关键要素。同时,通过提出这些问题,你还能展现出你对公司和职位的兴趣,并显示出你对细节和整体情况的关注。
你觉得你有哪些不足之处
- 我觉得自己在xx方面存在不足(不足限制在技术上聊,不要谈其他容易掉HR的坑里)
- 但我已意识到并开始学习
- 我估计在xx时间把这块给补齐
要限定一个范围
- 技术方面的
- 非核心技术栈的,即有不足也无大碍
- 些容易弥补的,后面才能“翻身”
错误的示范
- 我爱睡懒觉、总是迟到 —— 非技术方面
- 我自学的 Vue ,但还没有实践过 —— 核心技术栈
- 我不懂 React —— 技术栈太大,不容易弥补
正确的示范
- 脚手架,我还在学习中,还不熟练
- nodejs 还需要继续深入学习
你觉得你最大的缺点是什么
当被问到自己最大的缺点时,可以使用以下策略来回答:
- 弱点与职业相关:提到一个与你当前从事的职业相关的弱点。例如,如果你是前端开发人员,可以说你在运维和部署方面的知识和经验相对不足;如果你是后端开发人员,可以提到对于炫酷的页面交互设计方面的熟悉度还有待提高。
- 突出学习态度:将你的缺点与积极的学习态度联系起来。举例来说,你可以说在过去的工作中,由于工作要求没有经常使用某个特定的技术栈,因此对该技术栈的理解还不够深入。但你强调自己的好学心态,并说明你主动购买相关书籍、观看教学视频,并利用业余时间积极学习和探索。
- 自我进步与分享:强调你在个人成长方面所做的努力和投入。提到每天下班后用一个小时的时间参与技术论坛(如掘金、CSDN等),阅读他人的文章,并与他们交流和分享自己的疑惑。强调通过与他人互动,共同进步,并逐渐增强自己在该领域的专业知识。
通过这种回答方式,你不仅能够坦诚地承认自己的缺点,还能够展示自己的学习能力和积极进取的态度,给面试官留下积极向上的印象。
你还有其他公司的Offer吗?
在回答是否有其他公司的Offer时,可以使用以下方式:
- 确认有多个Offer:表示自己已经收到了多个工作机会的邀约,可以说有三四个已经确认过的Offer。但是,避免透露具体公司的名称,以避免违反保密约定或造成不必要的麻烦。
- 表示对本公司的意向:强调对本公司的兴趣和优先考虑。可以说,尽管有多个Offer,但本公司是你的首选,你对这里的工作环境、文化以及发展机会很感兴趣。如果薪资差距不大,你会倾向于选择本公司。
- 提及其他催促的Offer:透露有一两个Offer对你的决定比较急迫,希望本公司能够尽快给出结果。这样可以传达你对本公司的热忱,同时给予HR或招聘团队一些压力,加快决策的速度。
重要的是,保持真实和诚实,并且在回答时展现出对本公司的兴趣和积极性,但不要过于咄咄逼人或给人留下不专业的印象。
为什么从上一家公司离职?
在回答为什么离开上一家公司时,可以提及以下原因:
- 长时间通勤:可以说公司搬迁导致通勤时间变得过长,例如三个小时的通勤时间。这样的情况下,每天花费在路途上的时间过多,影响到了工作与生活的平衡。
- 工作与生活平衡:可以表达对工作与生活平衡的追求。指出在上一家公司由于长时间加班,没有足够的时间用于个人发展和充电,无法提高自己的技能和知识。这可能是导致你寻求一个更好的工作环境和更好的生活质量的原因之一。
- 进一步发展:强调你对个人职业发展的追求。指出你在上一家公司的成长空间有限,希望能够找到一个更有挑战性和发展机会的岗位。你希望能够在新的工作环境中学习和成长,并为公司做出更大的贡献。
- 其他因素:除了以上原因,还可以提及其他可能的因素,如公司文化不符合个人价值观、缺乏晋升机会或薪资待遇不合理等。但需要注意,避免过于负面或批评性的表达,以保持专业和积极的形象。
重要的是,在回答时保持真实性和诚实性,并强调你离开的原因与你目前的职业目标和对新公司的期望相符合。
如何看待加班(996)?
- 对于加班(996)这个话题,我的观点是将其分为紧急加班和长期加班两种情况,并采取不同的态度和应对方式。
- 首先,对于紧急加班,我理解在某些情况下,公司和团队可能面临紧迫的项目交付或突发的问题需要解决。在这种情况下,我愿意主动承担加班工作,牺牲自己的时间来帮助公司和团队完成任务。我认为这是每个公司都会遇到的情况,作为团队成员,我愿意以身作则,积极配合团队的需要。
- 然而,对于长期加班,我持有不同的观点。如果我个人长期加班,我会认为这是一个机会来磨练自己的技能,并提高工作效率。长期加班可能是因为时间管理不当、工作安排不合理或者缺乏高效的工作流程等原因造成的。在这种情况下,我会积极寻找解决问题的方式,如优化个人工作流程、学习和应用自动化工具、改进协作方式等,以提高工作效率并摆脱长期加班的状态。
- 如果是团队长期加班,我会尝试帮助团队找到问题所在,并提出改进方案。我会与团队成员一起探讨和实施高效的协作流程,引入适当的自动化工具和技术,以提高整个团队的工作效率。我认为通过团队的努力,可以摆脱长期加班的局面,使工作更加高效、有序,并确保成员的工作与生活平衡。
- 总的来说,我认为加班在某些情况下是不可避免的,但长期加班不应该成为常态。我会尽力提高个人和团队的工作效率,找到问题所在,并积极采取措施解决,以实现工作与生活的平衡。同时,我也鼓励团队成员之间的相互支持和合作,共同努力营造一个高效、有序的工作环境。
你对未来3-5年的职业规划
- 对于未来3-5年的职业规划,我已经认真考虑过,并且有一些明确的目标和计划。目前,我正处于职业发展的早期阶段,我希望能够在现有的岗位上不断提升自己,并逐步承担更高级别的责任和挑战。
- 从工作本身出发,我计划通过持续努力和学习,不断提高自己的技术能力和解决问题的能力。我将致力于出色完成本职工作,同时积极与团队合作,为团队的成功贡献我的力量。我希望能够带领团队的其他成员,共同创造更多的价值,并帮助团队扩大影响力,提升整个团队的表现。
- 除了在工作中表现出色,我也非常重视学习和个人成长。我会继续精进自己的领域知识,不断跟进行业的发展动态,并通过参加培训、研讨会等途径不断提升自己的专业能力。我也愿意与团队分享我的学习成果,帮助团队中的其他成员成长和发展。
- 总的来说,我的职业规划是在未来3-5年内通过不断学习和实践,成为在我的领域中具备丰富经验和卓越表现的专业人士。我希望能够在团队中发挥更大的作用,取得职业上的突破,并为公司的发展做出积极的贡献。
如何与HR谈薪资
与HR谈薪资时,可以采取一些策略和技巧来达到更好的结果。以下是一些建议:
- 先了解市场行情:在面试之前,可以调研该职位在市场上的薪资范围,以便有一个大致的参考标准。这样你就能更有理据地进行讨论。
- 引导HR给出薪资范围**:当HR问你期望的薪资时,你可以委婉地回答:“根据我的经验和技能,我期望能够获得与市场价值相符的薪资。贵公司对该职位的薪资范围是多少呢?”这样可以让HR先给出一个参考范围,为后续的讨论提供依据。
- 强调你的价值:在谈论薪资时,强调你在面试中展现出的能力和潜力,以及你对公司的价值和贡献。说明你具备的技能、经验和特长,并举例说明你如何在过去的工作中为公司创造了价值。这样可以增加谈判时争取更好薪资的机会。
- 谈论综合福利:薪资并不是唯一的关注点,还有其他福利待遇,如培训机会、晋升空间、灵活的工作时间等。在与HR谈判时,可以提及你对这些综合福利的重视,并尝试寻求一种综合福利与薪资相平衡的方案。 5.** 灵活性的回答**:在给出薪资期望时,可以给出一个范围而非具体数字,这样可以在一定程度上保留谈判的空间。例如:“根据我对市场的了解,我期望的薪资在X到Y之间,具体的数字可以根据公司对我的综合评估来确定。”
最重要的是要保持积极、开放的态度,并尊重双方的利益和限制。通过明确表达自己的期望和对公司的价值,与HR进行积极的讨论和协商,有助于达成一个双方都满意的薪资安排。